卷积(前馈)神经网络
简介
卷积神经网络(Covolutional Neural Network, CNN)是一种在计算机视觉领域取得了巨大成功的深度学习模型。它们的设计灵感来自于生物学会总得视觉系统,旨在模拟人类的视觉处理方式。
图像原理与为什么需要CNN
灰白图像在计算机中是一堆按顺序排列的数字,数值为0到255,组成一个矩阵,而彩色图像在RGB颜色模型中又增添了第三个维度,分别储存R,G,B信息
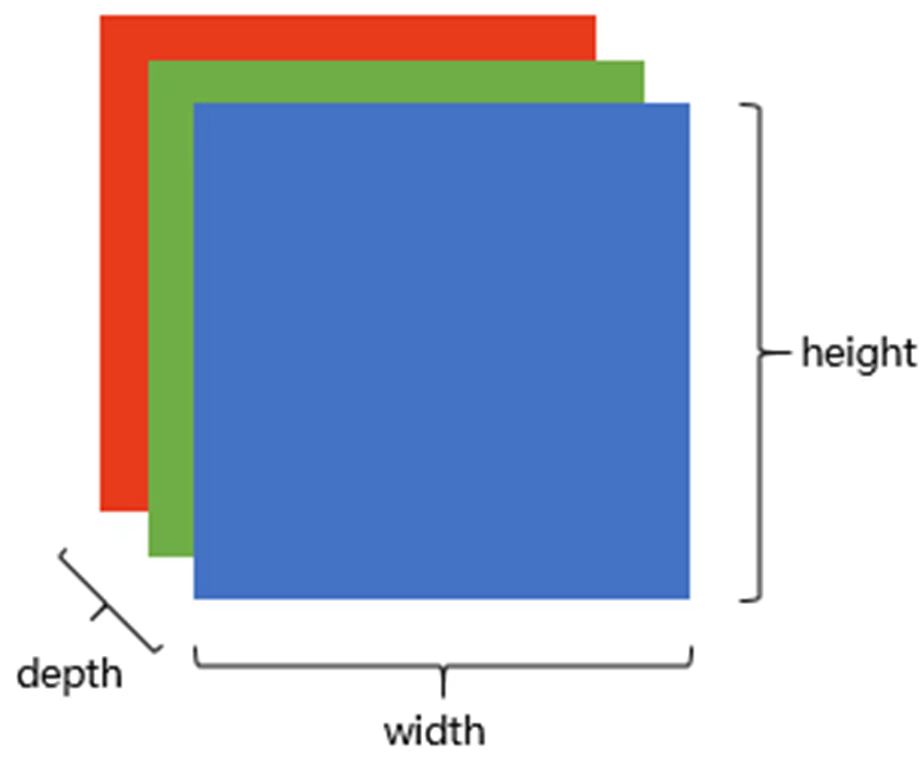
CNN主要完成了以下简化:
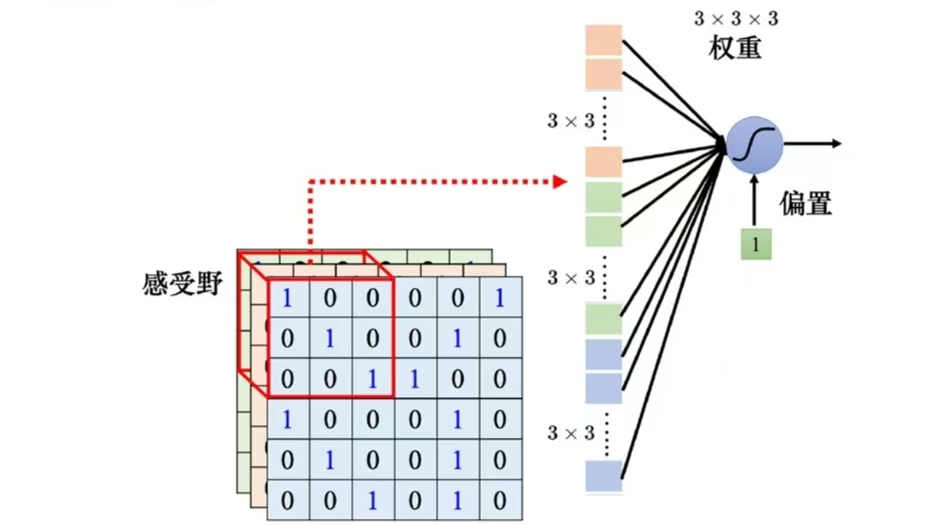
(1)感受野:传统全连接神经网络对于计算机视觉任务效率不佳,因为每次传导过程都需要经过所有的神经元,我们希望找到一个感受野,使得浅层神经网络尽量只关注局部的细节,而更深层的神经网络再捕捉物体的整体结构,这种层级化抽象符合人类视觉认知规律。
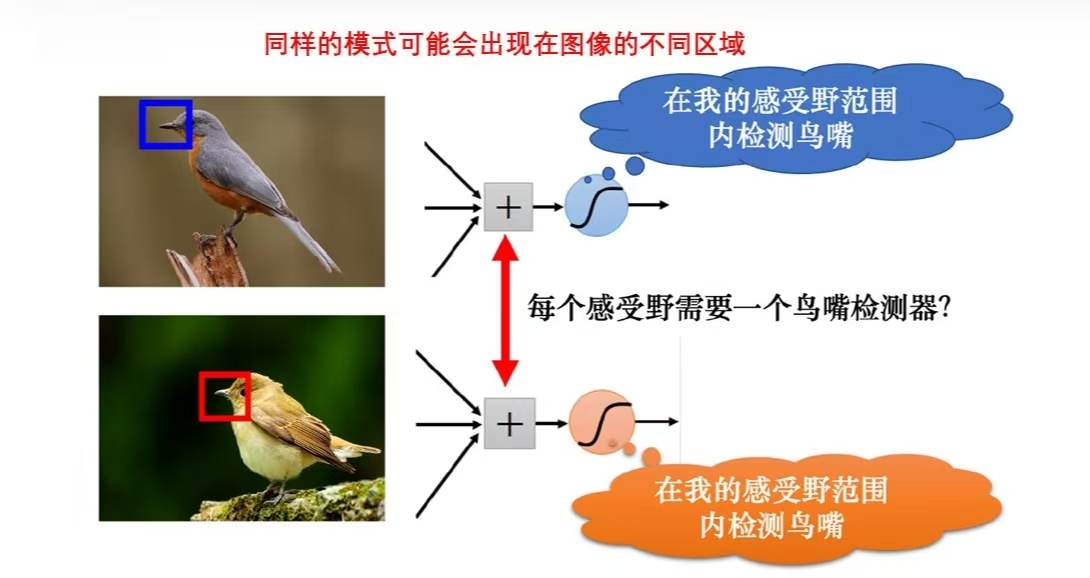
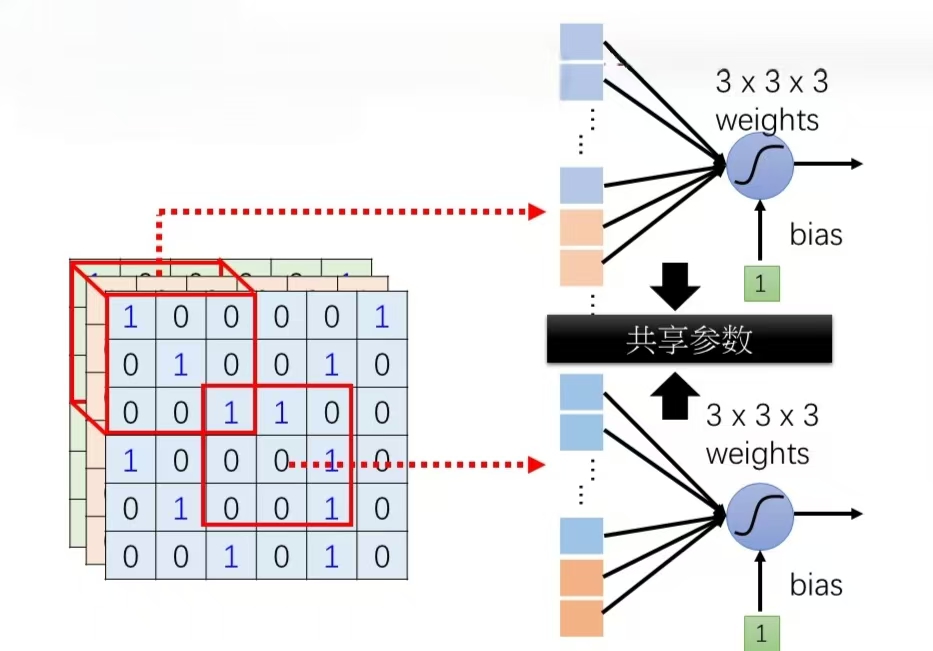
(2)共享参数:不同的感受野不一定需要不同的参数,同样地模式可能出现在不同的区域,因此不同的感受野之间的参数应允许共享,这样可以减少整体的参数量
(3)汇聚(也就是池化):通过卷积达到对信息的不断汇聚
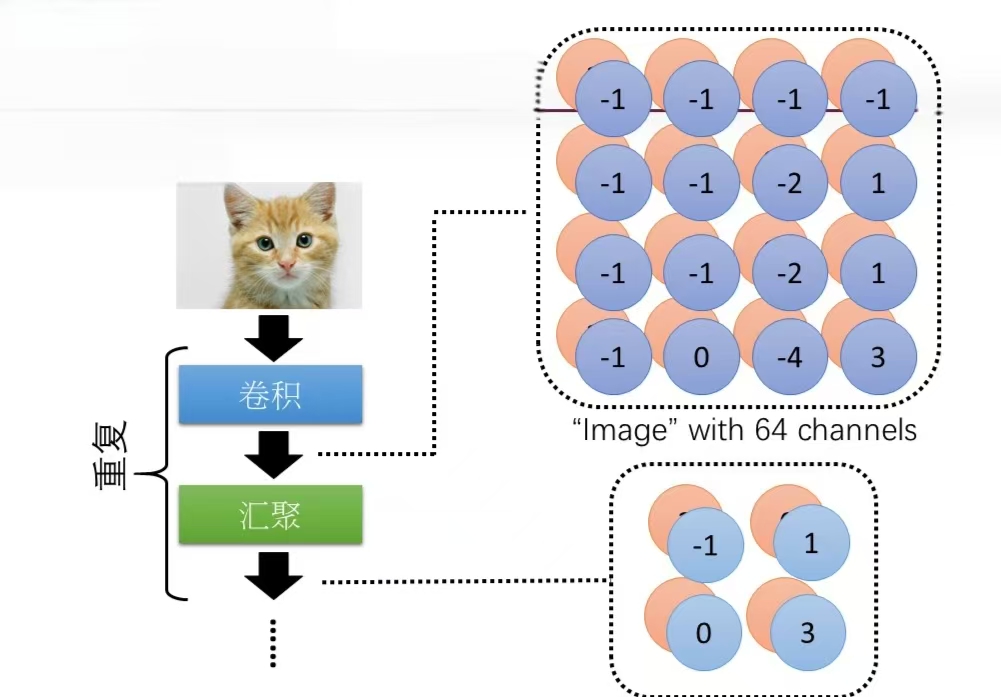
CNN一般由卷积层、汇聚层和全连接层组成
卷积
在CNN中,卷积操作是指将一个可移动的小窗口(称为数据窗口,或者上面的感受野)与图像进行逐元素相乘后相加的操作,这个小窗口其实是一组固定的权重,它可以被看作是一个特定的滤波器,或卷积核
注:这里的卷积不是严格意义上信号处理的卷积,因为严格意义上的卷积*需要翻转卷积核(对于一维卷积,信号序列与卷积核序列的逆序逐元素乘积,对于二维卷积,信号矩阵与卷积核的上下左右翻转得到的矩阵逐元素乘积)而是互相关\otimes,它又被称为不翻转卷积,这并不影响特征的学习
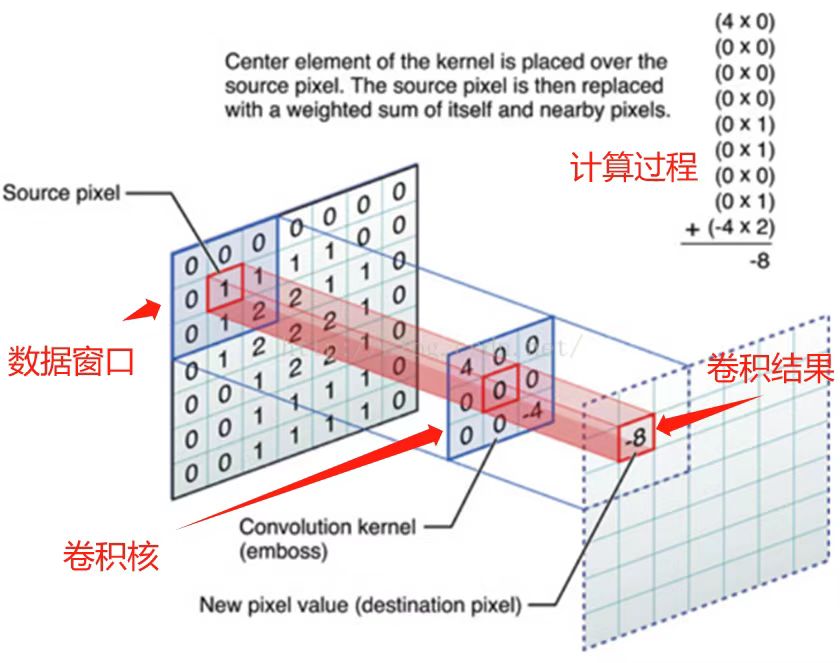
在这之中需要注意以下几个参数:
- 步长(Stride):卷积窗口滑动的位置步长
- 卷积核大小(Kernal Size):决定每个输出的大小
- 卷积核个数:决定输出的个数(或深度Depth)
- 零填充值(Zero Padding):在外围边缘(对于二维来说是(周围一圈)补充若干圈0,方便卷积窗口从初始位置以步长为单位可以刚好滑到末尾位置,通俗的讲—为了“总长度”能被步长整除
假设卷积层的输入神经元个数为I,卷积核大小为K,步长为S,在输入两端补P圈零,那么该卷积层的神经元个数为
::: align-center
O=\frac{I-K+2P}{S}+1
:::
分数部分计算不为整数时向下取整
根据这几个参数,卷积又分为
- 窄卷积:S=1,P=0,卷积后的输出长度为I-K+1
- 宽卷积:S=1,P=K-1,卷积后的输出长度为I+K-1
- 等宽卷积:S=1,P=\frac{K-1}{2},卷积后的输出长度为I
此外还有转置卷积(反卷积)、微步卷积、空洞卷积等等
卷积神经网络
卷积层
卷积神经网络的卷积层使用卷积来代替全连接,此时第l层的净活性值z^{(l)}为第l-1层活性值a^{(l)}的卷积加上偏置项b^{(l)}
::: align-center
z^{(l)}=w^{(l)}\otimes a^{(l-1)}+b^{(l)}
:::
卷积层有两个很重要的性质
- 局部连接:在卷积层中每一个神经元都只和下一层中某个局部窗口内的神经元相连,构成一个局部连接网络,这使得卷积层和下一层之间的连接数大的减少,原来是M_l\times M_{l-1}个连接,现在称为M_l\times K个连接(K是卷积核大小)
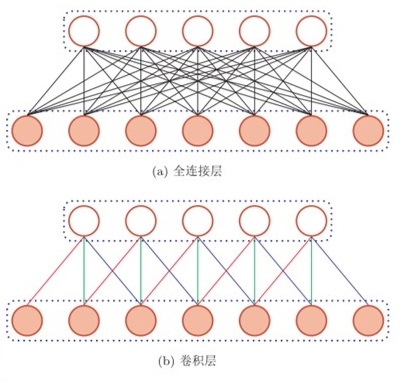
- 权重共享:作为参数的卷积核w^{(l)}对于第l层的所有神经元都是相同的
卷积层的主要作用是提取局部区域的特征,不同的卷积核相当于不同的特征提取器
为了充分的利用图像的局部信息,通常将神经元组织为三维结构的神经层,其大小为高度M\times宽度N\times深度D,它由M\times N\times D个特征映射构成。所谓的特征映射,就是实际的数据映射为数值(向量、矩阵)的映射(例如彩色图片就有三个通道的特征映射)
由上面的定义的卷积层的通用结构为
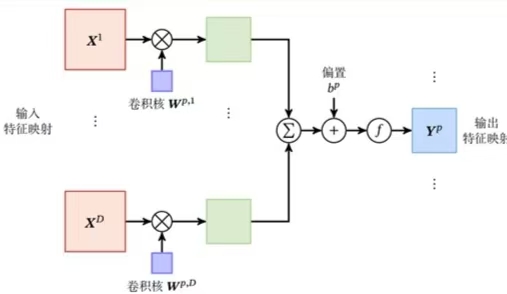
- 输入:特征映射组\mathcal{X}\in \mathbb{R}^{M\times N\times D},其中每个切片矩阵X^d\in\mathbb{R}^{M\times N},1\le d\le D
- 输出:特征映射组\mathcal{Y}\in\mathbb{R}^{M'\times N'\times P},其中每个切片矩阵Y^p\in\mathbb{R}^{M'\times N'},1\le p\le P
- 卷积核:\mathcal{W}\in\mathbb{R}^{U\times V\times P\times D},其中每个切片矩阵\mathcal{W}^{p,d}为一个二维卷积核1\le p\le P,1\le d\le D
例如:
- 输入:256\times 256\times 3的RGB图像(3个通道R,G,B)
- 卷积:64组3\times 3\times 3的卷积核扫描图像,每组生成一个特征图
- 输出:假设S=1,P=0,计算得64个254\times 254(\frac{256 - 3 + 0}{1} + 1=254)个特征图(每个特征图也有3个通道)
在卷积层实际的计算过程中:
- 用卷积核\mathcal{W}对输入特征进行卷积
- 将卷积结果加上偏置项得到净活性值
- 将净活性值通过激活函数得到活性值
池化层
池化(Pooling)层,也叫子采样层,其作用是特征选择,降低特征数量,从而减少参数数量。卷积层虽然可以显著减少网络中连接的数量,但神经元个数并没有显著减少,如果后面接入分类器,输入的维数依然很高,容易出现过拟合问题。为此,池化层被加入用于对每个卷积完的区域进行采样
参数学习
在卷积神经网络中,参数是卷积核的权重和偏置,与全连接前馈神经网络类似,卷积神经网络的参数也可以通过反向传播算法学习,迭代过程是相同的,但需要额外考虑池化层的影响,特别地
- 当池化层为最大池化时:误差\delta中的每个值会传到上一层对应区域在前向传播过程中输出活性值最大的神经元,其他对应区域的前层神经元得到的误差是0
- 当池化层为平均池化时:误差\delta会被平均分配到上一层对应区域的所有神经元上
构建一个简单的CNN
这里使用Pytorch构建一个3卷积层+3最大池化层的简单CNN,使用hymenoptera_data数据集训练和验证后进行蚂蚁和蜜蜂的二分类任务
python
import os
import torch
from PIL import Image
from torch import optim
from torchvision import transforms, datasets
import torch.nn as nn
import torch.utils as utils
import torch.nn.functional as function
############################# 数据载入 #############################
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224), # 随机裁剪缩放为224x224
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 转为张量
transforms.Normalize( # 标准化(ImageNet参数)
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
]),
'val': transforms.Compose([
transforms.Resize(256), # 调整大小为256x256
transforms.CenterCrop(224), # 中心裁剪为224x224
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
]),
}
# 数据集路径
data_dir = 'hymenoptera_data'
# 载入文件
image_datasets = {
x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x])
for x in ['train', 'val']
}
dataset_sizes = {
'train': len(image_datasets['train']), # 训练集样本数
'val': len(image_datasets['val']) # 验证集样本数
}
# DataLoader
data_loaders = {
x: utils.data.DataLoader(image_datasets[x], batch_size=4, shuffle=True)
for x in ['train', 'val']
}
# 测试训练集/测试集是否读入
print(f"训练集: {image_datasets['train'].classes}, 测试集: {image_datasets['val'].classes}")
############################# 网络构建 #############################
class SimpleCNN(nn.Module):
"""
蚂蚁/蜜蜂图片识别任务适合使用CNN实现
构建一个简单的3层卷积+1层池化的CNN网络
卷积层->最大池化层->卷积-层>最大池化层->卷积层->最大池化层->全连接层
"""
def __init__(self):
super(SimpleCNN, self).__init__()
# 第一层卷积(输入3通道RGB图片,使用64个3x3卷积核以步长2滑动(使得尺寸减半),生成64个特征图
self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=2)
# 第二层卷积(输入64通道特征图,输出128通道特征图)
self.conv2 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3)
# 第三层卷积(输入128通道特征图,输出256通道特征图)
self.conv3 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3)
"""
计算全连接层所需的神经元个数 不进行补零
第一卷积层 输入224x224(3通道) 卷积核3x3 步长2 输出 = floor((224 - 3 + 2 * 0) / 2) + 1 = 111
第一池化层 输入111x111(64通道) 卷积核2x2 步长2 输出 = floor((111 - 2 + 2 * 0) / 2) + 1 = 55
第二卷积层 输入55x55(64通道) 卷积核3x3 步长1 输出 = floor((55 - 3 + 2 * 0) / 1) + 1 = 53
第二池化层 输入53x53(128通道) 卷积核2x2 步长2 输出 = floor((53 - 2 + 2 * 0) / 2) + 1 = 26
第三卷积层 输入26x26(128通道) 卷积核3x3 步长1 输出 = floor((26 - 3 + 2 * 0) / 1) + 1 = 24
第三池化层 输入24x24(256通道) 卷积核2x2 步长2 输出 = floor((24 - 2 + 2 * 0) / 2) + 1 = 12
到达全连接层前: 12x12x256维张量
"""
# 全连接层(输入12x12x256维张量,输出256维张量)
self.fc1 = nn.Linear(in_features=12 * 12 * 256, out_features=256)
# 全连接层(输入256维张量,输出128维张量)
self.fc2 = nn.Linear(in_features=256, out_features=128)
# 全连接层(输入128维张量,输出2维张量作为二分类输出)
self.fc3 = nn.Linear(in_features=128, out_features=2)
def forward(self, x):
# 第一次卷积后通过ReLU函数
x = function.relu(self.conv1(x))
# 通过最大池化层
x = function.max_pool2d(x, kernel_size=2)
# 第二次卷积后通过ReLU函数
x = function.relu(self.conv2(x))
# 通过最大池化层
x = function.max_pool2d(x, kernel_size=2)
# 第三次卷积后通过ReLU函数
x = function.relu(self.conv3(x))
# 通过最大池化层
x = function.max_pool2d(x, kernel_size=2)
# 重新组织大小为12x12x256
x = x.view(-1, 12 * 12 * 256)
# 全连接第一层通过ReLU函数
x = function.relu(self.fc1(x))
# 全连接第二层通过ReLU函数
x = function.relu(self.fc2(x))
# 全连接第三层结果直接作为最终结果
x = self.fc3(x)
return x
############################# 开始训练 #############################
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
cnn_model = SimpleCNN().to(device)
# 使用交叉熵损失
criterion = nn.CrossEntropyLoss()
# 随机梯度下降(学习率0.001)
optimizer = optim.SGD(cnn_model.parameters(), lr=0.001)
# 学习率调度
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
# 训练循环
# 迭代20次
def train_model(model, num_epochs=20):
best_acc = 0.0
history = {'train_loss': [], 'val_acc': []}
for epoch in range(num_epochs):
print(f'第 {epoch}/{num_epochs - 1} 轮')
print('-' * 10)
# 训练阶段
# 模型切换到训练阶段
model.train()
# 训练迭代的累积损失
running_loss = 0.0
# 载入数据
for inputs, labels in data_loaders['train']:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
# 计算误差
loss = criterion(outputs, labels)
# 反向传播误差
loss.backward()
# 更新参数
optimizer.step()
# 计算这个Batch批次的总损失
running_loss += loss.item() * inputs.size(0)
# 本次迭代的总累积平均损失
epoch_loss = running_loss / dataset_sizes['train']
history['train_loss'].append(epoch_loss)
# 验证阶段
# 模型切换到验证阶段
model.eval()
# 正确数
correct = 0.0
with torch.no_grad():
# 载入验证集
for inputs, labels in data_loaders['val']:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicts = torch.max(outputs, 1)
correct += torch.sum(torch.eq(predicts, labels)).item()
# 计算本次迭代的正确率
epoch_acc = correct / dataset_sizes['val']
history['val_acc'].append(epoch_acc)
print(f'训练损失: {epoch_loss:.4f} 准确度: {epoch_acc:.4f}')
# 保存最佳模型
if epoch_acc > best_acc:
best_acc = epoch_acc
torch.save(model.state_dict(), 'best_model.pth')
# 在验证完成后调整学习率
if isinstance(scheduler, optim.lr_scheduler.ReduceLROnPlateau):
scheduler.step(metrics=epoch_loss) # 基于验证损失调整
else:
scheduler.step() # 常规调度
# 可视化训练过程
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimHei', 'SimSun']
plt.rcParams['axes.unicode_minus'] = False
plt.plot(history['train_loss'], label='训练损失')
plt.title('训练损失')
plt.subplot(1, 2, 2)
plt.plot(history['val_acc'], label='验证准确率')
plt.title('验证准确率')
plt.savefig('training_history.png')
return model
# 开始训练模型
train_model(cnn_model)
############################# 数据预测 #############################\
predict_model = SimpleCNN().to(device)
# 加载保存的最佳模型
predict_model.load_state_dict(torch.load('best_model.pth'))
# 设置为评估模式
predict_model.eval()
def predict_image(path):
# 加载并预处理图像
img = Image.open(path).convert('RGB')
# 处理图像
predict_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
img_tensor = predict_transform(img).unsqueeze(0).to(device)
# 执行预测
with torch.no_grad():
outputs = predict_model(img_tensor)
# 转化为Softmax概率
probabilities = torch.nn.functional.softmax(outputs, dim=1)
# 返回最大的概率作为置信度,同时返回概率最大的索引
conf, predicts = torch.max(probabilities, 1)
# 可视化结果
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 4))
plt.subplot(1, 2, 1)
plt.imshow(img)
plt.axis('off')
plt.subplot(1, 2, 2)
classes = ['蚂蚁', '蜜蜂']
plt.bar(classes, probabilities.cpu().numpy()[0], color=['red', 'blue'])
plt.title(f'预测: {classes[predicts.item()]} ({conf.item():.2%})')
plt.ylim(0, 1)
plt.show()
return classes[predicts.item()], conf.item()
############################# 尝试进行二分类 #############################
predict_class, confidence = predict_image("ant.jpg")
print(f"预测结果: {predict_class} | 置信度: {confidence:.2%}")
predict_class, confidence = predict_image("bee.jpg")
print(f"预测结果: {predict_class} | 置信度: {confidence:.2%}")
全部评论 (0)
暂无评论,快来抢沙发吧~