前言
参考:
- 《统计学习》—李航(蓝皮)
聚类的基本概念
聚类的基本概念包括:样本之间的距离或相似度,类或簇,类与类之间的距离
相似度或距离
简介
聚类的对象时观测数据,或样本集合。假设有n个样本,每个样本由m个属性的特征向量组成,样本集合可以用矩阵X表示
::: align-center
X=[x_{ij}]_{m\times n}=\begin{bmatrix}
x_{11} & x_{12} & \cdots & x_{13}\\
x_{21} & x_{22} & \cdots & x_{23} \\
\vdots & \vdots & & \vdots\\
x_{m1} & x_{m2} & \cdots & x_{mn}
\end{bmatrix}
:::
矩阵的第j列表示第j个样本,j=1,2,\cdots,n;第i行表示第i个属性,i=1,2,\cdots,m;j=1,2,\cdots,n
聚类的核心概念是相似度(Similarity)或距离(Distance),有多种相似度或距离的定义。因为相似度直接影响聚类的结果,所以其选择是聚类的根本问题。具体哪种相似度更合适取决于应用问题的特性。
马哈拉诺比斯距离
除了前面在KNN中介绍的闵可夫斯基距离以外,马哈拉诺比斯距离,简称马氏距离,也是另一种常用的相似度,考虑各个分量(特征)之间的相关性并与各个分量的尺度无关,马哈拉诺比距离越大相似度越小,越小相似度越大
给定一个样本集合X,X=[x_{ij}]_{m\times n},其协方差矩阵记为S,样本x_i与样本x_j之间的马氏距离d_{ij}定义为
::: align-center
d_{ij}=[(x_i-x_j)^TS^{-1}(x_i-x_j)]^{\frac{1}{2}}
:::
当S为单位矩阵,即样本数据的各个分量相互独立且各个分量的方差为1时,马氏距离就是欧氏距离。所以马氏距离是欧氏距离的推广
相关系数
样本之间的相似度也可以用相关系数(Correlation Coefficient)来表示。相关系数的绝对值越接近于1,表示样本越相似;越接近于0,表示样本越不相似
样本x_i与x_j之间的相关系数定义为
::: align-center
r_{ij}=\frac{\sum_{k=1}^m(x_{ki}-\bar{x}_i)(x_{kj}-\bar{x}_j)}{[\sum_{k=1}^m(x_{ki}-\bar{x}_i)^2(x_{kj}-\bar{x}_j)^2]^{\frac{1}{2}}}
:::
其中
::: align-center
\bar{x}_i=\frac{1}{m}\sum_{i=1}^mx_{ki},\bar{x}_j=\frac{1}{m}x_{kj}
:::
夹角余弦
样本之间的相似度也可以用夹角余弦(Cosine)来表示。夹角余弦越接近于1,表示样本越相似;越接近于0,表示样本越不相似。
样本x_i与样本x_j之间的夹角余弦定义为
::: align-center
s_{ij}=\frac{\sum_{k=1}^mx_{ki}x_{kj}}{[\sum_{k=1}^mx_{ki}^2\sum_{k=1}^mx_{kj}^2]^{\frac{1}{2}}}
:::
类或簇
通过聚类得到的类或簇,本质是样本的子集。下面只考虑硬聚类
用G表示类或簇(Cluster),用x_i,x_j表示类中的样本,用n_G表示G中样本的个数,用d_{ij}表示样本x_i与样本x_j之间的距离。下面给出几个常用的类的特征
(1)类的均值\bar{x}_G,又称类的中心
::: align-center
\bar{x}_G=\frac{1}{n_G}\sum_{i=1}^{n_G}x_i
:::
(2)类的直径(Diameter)D_G
类的直径D_G是类中任意两个样本之间的最大距离,即
::: align-center
D_G=\max_{x_i,x_j\in G}d_{ij}
:::
(3)类的样本散布矩阵(Scatter Matrix)A_G与样本协方差矩阵(Covariance Matrix)S_G
类的样本散布矩阵A_G为
::: align-center
A_G=\sum_{i=1}^{n_G}(x_i-\bar{x}_G)(x_i-\bar{x}_G)^T
:::
样本协方差矩阵S_G为
::: align-center
S_G=\frac{1}{n_G-1}A_G
:::
注:这里的n_G要减1是针对样本的贝塞尔无偏估计修正(Bessel's Correction)
类与类之间的距离
下面考虑类G_p与类G_q之间的距离D(p,q),也称为连接(Linkage)。类与之间的距离也有多种定义
设类G_p包含n_p个样本,G_q包含n_q个样本,分别用\bar{x}_p和\bar{x}_q表示G_p和G_q的均值,即类的中心
(1)最短距离或单连接
定义类G_p的样本与G_q的样本之间的最短距离为两类之间的距离
::: align-center
D_{pq}=\min\{d_{ij}|x_i\in G_p,x_j\in G_q\}
:::
(2)最长距离或完全连接
定义类G_p的样本与G_q的样本之间的最长距离为两类之间的距离
::: align-center
D_{pq}=\max\{d_{ij}|x_i\in G_p,x_j\in G_q\}
:::
(3)中心距离
定义类G_p与G_q的中心\bar{x}_p与\bar{x}_q之间的距离为两类之间的距离
::: align-center
D_{pq}=d_{\bar{x}_p\bar{x}_q}
:::
(4)平均距离
定义类G_p与类G_q任意两个样本之间的距离的平均值为两类之间的距离
::: align-center
D_{pq}=\frac{1}{n_pn_q}\sum_{x_i\in G_p}\sum_{x_j\in G_q}d_{ij}
:::
层次聚类
简介
层次聚类假设类别之间存在层次结构,将样本聚到层次化的类中。层次聚类又有聚合(Agglomerative)或自下而上(Bottom-Up)聚类、分裂(Divisive)或自上而下(Top-Down)聚类两种方法。因为每个样本只属于一个类,所以层次聚类属于硬聚类。
聚合聚类开始将每个样本各自分到一个类,之后将相距最近的两类合并,建立一个新的类,重复此操作直到满足停止条件,得到层次化的类别。而分类聚类开始将所有样本分到一个类,之后将已有类中相距最远的样本分到两个新的类,重复操作直到满足停止条件,得到层次化的类别。下面只介绍聚合聚类
聚合聚类的过程如下
- 对于给定的样本集合,开始将每个样本分到一个类
- 然后按照一定规则,例如类间距离最小,将最满足规则条件的两个类进行合并
- 如此反复进行,每次减少一个类,直到满足停止条件,如所有样本聚为一类
由此可知,聚合聚类需要预先满足下面三个要素:
- 距离或相似度
- 闵可夫斯基距离
- 马哈拉诺比斯距离
- 相关系数
- 夹角余弦
- 合并规则
- 类间距离最小
- 类间距离可以是最短距离、最长距离、中心距离、平均距离
- 停止条件
- 停止条件可以是类的个数达到阈值(极端情况类的个数是1)
- 类的直径超过阈值
算法(聚合聚类算法)
输入:n个样本组成的样本集合及样本之间的距离
输出:对样本集合的一个层次化聚类
(1)计算n个样本两两之间的欧氏距离\{d_{ij}\}
(2)构造n个类,每个类只包含一个样本
(3)样本类间距最小的两个类,其中最短距离为类间距距离,构建一个新类
(4)计算新类与当前各类的距离。若类的个数为1,终止计算,否则回到步(3)
可以看出聚合层次聚类算法的复杂度是\mathcal{O}(n^3m),其中m是样本维数,n是样本个数
K-Means 聚类
简介
K-Means(K均值)聚类是基于样本集合划分的聚类算法, K均值聚类将样本集合划分为k个子集,构成k个类,将n个样本分到k个类中,每个样本到其所属类的中心的距离最小。每个样本只能属于一个类,所以K均值聚类是硬聚类
模型
给定n个样本的集合X=\{x_1,x_2,\cdots,x_n\},每个样本由一个特征向量表示,特征向量的维数是m。K均值聚类的目标是将n个样本分到k个不同的类或簇中,这里假设k
划分C是一个多对一的函数。事实上,如果把每个样本用一个整数i\in \{1,2,\cdots,n\}表示,每个类也用一个整数l\in \{1,2,\cdots,k\}表示,那么划分或者聚类可以用一个函数l=C(i)表示,其中i\in\{1,2,\cdots,n\},l=\{1,2,\cdots,k\}。所以K均值聚类的模型是一个从样本到类的函数
策略
K均值聚类的策略是通过损失函数的最小化选取最优的划分或函数C^*
首先,采用欧氏矩阵平方(Square Euclidean Distance)作为样本之间的距离d(x_i,x_j)
::: align-center
\begin{aligned}
&d(x_i,x_j)=\sum_{k=1}^m(x_{ki}-x_{kj})^2\\
&=||x_i-x_j||^2
\end{aligned}
:::
然后,定义样本与其所属类的中心之间的距离的总和为损失函数,即
::: align-center
W(C)=\sum_{l=1}^k\sum_{C(i)=l}||x_i-\bar{x}_l||^2
:::
式中\bar{x}_l=(\bar{x}_{il},\bar{x}_{2l},\cdots,\bar{x}_{ml})^T是第l个类的均值或中心,n_l=\sum_{i=1}^n I(C(i)=l),I(C(i)=l)是指示函数,取值为1或0。函数W(C)也称为能量,表示相同类中的样本的相似程度
K均值聚类就是求解最优化问题:
::: align-center
\begin{aligned}
&C^*=\arg\min_C W(C)\\
&=\arg\min_C\sum_{l}^k\sum_{C(i)=l}||x_i-\bar{x}_l||^2
\end{aligned}
:::
相似的样本被聚到同类时,损失函数值最小,这个目标函数的最优化能达到聚类的目的。但是,这是一个组合优化问题,它的求解问题是NP困难问题。现实中采用迭代的方法求解
算法
k均值的聚类算法是一个迭代的过程,每次迭代包括两个步骤。首先选择k个类的中心,将样本逐个指派到与其最近的中心的类中,得到一个聚类的结果;然后更新每个类的样本的均值,作为类的新的中心;重复以上步骤,直到收敛为止。具体过程如下。
首先,对于给定的中心值(m_1,m_2,\cdots,m_k),求一个划分C,使得目标函数极小化
::: align-center
\min_C\sum_{l=1}^k\sum_{C(i)=l}||x_i-m_l||^2
:::
就是说在类中心确定的情况下,将每个样本分到一个类中,使样本和其所属类的中心之间的距离总和最小。求解结果,将每个样本指派到与其最近的中心m_l的类G_l中。求解结果,将每个样本指派到与其最近的中心m_l的类G_l中。
然后,对给定的划分C,再求各个类的中心(m_1,m_2,\cdots,m_k),使得目标函数极小化
::: align-center
\min_{m_1,m_2,\cdots,m_k}\sum_{l=1}^k\sum_{C(i)=l}||x_i-m_l||^2
:::
就是说在划分确定的情况下,使样本和其所属类的中心之间的距离总和最小。求解结果,对于每个包含n_l个样本的类G_l,更新其均值m_l
::: align-center
m_l=\frac{1}{n_l}\sum_{C(i)=l}x_i,l=1,2,\cdots,k
:::
重复以上两个步骤,直到划分不再改变,得到聚类结果。现将K均值聚类算法叙述如下。
算法(K均值聚类算法)
输入:n个样本的集合X
输出:样本集合的聚类C^{\cdot}
(1)初始化:令t=0,随机选择k个样本点作为初始聚类中心m^{(0)}=(m_1^{(0)},\cdots,m_l^{(0)},m_k^{(0)})
(2)对样本进行聚类。对固定的类中心m^{(t)},其中m_l^{(t)}为类G_l的中心,计算每个样本到类中心的距离,将每个样本指派到与其最近的中心的类中,构成聚类结果C^{(t)}
(3)计算新的类中心。对聚类结果C^{(t)},计算当前各个类中的样本的均值,作为新的类的中心m^{(t+1)}
(4)如果迭代收敛或符合停止条件,输出C^*=C^{(t)}
否则,令t=t+1,返回步2
K均值聚类算法的复杂度是\mathcal{O}(mnk),其中m是样本维数,n是样本个数,k是类别个数
算法特性
收敛性
- 属于启发式算法,不能保证收敛到全局最优,初始中心的选择会直接影响聚类结果
- 类中心在聚类的过程中会发生移动,但是往往不会移动太大,因为在每一步,样本被分到与其最近的中心的类中
初始类的选择
- 选择不同的初始中心,会得到不同的聚类结果
- 初始中心的选择,比如可以用层次聚类对样本进行聚类后得到k个类时停止,之后从每个类中选取一个与中心距离最近的点
类别k的选择
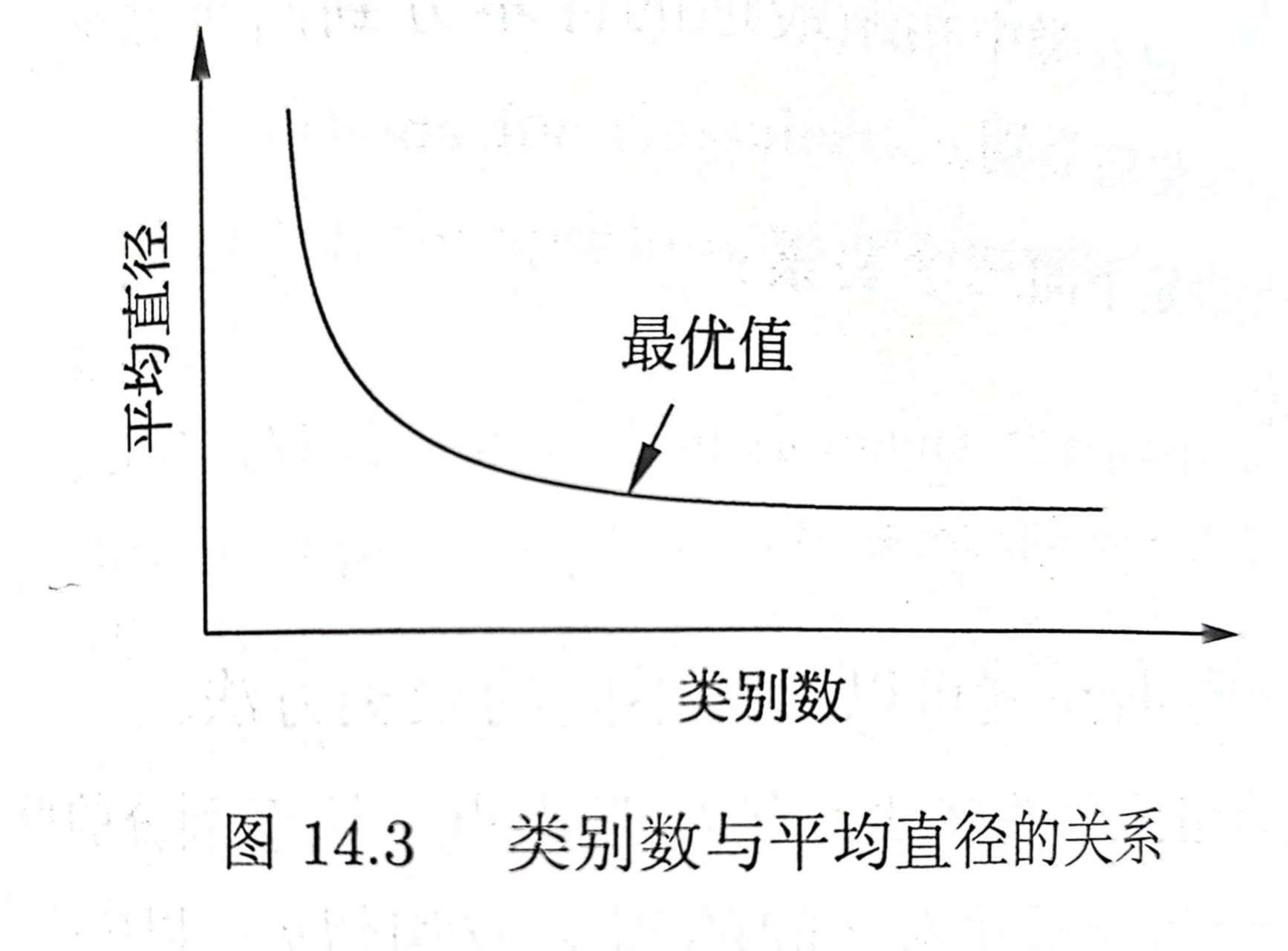
K均值聚类的k值需要事先指定,解决此问题的方法是尝试用不同的k值聚类,检验各自得到的聚类结果的质量,推测最优的k值。一般用平均直径来衡量聚类结果的质量,类别变大或超出某个值后,平均直径会不变,而这个值正是最优的k值。
简单练习
层次聚类

解:
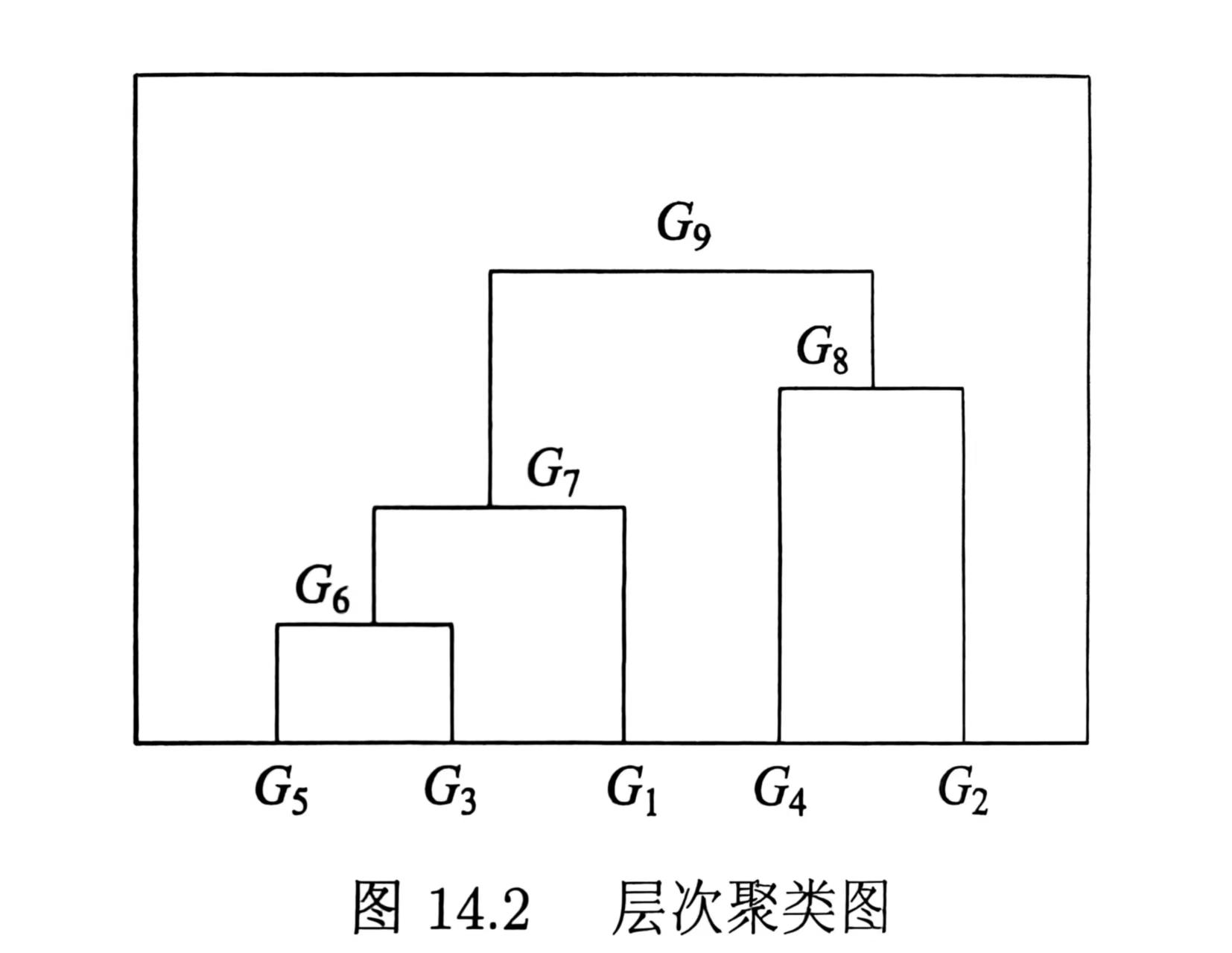
(1)首先用5个样本构建5个类,G_i=\{x_i\},i=1,2,\cdots,5,这样,样本之间的距离也就变成类之间的距离,所以5个类之间的距离亦为D
(2)由矩阵D可以看出D_{35}=D_{53}=1为最小,所以把G_3,G_5合并为一个新类,记作G_6=\{x_3,x_5\}
(3)计算G_6与G_1,G_2,G_4之间的最短距离,有
::: align-center
D_{61}=2,D_{62}=5,D_{64}=5
:::
又注意到其余两类之间的距离是
::: align-center
D_{12}=7,D_{14}=9,D_{24}=4
:::
显然D_{61}=2最小,所以将G_1,G_6合并成一个新类,记作G_7=\{x_1,x_3,x_5\}
(4)计算G_7与G_2,G_4之间的最短距离
::: align-center
D_{72}=5,D_{74}=5
:::
又注意到D_{24}=4最小,所以将G_2,G_4合并为新一类,记作G_8=\{x_2,x_4\}
(5)将G_7,G_8合并成一个新类,记作G_9=\{x_1,x_2,x_3,x_4,x_5\},即将全部样本聚为1类,聚类终止
K-Means 聚类

解:
(1)选择两个样本点作为类的中心。假设选择m_1^{(0)}=x_1=(0,2)^T,m_2^{(0)}=x_2=(0,0)^T
(2)以m_1^{(0)},m_2^{(0)}为类G_1^{(0)},G_2^{(0)}的中心,计算x_3=(1,0)^T,x_4=(5,0)^T,x_5=(5,2)^T与m_1^{(0)}=(0,2)^T,m_2^{(0)}=(0,0)^T的欧氏距离平方
- d(x_3,m_1^{(0)})=5,d(x_3,m_2^{(0)})=1,将x_3分到类G_2^{(0)}
- d(x_4,m_1^{(0)})=29,d(x_4,m_2^{(0)})=25,将x_4分到类G_2^{(0)}
- d(x_5,m_1^{(0)})=25,d(x_5,m_2^{(0)})=29,将x_5分到类G_1^{(0)}
(3)得到新的类G_1^{(1)}=\{x_1,x_5\},G_2^{(1)}=\{x_2,x_3,x_4\},计算类的中心m_1^{(1)},m_2^{(1)}
::: align-center
m_1^{(1)}=(2.5,2.0)^T,m_2^{(1)}=(2,0)^T
:::
(4)重复步骤(2)(3)
将x_1分到G_1^{(1)},将x_2分到G_2^{(1)},x_3分到类G_2^{(1)},x_4分到类G_2^{(1)},x_5分到类G_1^{(1)}
得到新的类G_1^{(2)}=\{x_1,x_5\},G_2^{(2)}=\{x_2,x_3,x_4\}
由于得到的新的类没有改变,聚类停止。得到聚类的结果:
::: align-center
G_1^{(*)}=\{x_1,x_5\},G_2^{(*)}=\{x_2,x_3,x_4\}
:::
全部评论 (0)
暂无评论,快来抢沙发吧~