前言
这是笔者在结束科班课程后对此系列笔记的接续更新,此后该系列的笔记主要以论文解析为主,值得注意的是,在之前CNN领域有诸多创新,例如2012年的AlexNet,2014年的VGGNet,2015年的ResNet,此部分均略过,我们将从2017年的Transformer架构开始继续笔记的更新,目前的更新的计划为:
- 简单的介绍Transformers Encoder-Decoder架构(2017,本节)
- OpenAI GPT1、谷歌BERT模型(2018)
- OpenAI GPT2(2019)
- ViT(2020)
- OpenAI CLIP(2021)
本节的笔记主要分析LLM经典论文(arXiv)Attention is all you need,其他内容部分引用了3b1b的机器学习系列视频和B站其余UP的一些内容,诚挚感谢他们!
另外需要注意的是,从本节开始,笔记对相应内容的讨论将变得较为口语化,若有不严谨妥当之处,请读者谅解
回望
在接触Transformers架构之前,首先我们需要回望之前的神经网络架构,本节仅简单回顾相关知识,并不会作深入的探讨
序列转导任务
序列转导任务面向的对象是序列数据,即具有顺序关系的数据,每个元素的顺序对于数据大的整体含义非常重要,在处理此类数据时,一般通过以下过程使其变为张量,以下的例子,均以翻译“我不喜欢水课”这段句子为例
- 分词(Tokenization):由分词器(Tokenizer)完成,主要任务是将句子分为不同的词元,也就是我们常说的Token,例如将“我不喜欢水课”分为“我”、“不”、“喜欢”、“水课”;亦或者是分为“我不”、“喜欢”、“水课”。分词器通常是跟随模型一同训练的
- 嵌入(Embedding):由模型的嵌入层完成,本质上是一个类似“查找表”的数据结构,将离散的词元映射为高维空间中的稠密张量
一个有意思的点是,训练得当后的高维张量间是存在一定关系的(这对于后面注意力机制的引入非常重要),例如“猫”、“狗”和“动物”的张量之间的距离会很近,“1”的张量的两倍得到的张量与“2”的张量非常相似等等
FNN
前馈神经网络FNN(笔者的笔记),由通用近似定理保证的非线性逼近能力,使得其可以在类别预测等领域取得很好的成绩
但是此类网络很快便在序列转导任务上遇到了困难,首先序列数据是有顺序的,而在FNN中,输入的数据是不分先后的,并且输入长度还是固定的,这就让FNN失去了感知数据前后联系,和应对不同长度序列数据的能力
并且,更糟糕的是,全连接FNN的网络架构并不能让网络注意到序列数据中,那一个或几个数据更为重要,故FNN并不能很好的处理序列转导任务
RNN
为了解决FNN无法处理序列转导任务的问题,RNN(笔者的笔记)应运而生,其基本结构如下图
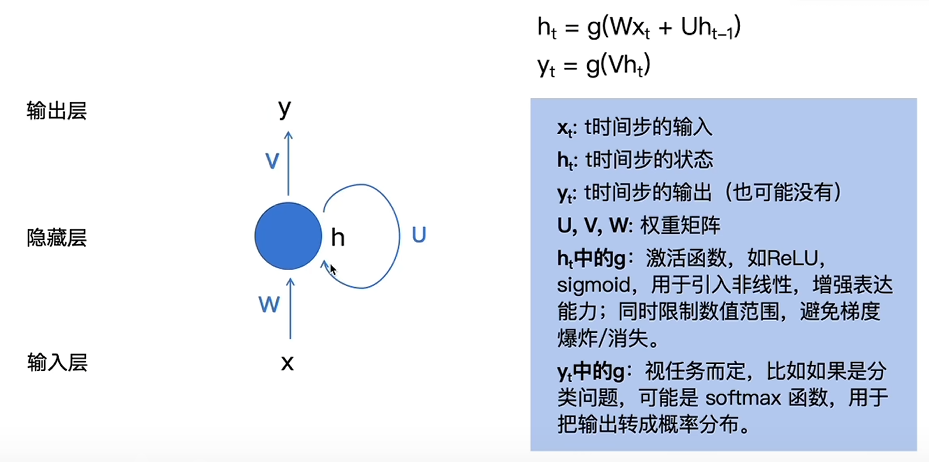
将其按时间展开,得到其按时间展开的结构
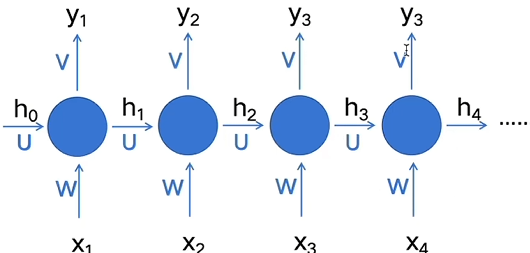
可以看到每一时刻RNN都会将输入和上一刻的隐藏状态重新作为输入送入网络处理,之后获得这一时刻的输出,如此RNN就获得了处理序列数据的能力
但RNN依然是不完美的,其中一个饱受诟病的是随着网络的加深RNN将面临严重的长程依赖问题,之前序列数据的影响会随着后续序列数据的不断输入而不断变小,但我们知道在实际的序列转导任务中,前侧序列与后侧序列的语义关系并不是随着语句词元的距离增加而减少的,并且某一时刻的输入序列并不一定至于前面的输入有关,而还有可能与后侧的输入有关,一个很好的例子就是倒装句的翻译任务,此时前侧语句的语义可能还会受到后侧语句的影响,而RNN完全处理不了这种“当前输入与在未来的输入有关”的问题
对于长程依赖问题,后续的一些网络引入了门控机制进行改进,例如LSTM,但RNN在序列转导任务中还面临着另外一个非常严重的问题:输入和输出可能不是等长的。因为RNN的架构注定了其是一个“输入一个数据输出一个数据”的网络,而对于类似语句翻译的这种任务,输入和输出有时候并不一定是等长的,此时RNN就会面临很严重的对齐问题
编码器-解码器架构
为了解决序列转导任务中输入-输出不等长的问题,编码器-解码器架构应运而生,其架构如下图
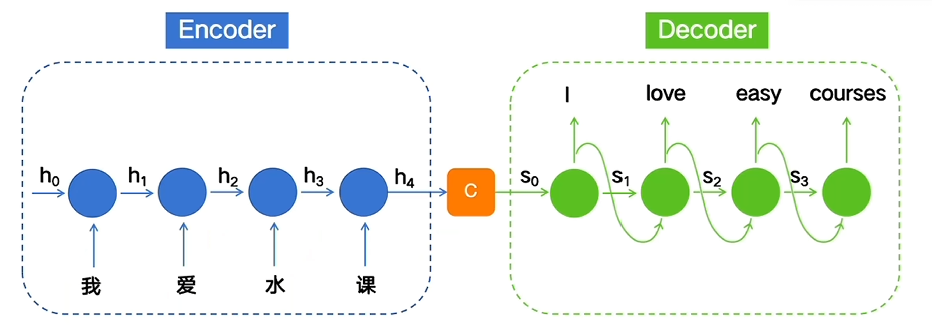
可以看到它将原RNN最后一层的隐藏层状态输入到了一个“解码器”之中,之后再令解码器以序列的形式获得输出
但是编码器-解码器架构依然面临着长程依赖问题,此外,随着任务量的不断增大,编码器-解码器架构面临的另外一个严重问题就是其不能很好的利用GPU的并行计算能力,因为编码器-解码器架构的所有操作都是串行的,这意味着后一刻的操作要在前一刻的操作执行完毕后才能进行,一个“单线程”的网络架构注定了编码器-解码器结构的效率是非常低下的,它将很难解决更大量的序列转导任务
Transformers
为此,Transformers架构应运而生,其经典的Encoder-Decoder架构如下图
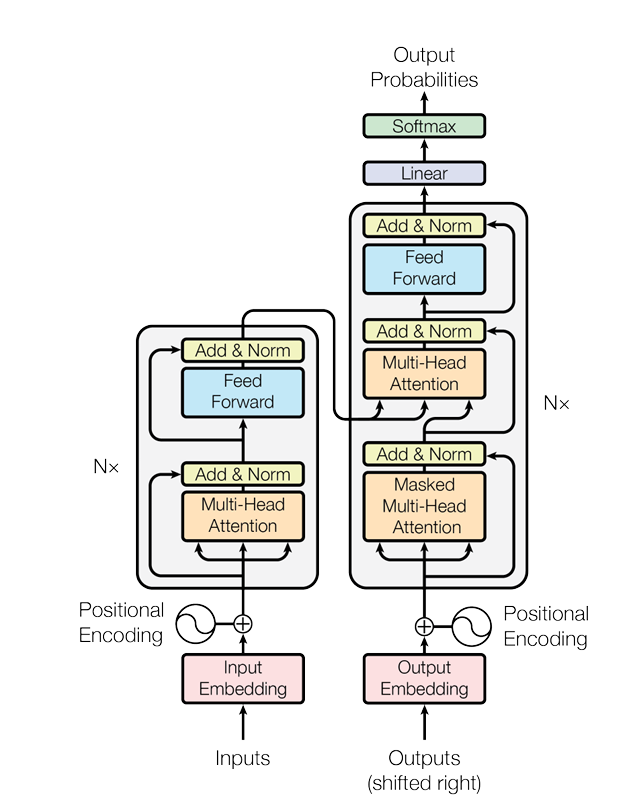
下面进行简单的介绍,还是以翻译句子为例
首先从左侧的编码器部分开始:
Encoder
输入
嵌入后的词源张量,对于我们这里的翻译任务来说,是中文向量空间上的词源张量
位置编码

首先,输入的词张量被首先打上额外的位置编码
因为Transformes的架构导致了其不能原生地识别输入序列的前后顺序关系,如果读者仔细思考了引发前面编码器-解码器架构串行计算效率的原因便会发现:
::: align-center
按顺序输入序列数据就是导致编码器-解码器串行计算的元凶之一
:::
但我们的输入数据是完全已知的,所以干掉串行效率的首要解决办法就是将输入序列“一股脑”全“塞进去”,但是此时前后顺序关系便无从得知了。因此,Transformers架构考虑额外对Embedding添加一个位置编码,通过将位置也一并嵌入进张量的形式解决了前后顺序无从得知的问题
单头自注意力机制
注意力机制在编码器-解码器时代便已经存在了,那时注意力机制主要通过简单的加权计算调整不同序列的权重,从而影响不同时刻的输出
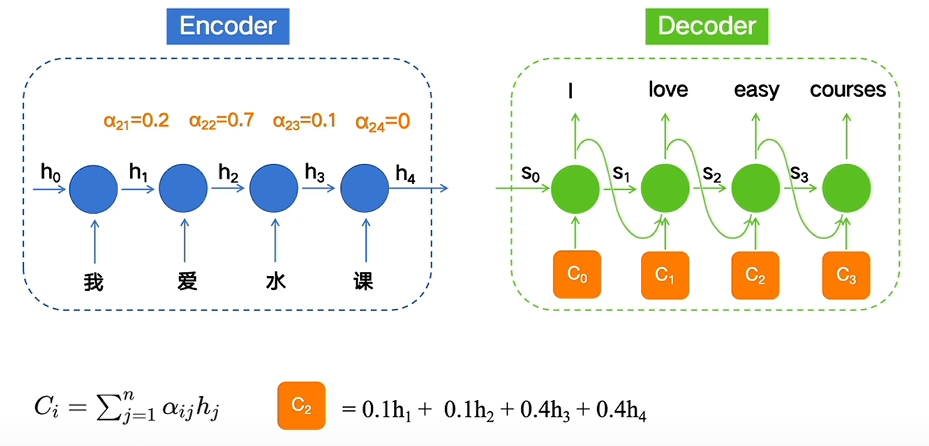
但Transformers的新架构需要一种全新设计的注意力机制,也就是我们常说的自注意力机制,或键值对注意力机制
首先重新考虑我们的Embedding,在经过自注意力机制处理前其是一个巨大的矩阵
::: align-center
T=\begin{pmatrix}t_1&t_2&\cdots&t_n\end{pmatrix}
:::
其中t_k是列向量,每一个列向量都代表着一个嵌入后的Token,我们的目标是:
::: align-center
让嵌入后的词源们“注意到”自个和别人(其实也可以是自己)之间的“关系”
:::
为此自注意力机制考虑
- 首先将T乘以某个Query权重矩阵W_q得到Query矩阵Q
::: align-center
Q=W_qT
:::
2. 之后将T乘以某个Key权重矩阵W_k得到Key矩阵K
::: align-center
K=W_kT
:::
3. 再将T乘以某个Value权重矩阵W_v得到Value矩阵V
::: align-center
V=W_vT
:::
之后计算注意力分布
::: align-center
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V
:::
并将其叠加在原来的T上,其中W_q,W_k,W_v的数值是训练得到的
这里我们可以理解为,对于每一个T内的列词元向量t_i,经W_q作用后都会变为一条Query向量q_i,类似的我们会得到Key向量和Value向量k_i,v_i,每一个Query向量其实都相当于一条问句
::: align-center
有谁和我有关系???
:::
而每一条Key向量都相当于在回答
::: align-center
我和你有关系!!!
:::
而Value向量则代表
::: align-center
我和你有XXX关系!!!
:::
此时我们再考虑分解注意力分布
::: align-center
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V
:::
我们便可以知道,在计算QK^T这个内积运算时,它衡量的是每个q_i与k_i的线性相似度,\sqrt{d_k}是用于提高数值稳定的项,而外层的softmax函数用于将相似度归一化为概率,在之后施加在V上并叠加在原来的T上,我们便获得了含每一列中含上下文信息的新Embedding矩阵
多头自注意力机制
读者可能会注意到上面的注意力机制仅进行了一次,但是如果我们想要注意到更多的信息,例如在对于“食物”的评判上,我们不光希望在整体上以 好吃/难吃 的视角进行评判,而希望在 能量/营养/外观 等多个方面进行评价,那么此时多头注意力机制便诞生了
与单头注意力机制类似,只不过多头注意力机制使用了多个尺寸较小的W_q,W_k,W_v获得不同尺度的注意力分布,之后叠加在原Embedding上送入下一步处理
残差连接和归一化

即将上一步的输入直接通过一个“快捷通道”叠加在上一步的输出中并归一化,这里主要借鉴了ResNet的思想,一方面避免了网络过深引发的梯度消失问题,另一方面也避免了单个注意力单元产生误差时结果偏差过大的问题
全连接层
之后Transformers架构考虑将上下文含义丰富的信息送入全连接层进行进一步处理,一种解释认为全连接层使得Transformers架构拥有了“记忆力”,因为考虑前面提到的“我不喜欢水课”这个句子的翻译任务,在经过多头注意力机制后模型明白了不同词元如“我”、“不喜欢”、“水课”之间的关系,但模型并不理解什么是“我”,什么是“不喜欢”,什么是“水课”。此时,经过训练保存了权重后的全连接层就充当了“先验知识提供者”的作用,在其中模型会不打断的将“我”、“不喜欢”、“水课”与已经储存的先验知识权重进行非线性加权平均,这样在经过全连接层处理后的Embedding便拥有了一些先验知识,例如“水课”中含有了“无聊的”、“烦躁的”、“课程”等其他知识的内容
输出
上下文语意丰富的Token Embedding张量信息矩阵
Decoder
解码器承担了将编码后的Embedding解码为目标序列的任务
输入
以下以翻译语句这个任务为例:
- 在训练过程中,遵循教师强制(Teacher Forcing)原则,解码器的输入的是全部的目标序列的嵌入张量,例如“I don't like boring courses”
- 在推理过程中,解码器的输入是上一次解码器的输出,如第一次是起始符“
”,第二次是“I”,第三次是“I don't”,以此类推,直到最后生成终止符“<\s>”停止解码迭代
掩码多头注意力机制
与编码时不同,在不带掩码的自注意力机制中,一个Token的Embedding会双向的吸收上下文的语义信息,而在解码时:
- 在训练过程中,我们不希望解码器看到句子“后面的内容”,例如我们在翻译到“I don't like”,准备解码“boring”时,我们不希望模型提前看到后面的由我们输入的答案“boring”和“cources”,这就好比考试时试卷上已经写上了答案,我们肯定希望模型自己翻译出“boring”
- 在推理过程中,模型自回归的生成翻译的内容,后侧的张量还未被填充任何有效的内容,我们也不希望模型被后侧未填充内容的噪声张量干扰
由此,掩码多头注意力机制考虑将\frac{QK^T}{\sqrt{d_k}}这个矩阵的下三角部分置于负无穷,这样在经过softmax函数后下三角部分将变为0,,模型也不会再出现被后方Token Embedding影响的问题

之后的部分
在之后,多头注意力模块将前面由掩码多头注意力机制处理后的解码器输入Embedding作为Query,将Encoder处理后的原文Embedding作为Key和Value进行注意力处理,这个过程就好比当翻译到“boring”时,前面解码器输入的“I don't”的Embedding对Encoder编码后的中文原文问询
::: align-center
下一个我该填什么才能符合中文原文的意思?
:::
而中文原文中,“水”的回应是最大的,于是结果中“boring”位置上的向量获取了很多原文中“水”的信息,而之后的全连接层进一步用先验知识加深了模型对“水”的理解,让其更偏向于将其翻译为“无聊的”,而不是“自来水”
输出
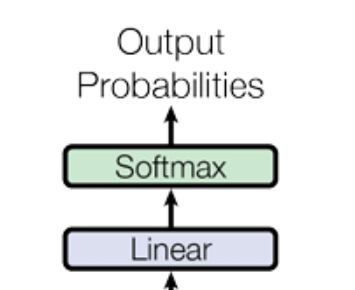
最后解码器部分得到了语义丰富的,在英文词空间上的词源张量,之后将其通过线性投影层并经过softmax函数转化为概率,我们便可以在英文词库中寻找概率最大的那个词,例如“boring”位置上的向量产生的概率在词库中对应词“boring”上是最大的,则我们就将这个位置填入“boring”,并将之前的结果“I don't like boring”接着送入解码器,直到解码器最后翻译出结束符“<\s>”
全部评论 (0)
暂无评论,快来抢沙发吧~