前言
参考:
- 《统计学习》—李航(蓝皮)
- 部分来自网络的内容(主要是liaohuiqiang的博客)
支持向量机(SVM)
非线性SVM与核技巧
核技巧
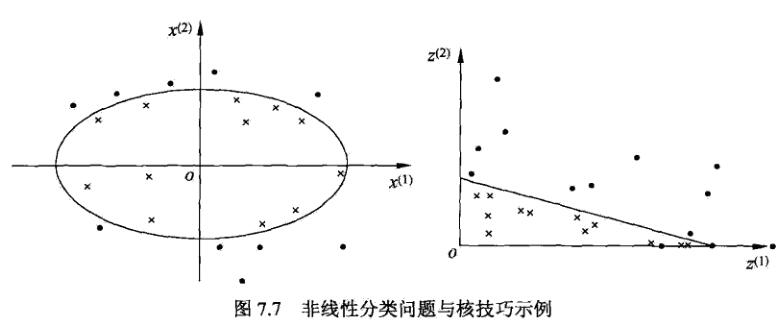
左图分类问题无法用直线(线性模型)将正负实例正确分开,但可以用一条椭圆曲线(非线性模型)将它们正确分开。
如果能用一个超曲面将正负例正确分开,则称这个问题为非线性可分问题。非线性问题往往不好求解,所以希望能用解线性分类问题的方法解决这个问题。所采取的方法是进行一个非线性变换,将非线性问题变换为线性问题。通过求解线性问题来求解原问题。
e.g.
设原空间为
::: align-center
X\in\mathbb{R}^2,x=(x^{(1)},x^{(2)})^T\in X
:::
新空间为
::: align-center
Z\in\mathbb{R}^2,x=(z^{(1)},z^{(2)})^T\in z
:::
我们定义从原空间到新空间的映射为
::: align-center
z=\phi(x)=((x^{(1)})^2,(x^{(2)})^2)^T
:::
那么对于上图,左图的椭圆\omega_1(x^{(1)})^2+\omega_2(x^{(2)})^2+b=0变成右图新空间的直线\omega_1z^{(1)}+\omega_2z^{(2)}+b=0
核技巧应用到SVM,基本想法是通过一个非线性变换将输入空间对应于一个特征空间,使得输入空间\mathbb{R}^n中的超曲面对应于特征空间\mathcal{H}的超平面。这样,分类问题的学习任务通过在特征空间中求解线性SVM就可以完成。
核函数与非线性SVM模型
核函数与正定核
设\mathcal{X}是输入空间,又设\mathcal{H}是特征空间,如果存在一个从\mathcal{X}到\mathcal{H}的映射\phi(x):\mathcal{X}\mapsto \mathcal{H},使得对于所有的x,z\in\mathcal{X}都有函数K(x,z)满足条件:
::: align-center
K(x,z)=\phi(x)\cdot \phi(z)
:::
则乘K(x,z)为核函数,\phi(x)为映射函数,等式左边的\phi(x)\cdot\phi(z)表示内积
核技巧的想法是,学习与预测中只定义核函数K(x,z),而不是显式的定义\phi(x),\phi(z),直接定义K(x,z)比较容易,而通过\phi(x),\phi(z)计算K(x,z)并不容易。特征空间\mathcal{H}一般是高维的,甚至是无穷维的。
对于给定的核K(x,z),特征空间\mathcal{H}和映射函数\phi的取法并不唯一,可以取不同的特征空间,即使在同一特征空间里也可以取不同映射。
函数K(x,z)满足什么条件才能称为核函数呢?通常所说的核函数就是正定核函数,下面给出正定核的定义:
设K:\mathcal{X}\times\mathcal{X}\mapsto\mathbb{R}是对称函数,则K(x,z)是正定核函数的充要条件是对任意x_i\in\mathcal{X},i=1,2,\cdots,m,K(x,z)对应的Gram矩阵
::: align-center
K=[K(x_i,x_j)]_{m\times m}
:::
是半正定矩阵
但对于一个具体函数K(x,z)来说,检验它是否为正定核函数并不容易,因为要求任意有限输入集\{x_1,x_2,\cdots,x_m\}证K对应的Gram矩阵是否为半正定。
核函数的性质有:
- 给定一个核函数K,对于a>0,aK也为核函数。
- 给定两个核函数K',K'',K'K''也为核函数。
- 对输入空间的任意实变函数f(x),K(x_1,x_2)=f(x_1)f(x_2)为核函数。
非线性SVM模型
注意到线性SVM的对偶问题中,无论是目标函数还是决策函数(分离超平面)都只涉及输入实例与实例之间的内积,在对偶问题(📌)中的内积x_i\cdot x_j可用K(x_i,x_j)=\phi(x_i)\cdot\phi(x_j)代替,此时对偶问题的目标函数为:
::: align-center
W(\alpha)=\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_jK(x_i,x_j)-\sum_{i=1}^N\alpha_i
:::
最后模型为:
::: align-center
f(x)=sign(\sum_{i=1}^N\alpha_i^*y_iK(x,x_i)+b^*)
:::
在新的特征空间里从训练样本中学习线性SVM。学习是隐式地在特征空间进行的,不需要显式地定义特征空间和映射函数。这样的技巧称为核技巧。当映射函数是非线性函数时,学习到的含有核函数的SVM是非线性分类模型。
在实际应用中,往往依赖领域知识直接选择核函数,核函数的有效性需要通过实验验证。
常用核函数
在实际问题中往往应用已有的核函数:
(1)多项式核函数(Polynormal Kernel Fuction)
::: align-center
K(x,z)=(x\cdot z+1)^p
:::
对应的支持向量机是一个p次多项式分类器。在此情形下,分类决策函数成为
::: align-center
f(x)=sign(\sum_{i=1}^N\alpha_i^*y_i(x_i\cdot x+1)^p+b^*)
:::
(2)高斯核函数(Gaussian Kernel Function)
::: align-center
K(x,z)=exp(-\frac{(||x-z||^2)}{2\sigma^2})
:::
对应的支持向量机是高斯径向基函数分类器。在此情形下,分类决策函数成为
::: align-center
f(x)=sign(\sum_{i=1}^N\alpha_i^*y_iexp(-\frac{(||x-z||^2)}{2\sigma^2})+b^*)
:::
(3)字符串核函数
核函数不仅可以定义在欧式空间上,还可以定义在离散数据的集合上。比如,字符串核是定义在字符串集合上的核函数。字符串核函数在文本分类,信息检索,生物信息等方面都有应用
序列最小最优化算法(SMO)
简介
SVM的学习问题可以形式化为求解凸二次规划问题。这样的凸二次规划问题具有全局最优解,并且有许多最优化算法可以用于这一问题的求解。但是当训练样本容易很大时,这些算法往往变得非常低效,以致无法使用。如何高效地实现SVM就成为一个重要问题。
序列最小优化算法(Sequential Minimal Optimization, SMO)是其中一种快速学习算法。可用于求解如下凸二次规划的对偶问题(💡):
::: align-center
\begin{aligned}
&\min_{\alpha}\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_jK(x_i,x_j)-\sum_{i=1}^N\alpha_i\\
&s.t.\space\sum_{i=1}^N\alpha_iy_i=0\\
&0\le\alpha_i\le C,i=1,2,\cdots,N
\end{aligned}
:::
问题中变量是拉格朗日乘子,一个变量\alpha_i对应于一个样本点(x_i,y_i),变量的总数等于训练样本容量N
SMO算法:SMO算法是一种启发式算法,基本思路是:如果所有变量的解都满足此最优化问题的KKT条件,那么解就得到了。否则,选择两个变量,固定其它变量,针对这两个变量构建一个二次规划问题。这个二次规划问题关于这两个变量的解应该更接近原始二次规划问题的解,因为这会使得原始二次规划问题的目标函数变得更小。重要的是,这时子问题可以通过解析方法求解,就可以大大提高计算速度。
子问题有两个变量,一个是违反KKT条件最严重的那个,另一个由约束条件自动确定。如此,SMO算法将原问题不断分解为子问题并对子问题求解,进而达到求解原问题的目的。
整个SMO算法包括两个部分:
- 求解两个变量二次规划的解析方法
- 选择变量的启发式方法。
两个变量二次规划的求解方法
假设选择的两个变量为\alpha_1,\alpha_2,其他变量\alpha_i(i=3,4,\cdots,N)是固定的,于是SMO最优化问题(💡)可以写成(📎):
::: align-center
\begin{aligned}
&\min_{\alpha_1,\alpha_2}W(\alpha_1,\alpha_2)\\
&=\frac{1}{2}K_{11}\alpha_1^2+\frac{1}{2}K_{22}\alpha_2^2+y_1y_2K_{12}\alpha_1\alpha_2-(\alpha_1+\alpha_2)\\
&+y_1\alpha_1\sum_{i=3}^Ny_i\alpha_iK_{i1}+y_2\alpha_2\sum_{i=3}^Ny_i\alpha_iK_{i2}\\
&s.t.\space y_1\alpha_1+y_2\alpha_2=-\sum_{i=3}^Ny_i\alpha_i=\zeta\\
&0\le\alpha_i\le C, i=1,2
\end{aligned}
:::
其中\zeta是常数,目标函数省略了不含\alpha_1,\alpha_2的常数项
由于只有两个变量,约束可以用二维空间中的图形表示:
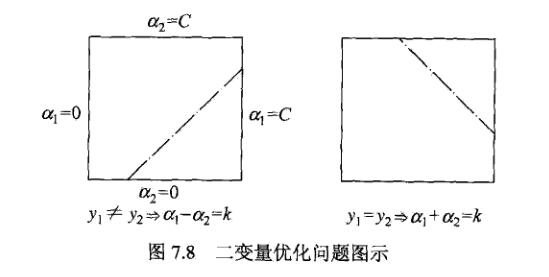
- 当y_1\ne y_2时,由上面问题的第一个约束条件容易得到\alpha_1-\alpha_2为某个常数k(因为y_1,y_2只可能取值\pm 1),所以解位于一条斜率为1的直线上,它平行于可行域[0,C]\times[0,C]的主对角线
- 同理当y_1=y_2时容易得解位于平行于可行域副对角线的直线上
假设(📎)的初始可行解为\alpha_1^{old},\alpha_2^{old}(一般初始化为0,0),最优解为\alpha_1^{new},\alpha_2^{new},并假设在沿着约束方向(对角线)未经剪辑(不考虑可行域边界)时\alpha_2的最优解为\alpha_2^{new,unc}
由于\alpha_2^{new}需要满足不等式条件约束,所以最优值\alpha_2^{new}的取值范围必须满足条件
::: align-center
L\le\alpha_2^{new}\le H
:::
其中L与H是\alpha_2^{new}所在对角线端点的界
如果y_1\ne y_2,则
::: align-center
L=\max(0,\alpha_2^{old}-\alpha_1^{old}),H=\min(C,C+\alpha_2^{old}-\alpha_1^{old})
:::
如果y_1=y_2,则
::: align-center
L=\max(0,\alpha_2^{old}+\alpha_1^{old}-C),H=\min(C,C+\alpha_2^{old}-\alpha_1^{old})
:::
注:这两条可以通过\alpha_1,\alpha_2在两种情况下的关系,和上面问题的最后一条不等式约束条件得到
e.g. 考虑y_1=y_2的情况,此时\alpha_1+\alpha_2=k\Rightarrow \alpha_1=k-\alpha_2
由不等式约束条件0\le \alpha_1\le C\Rightarrow k-C\le\alpha_2\le k,又因为\alpha_2本来就有0\le\alpha_2\le C,故取最大最小得到结果
先求沿着约束方向未经剪辑(即不考虑不等式可行域约束)时\alpha_2的最优解\alpha_2^{new,unc},然后再求剪辑后的\alpha_2的解\alpha_2^{new}。我们用定理来叙述这个结果,然后再加以证明。
为了叙述简单,记
::: align-center
\begin{aligned}
&g(x)=\sum_{i=1}^N\alpha_iy_iK(x_i,x)+b\\
&E_i=g(x_i)-y_i=\sum_{j=1}^N\alpha_jy_jK(x_j,x_i)+b-y_i
\end{aligned}
:::
当i=1,2时E_i为函数g(x)对输入x_i的预测值与真实输出y_i之差
定理:最优化问题(📎)沿着约束方向未经剪辑的解是
::: align-center
\alpha_2^{new,unc}=\alpha_2^{old}+\frac{y_2(E_1-E_2)}{\eta}
:::
其中
::: align-center
\eta=K_{11}+K_{12}-2K_{12}=||\phi(x_1)-\phi(x_2)||^2
:::
经剪辑后的\alpha_2的解为
::: align-center
\alpha_2^{new}=\left\{
\begin{matrix}
H & \alpha_2^{new,unc}>H\\
\alpha_2^{new,unc} & L\le\alpha_2^{new,unc}\le H\\
L & \alpha_2^{new,unc}
:::
由\alpha_2^{new}求得\alpha_1^{new}
::: align-center
\alpha_1^{new}=\alpha_1^{old}+y_1y_2(\alpha_2^{old}-\alpha_2^{new})
:::
证明:
引进记号
::: align-center
v_i=\sum_{j=3}^N\alpha_iy_iK(x_i,x_j)=g(x_i)-\sum_{j=2}^N\alpha_iy_iK(x_i,x_j)-b
:::
将目标函数写成
::: align-center
\begin{aligned}
&W(\alpha_1,\alpha_2)\\
&=\frac{1}{2}K_{11}\alpha_1^2+\frac{1}{2}K_{22}\alpha_2^2+y_1y_2K_{12}\alpha_1\alpha_2-(\alpha_1+\alpha_2)\\
&+y_1v_1\alpha_1+y_2v_2\alpha_2
\end{aligned}
:::
由y_1\alpha_1=\zeta -y_2\alpha_2及y_j^2=1,可将\alpha_1表示为:
::: align-center
\alpha_1=(\zeta-y_2\alpha_2)y_1
:::
代入上式,得到只含\alpha_2的目标函数
::: align-center
\begin{aligned}
&W(\alpha_2)\\
&=\frac{1}{2}K_{11}(\zeta -y_2\alpha_2)^2+\frac{1}{2}K_{22}\alpha_2^2+y_2K_{12}(\zeta-y_2\alpha_2)\alpha_2-(\zeta-y_2\alpha_2)y_1-\alpha_2\\
&+y_1v_1(\zeta-y_2\alpha_2)y_1+y_2v_2\alpha_2
\end{aligned}
:::
对\alpha_2求导数
::: align-center
\begin{aligned}
&\frac{\partial W}{\partial\alpha_2}=K_{11}\alpha_2+K_{22}\alpha_2-2K_{12}\alpha_2-K_{11}\zeta y_2+K_{12}\\
&+y_1y_2-1-y_2v_1+y_2v_2
\end{aligned}
:::
令其等于0,同时将\zeta=y_1\alpha_1^{old}+y_2\alpha_2^{old}和\eta=K_{11}+K_{22}-2K_{12}代入得\alpha_2^{new,unc},得证
变量的选择方法
SMO算法在每个子问题中选择两个变量优化,其中至少一个变量是违反KKT条件的。
(1)第一个变量的选择
SMO称选择第1个变量的过程为外层循环。外层循环在训练样本中选取违反KKT条件最严重的样本,并将其对应的变量作为第1个变量。具体地,检查训练样本点是否满足KKT条件(类似于上一篇线性SVM的文章中的KKT条件),即
::: align-center
\begin{aligned}
&\alpha_i=0\Leftrightarrow y_ig(x_i)\ge 1\\
&0<\alpha
:::
- 第一个中若\alpha_i=0,说明样本对分类边界没有影响,这个点是非支持向量,那么我们就需要保证他在间隔外侧,故y_ig(x_i)\ge 1
- 第二个中若0\le\alpha_i\le C,则由上一篇文章软支持向量的解释得到这个样本点应该是支持向量,且恰好落在间隔边界上,故y_ig(x_i)=1
- 第三个中若\alpha_i=C,则由上一篇文章软支持向量的解释得到这个样本点应该是支持向量,且在间隔内部,故y_ig(x_i)\le 1
检验过程中,外层循环首先遍历所有满足0<\alpha_i
(2)第二个变量的选择
SMO称选择第2个变量的过程为内层循环。选取的标准是希望\alpha_2有足够大的变化。由于\alpha_2^{new}是依赖于|E_1-E_2|的,为了加快计算速度,一种简单的做法是选择\alpha_2,使其对应的|E_1-E_2|最大。因为\alpha_1已定,E_1也确定了。如果E_1为正,那么选择最小的E_i作为E_2;如果E_1为负,那么选择最大的E_i作为E_2。为了节省计算事件,将所有E_i值保存在一个列表中。
在特殊情况下,如果内层训练通过以上方法选择的\alpha_2不能使目标函数有足够的下降,那么采用以下启发式规则继续选择\alpha_2:
遍历在间隔边界上的支持向量点,依次将其对应的变量作为使用,直到目标函数有足够的下降。若找不到合适的\alpha_2,那么遍历训练数据集;若仍找不到合适的\alpha_2,则放弃第1个\alpha_1,再通过外层训练寻求另外的\alpha_1
(3)计算阈值b和差值E_i
在每次完成两个变量的优化后,都要重新计算阈值b。
在每次完成两个变量的优化后,还需要更新对应的E_i值。
全部评论 (0)
暂无评论,快来抢沙发吧~