前言
所有\alpha分位数均为上分位数,在查表时请注意转换
另外,本文的假设检验主要介绍参数检验方法,非参数检验方法暂时不设计
检验总体均值(单/双独立样本均值检验)
单变量
置信区间
样本数量足够大时(>30)
枢轴量分布:\frac{\bar{X}-\mu}{\sigma/\sqrt{n}}\sim N(0,1) (林德贝格-列维中心极限定理)
标准误:SE=\frac{\sigma}{\sqrt{n}}
双侧置信区间:[\bar{X}-z_{\frac{\alpha}{2}}SE,\bar{X}+z_{\frac{\alpha}{2}}SE]
单侧置信区间
- 左侧:[\bar{X}-z_{\alpha}SE,+\infty)
- 右侧:(-\infty,\bar{X}+z_{\alpha}SE]
此时若总体方差\sigma^2未知,可以使用其无偏估计,即样本方差(带贝塞尔n-1修正项)s^2代替
样本数量较小时
若此时\sigma^2已知且已知总体服从正态分布,依然可以使用上面的方法
但更常见的是\sigma^2未知且总体分布也未知,此时需要使用t分布
枢轴量分布:\frac{\bar{X}-\mu}{s/\sqrt{n}}\sim t(n-1)
标准误:SE=\frac{s}{\sqrt{n}}
如果\sigma^2已知但总体分布未知,并且想用\sigma^2构建置信区间,此时t分布和中心极限定理均不可用,这里不作讨论
假设检验
样本数量较大时(>30)
统计检验量:z=\frac{\bar{X}-\mu}{\sigma/\sqrt{n}}
此时若总体方差\sigma^2未知,可以使用其无偏估计,即样本方差(带贝塞尔n-1修正项)s^2代替
样本数量较小时
如上,当\sigma^2未知且总体分布未知时
统计检验量:t=\frac{\bar{X}-\mu}{s/\sqrt{n}}
双变量
置信区间
总体方差已知 / 总体方差未知但样本数量足够大(>30)
枢轴量分布:\frac{(\bar{X}_1-\bar{X}_2)-(\mu_1-\mu_2)}{\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}}\sim N(0,1)
标准误:SE=\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}
当样本数量足够大且\sigma_1,\sigma_2未知时,可以使用其无偏估计,即样本方差(带贝塞尔n-1修正项)代替总体方差
枢轴量分布:\frac{(\bar{X}_1-\bar{X}_2)-(\mu_1-\mu_2)}{\sqrt{\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2}}}\sim N(0,1)
标准误:SE=\sqrt{\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2}}
置信区间构建与上方相同
总体方差未知且样本数量较小
枢轴量分布:\frac{(\bar{X}_1-\bar{X}_2)-(\mu_1-\mu_2)}{\sqrt{\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2}}}\sim t(df)
其中t分布的自由度需要使用萨特斯韦特近似
::: align-center
df=\frac{(\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2})^2}{\frac{(\frac{s_1^2}{n_1})^2}{n_1-1}+\frac{(\frac{s_2^2}{n_2})^2}{n_2-1}}
:::
置信区间构建与上方相同
假设检验
总体方差已知
统计检验量:z=\frac{(\bar{X}_1-\bar{X}_2)-(\mu_1-\mu_2)}{\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}}
总体方差未知
假设方差相等
样本数量足够大时(n>30)
使用合并的样本方差修正
统计检验量:z=\frac{(\bar{X_1}-\bar{X_2})-(\mu_1-\mu_2)}{s_p\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}}
其中
::: align-center
s_p=\sqrt{\frac{(n_1-1)s_1^2+(n_2-1)s_2^2}{n_1+n_2-2}}
:::
样本数量较小时
使用合并的样本方差修正
统计检验量:t=\frac{(\bar{X_1}-\bar{X_2})-(\mu_1-\mu_2)}{s_p\sqrt{\frac{1}{n_1}+\frac{1}{n_2}}}
自由度df=n_1+n_2-2
s_p的计算方法见上
假设方差不相等
样本数量足够大时(n>30)
统计检验量:z=\frac{(\bar{X}_1-\bar{X}_2)-(\mu_1-\mu_2)}{\sqrt{\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2}}}
样本数量较小时
使用带萨特斯韦特近似(仅当假设总体方差不相等且样本数量较小时使用)的韦尔奇t检验(Welch's t test)
统计检验量:t=\frac{(\bar{X}_1-\bar{X}_2)-(\mu_1-\mu_2)}{\sqrt{\frac{s_1^2}{n_1}+\frac{s_2^2}{n_2}}}
df的计算见上
检验统计概率(单/双独立样本比例检验)
单变量
置信区间
枢轴量分布:\frac{\hat{p}-p}{\sqrt{\frac{p(1-p)}{n}}}\sim N(0,1)(棣莫弗-拉普拉斯中心极限定理,需要验证np\ge 5,n(1-p)\ge 5)
标准误:SE=\sqrt{\frac{p(1-p)}{n}}
置信区间构造见上
在总体概率p未知时,计算SE可以用其无偏估计\hat{p}代替,其准确性由伯努利大数定律保证
假设检验
统计检验量z=\frac{\hat{p}-p}{\sqrt{\frac{p(1-p)}{n}}}(需要验证np\ge 5,np(1-p)\ge 5)
双变量
置信区间
枢轴量分布:\frac{(\hat{p}_1-\hat{p}_2)-(p_1-p_2)}{\sqrt{\frac{p_1(1-p_1)}{n_1}+\frac{p_2(1-p_2)}{n_2}}}\sim N(0,1)(需要验证n_1p_1\ge 5,n_1(1-p_1)\ge 5,n_2p_2\ge 5,n_2(1-p_2)\ge 5)
标准误:SE=\sqrt{\frac{p_1(1-p_1)}{n_1}+\frac{p_2(1-p_2)}{n_2}}
在总体概率p_1,p_2未知时,计算SE可以用其无偏估计\hat{p_1},\hat{p_2}代替,其准确性由伯努利大数定律保证
假设检验
总体概率已知
统计检验量:z=\frac{(\hat{p}_1-\hat{p}_2)-(p_1-p_2)}{\sqrt{\frac{p_1(1-p_1)}{n_1}+\frac{p_2(1-p_2)}{n_2}}}(需要验证n_1p_1\ge 5,n_1p_1(1-p_1)\ge 5,n_2p_2\ge 5,n_2p_2(1-p_2)\ge 5)
总体概率未知
假设两个总体概率相等
即针对p_1-p_2\ge/=/\le 0的情况
使用合并的总体概率修正
统计检验量:z=\frac{(\hat{p}_1-\hat{p}_2)-(p_1-p_2)}{\sqrt{\hat{p}_{pool(1-\hat{p}_{pool})(\frac{1}{n_1}+\frac{1}{n_2})}}}
其中
::: align-center
\hat{p}_{pool}=\frac{X_1+X_2}{n_1+n_2}
:::
假设两个总体概率不相等
即针对p_1-p_2\ge/=/\le \delta的情况
使用样本的概率,即p_1,p_2的无偏估计\hat{p}_1,\hat{p}_2代替总体概率,其准确性由伯努利大数定律保证
统计检验量:z=\frac{(\hat{p}_1-\hat{p}_2)-(p_1-p_2)}{\sqrt{\frac{\hat{p}_1(1-\hat{p}_1)}{n_1}+\frac{\hat{p}_2(1-\hat{p}_2)}{n_2}}}
检验总体方差(单/双样本方差检验)
单变量
置信区间
枢轴量分布:\frac{(n-1)s^2}{\sigma^2}\sim \chi^2(n-1)
双侧置信区间:[\frac{(n-1)s^2}{\chi^2_{\frac{\alpha}{2}}(n-1)},\frac{(n-1)s^2}{\chi^2_{1-\frac{\alpha}{2}}(n-1)}]
单侧置信区间:
- 左侧:[\frac{(n-1)s^2}{\chi^2_{\alpha}(n-1)},+\infty)
- 右侧:(-\infty,\frac{(n-1)s^2}{\chi^2_{1-\alpha}(n-1)}]
假设检验
统计检验量:\chi^2=\frac{(n-1)s^2}{\sigma_0^2}
注意检验时我们总是只比较统计检验量和右尾分位数\chi^2_{\alpha,df}
双变量
置信区间
枢轴量分布:\frac{s_1^2/\sigma_1^2}{s_2^2/\sigma_2^2}\sim F(n_1-1,n_2-1)
双侧置信区间:[\frac{s_1^2}{s_2^2}\frac{1}{F_{\frac{\alpha}{2}}(n_1-1,n_2-1)},\frac{s_1^2}{s_2^2}\frac{1}{F_{1-\frac{\alpha}{2}}(n_1-1,n_2-1)}]
单侧置信区间:
- 左侧:[\frac{s_1^2}{s_2^2}\frac{1}{F_{\alpha}(n_1-1,n_2-1)},+\infty)
- 右侧:(-\infty,\frac{s_1^2}{s_2^2}\frac{1}{F_{1-\alpha}(n_1-1,n_2-1)}]
假设检验
统计检验量:F=\frac{s_1^2}{s_2^2}
注:这里默认假设\sigma_1^2=\sigma_2^2\Rightarrow\frac{\sigma_1^2}{\sigma_2^2}=1,所以F分布中的\frac{\sigma_1^2}{\sigma_2^2}=1被消掉了,当\sigma_1^2\ne\sigma_2^2时情况变得复杂,这里不再讨论
使用F检验时,需要考虑:
- 在进行左侧检验(假设备择假设是1的总体方差小于2,即\sigma_1^2<\sigma_2^2)时:计算统计检验量\frac{s_1^2}{s_2^2},拒绝域在左侧,临界值为F_{1-\alpha}(n_1-1,n_2-1),但因为F分布一般不提供左侧分位数,故常需要通过F分布的性质转化为F_{1-\alpha}(n_1-1,n_2-1)=\frac{1}{F_{\alpha}(n_2-1,n_1-1)}。这整个过程等价于直接计算统计检验量\frac{s_2^2}{s_1^2}(反过来),之后考虑在右侧拒绝域检验,临界值为F_{\alpha}(n_2-1,n_1-1)
- 在进行左侧检验(备择假设\sigma_1^2>\sigma_2^2)时:计算统计检验量\frac{s_1^2}{s_2^2},拒绝域在右侧,临界值为F_{\alpha}(n_1-1,n_2-1)
- 在进行双边检验((备择假设\sigma_1^2\ne\sigma_2^2)时:计算统计检验量谁在分子上均可,但因为F分布的左侧分位数一般不提供,所以我们考虑人为的调整统计检验量让其偏右,即总是计算\frac{\max{(s_1^2,s_2^2)}}{\min{(s_1^2,s_2^2)}}并考虑右侧拒绝域,临界值为F_{\frac{\alpha}{2}}(n_{\arg\max_{(s_1^2,s_2^2)}}-1,n_{\arg\min_{(s_1^2,s_2^2)}}-1)
即,在非双边检验时,总是在统计检验量中将非备择假设中假设大的的总体方差所对应的样本方差放在分子。在双边检验中总是将实际大的样本方差放在分子,自由度根据分子和分母所代表的样本的样本数计算,拒绝域总是选在右侧(与在哪侧检验无关)
双配对样本均值检验(Paired t test)
这里只讨论总体标准差\sigma未知且样本量较小时的t配对检验,当总体标准差已知时可直接使用总体标准差\sigma进行检验,当总体标准差未知但样本量较大时可以使用样本标准差s代替\sigma进行检验
计算方法
- 对于每对样本(X_i,Y_i),计算差值d_i=X_i-Y_i得到一组差值\{d_1,d_2,\cdots,d_n\}
- 计算差值的均值\bar{d}和标准差s_d
::: align-center
\begin{aligned}&\bar{d}=\frac{1}{n}\sum_{i=1}^n d_i\\&s_d=\sqrt{\frac{\sum(d_i-\bar{d})^2}{n-1}}\end{aligned}
:::
3. 计算统计量\frac{\bar{d}-\mu_d}{s_d/\sqrt{n}},df=n-1
置信区间
枢轴量分布:\frac{\bar{d}-\mu_d}{s_d/\sqrt{n}}\sim t(n-1)
标准误:SE=\frac{s_d}{\sqrt{n}}
置信区间的构建方法与上面相同
假设检验
统计检验量:t=\frac{\bar{d}-\mu_d}{s_d/\sqrt{n}}
皮尔逊卡方检验
皮尔逊卡方检验和双配对检验非常相似,这里要注意区分
- 双配对检验适用于检验同一组对象在两个相关条件下的均值差异(比如同一组患者在服药前和服药后的血压的比较)
- 卡方检验适用于检验分布比例或变量间的关联性(比如性别与用手习惯是否有关(卡方独立性检验)、检验投骰子是否公平;检验总体是否是均匀分布(卡方拟合优度检验))
粗略地说:
- 双配对检验:涉及同一对象在不同时间/条件下的问题,处理“数值有无差异”的问题
- 卡方检验:不涉及配对比对的概念,处理“个数是否有无差异”的问题
计算方法
对于卡方拟合优度检验:
此种情况下需要按照假设计算期望频数E_i,零假设通常为符合分布,备择假设反之
之后计算统计检验量:
::: align-center
\chi^2=\sum\frac{(f_i-E_i)^2}{E_i}
:::
其中f_i是观察频数,自由度为类别数减1
对于卡方独立性检验:
此种情况下需要列联表检验,将样本统计列联表,零假设通常为两变量无关系(独立),备择假设反之
期望频数:
::: align-center
E_{ij}=\frac{(Number_{row})_i\times(Number_{col})_j}{Total}
:::
之后计算统计检验量:
::: align-center
\chi^2=\sum\frac{(O_{ij}-E_{ij})^2}{E_{ij}}
:::
其中O_{ij}是观察频数,自由度为列联表的(Number_{row}-1)\times (Number_{col}-1)
注意:卡方检验可用的前提是期望频数大于等于5,如发现期望频数小于5,可以采用合并类别等方法
注意检验时我们总是只比较统计检验量和右尾分位数\chi^2_{\alpha,df}
似然比检验
定义:设x_1,x_2,\cdots,x_n为来自已知总体概率密度函数为p(x;\theta),\theta\in \Theta的样本,考虑如下检验问题:
::: align-center
\begin{aligned}&H_0:\theta\in\Theta_0\\&H_1:\theta\in\Theta_1=\Theta-\Theta_0\end{aligned}
:::
令:
::: align-center
T(x_1,x_2,x_n)=\frac{\sup_{\theta\in\Theta}p(x_1,x_2,\cdots,x_n;\theta)}{\sup_{\theta\in\Theta_0}p(x_1,x_2,\cdots,x_n;\theta)}
:::
则我们称统计量T为上述假设的似然比(Likelihood Ratio)
有时似然比也可以写为如下形式:
::: align-center
T(x_1,x_2,x_n)=\frac{p(x_1,x_2,\cdots,x_n;\hat{\theta})}{p(x_1,x_2,\cdots,x_n;\hat{\theta}_0)}
:::
其中\hat{\theta}表示在全参数空间\Theta上\theta的极大似然估计,\hat{\theta}_0表示在子参数空间\Theta_o上\theta的极大似然估计,也就是说分子表示没有假设时的似然函数最大值,分母表示H_0成立时的似然函数最大值,不难看出,如果T的值很大则说明\theta\in\Theta_0的可能性要比\theta\in\Theta_1的可能性小,因此此时有理由认为H_0不成立,这样就有如下的似然比检验:
定义(似然比检验):当采用上式的似然比统计量T作为检验问题的统计量,且取拒绝域为W=\{\Lambda(x_1,x_2,\cdots,x_n)\ge c\},其中临界值c满足:
::: align-center
P_\theta\{\Lambda(x_1,x_2,\cdots,x_n)\ge c\}\le\alpha,\forall\theta\in\Theta_0
:::
则称此检验为显著性水平\alpha的似然比检验(Likelihood ratio test, LRT)
(正态总体样本的LRT)设x_1,x_2,\cdots,x_n是来自正态总体N(\mu,\sigma^2)的样本,\mu,\sigma^2均未知,试求检验问题:
::: align-center
\begin{aligned}&H_0:\mu=\mu_0\\&H_1:\mu\ne\mu_0\end{aligned}
:::
的显著性水平为\alpha的似然比检验
记\theta=(\mu,\theta^2),则样本联合密度函数为:
::: align-center
(2\pi\sigma^2)^{-\frac{1}{2}}\exp\{-\frac{1}{2\sigma^2}\sum_{i=1}^n(x_i-\mu)^2\}
:::
两个参数空间分别为\Theta_0=\{(\mu_0,\sigma^2)|\sigma^2>0\},\Theta=\{(\mu,\sigma^2)|\mu\in\mathbb{R},\sigma^2>0\}
使用解析法可以求得在\Theta上\hat{\mu}=\bar{x},\hat{\sigma}^2=\frac{1}{n}\sum_{i=1}^n(x_i-\bar{x})^2分别为\mu和\sigma^2的MLE,而在\Theta_0上为\mu_0和\frac{1}{n}\sum_{i=1}^n(x_i-\mu_0)^2,代回各自的似然函数(对数似然函数)后,可得:
::: align-center
\begin{aligned}&\sup_{\theta\in\Theta_0}p(x_1,x_2,\cdots,x_n;\theta)=[2\pi\frac{1}{n}\sum_{i=1}^n(x_i-\mu_0)^2]^{-\frac{n}{2}}e^{-\frac{n}{2}}\\&\sup_{\theta\in\Theta}p(x_1,x_2,\cdots,x_n;\theta)=[2\pi\frac{1}{n}\sum_{i=1}^n(x_i-\bar{x})^2]^{-\frac{n}{2}}e^{-\frac{n}{2}}
\end{aligned}
:::
于是,其似然比统计量为:
::: align-center
\Lambda=(\frac{\sum_{i=1}^n(x_i-\mu_0)^2}{\sum_{i=1}^n(x_i-\bar{x})^2})^{\frac{n}{2}}=(\frac{\sum_{i=1}^n(x_i-\bar{x})^2+n(\bar{x}-\mu_0)^2}{\sum_{i=1}^n(x_i-\bar{x})^2})^{\frac{n}{2}}=(1+\frac{t^2}{n-1})^{\frac{n}{2}}
:::
其中t=\frac{\bar{x}-\mu_0}{s/\sqrt{n}}就是t检验的统计检验量
从上式可知,此时的似然比统计量\Lambda是传统的t检验统计量平方的严增函数,于是两个检验统计量的拒绝域有如下的等价关系:
::: align-center
\{\Lambda\ge c\}\Leftrightarrow \{|t|\ge d\}
:::
且由t分位数可定出\Lambda的分位数,当H_0成立时取d=t_{1-\alpha/2,n-1},则使用c=(1+\frac{d^2}{n-1})^{\frac{n}{2}}可以控制用\Lambda犯第一类错误的概率不超过\alpha,此时的似然比检验与t检验完全等价
另外,当样本量足够大时,负对数似然比统计检验量2\ln \Lambda由Wilks定理近似于\chi^2(r),其中r为H_0约束变量的个数
某些教材会使用T=\frac{L(\theta_0)}{L(\hat{\theta})}并在之后取-2\ln T,结果是相同的
注意检验时我们总是只比较统计检验量和右尾分位数\chi^2_{\alpha,df}
统计功效
回忆第一类和第二类错误
第一类错误(Type I Error,去真):
::: align-center
\alpha=P(\text{Accept }H_1|H_0\text{ is true})
:::
e.g. 原假设H_0:\mu=0,从上帝视角看确实真正的\mu=0,结果我们从样本得到的数据计算出的统计检验量拒绝了H_0
第二类错误(Type II Error,存伪)
::: align-center
\beta=P(\text{Accept }H_0|H_1\text{ is true})
:::
e.g. 原假设H_0:\mu=0,从上帝视角看其实真正的\mu=1,结果我们从样本得到的数据计算出的统计检验量没有拒绝H_0
在做假设检验是我们通常使用的是\alpha(越小显著性越强),但严格意义下\beta却难以调控,我们可以得出“原假设正确时我们尽可能确保它真的是正确的”,但是我们没法说“备择假设正确时我们能尽可能拒绝原假设”
更深层次的原因是:通常我们的备择假设H_1是复合(Compisite) (比如\mu>\mu_0)的而不是简单(Simple) (比如\mu=\mu_0)的,这就导致备择假设可能对应无数个概率分布而不是单一的概率空间(当备择假设为简单假设,比如\mu=\mu_0时我们可以较为方便的计算P(\text{Accept }H_0|\mu=\mu_0),但是当备择假设为复合假设时,计算诸如P(\text{Accept }H_0|\mu>\mu_0)的算式就较为困难了
所以,我们引入了统计功效(Power)
功效函数
引入
统计功效(Power) 指的是不犯第二类错误的概率,因此总有
::: align-center
\text{Power} + \beta = 1
:::
因此统计功效越高,越不容易犯第二类错误,但通常统计功效不是单纯的越高越好(因为第一和第二类错误通常是有相关性的,一味的追求提高统计功效可能会增大犯第一类错误的概率)
功效函数的图像
现在我们给出一个最为简单的情形,总体分布已知为正态分布,,均值未知,\sigma^2=100,给出样本量n=100,检验均值,假设为:
::: align-center
\begin{aligned}
&H_0:\mu=0\\
&H_1:\mu=m(\text{简单假设,}m\ne 0)
\end{aligned}
:::
因为总体分布已知,使用Z检验,此时统计检验量为:
::: align-center
z=\frac{\bar{X}-0}{\sqrt{100}/10}=\bar{X}
:::
此时考虑原假设成立,假设\mu=0,而总体方差已知为100,所以\bar{X}\sim N(0,\frac{100}{100})=N(0,1)
这是个双边检验,拒绝域为\backslash(-z_{\alpha/2},z_{\alpha/2})
此时我们计算统计功效,也就是假设H_1成立(\mu = m)时接受H_0(检验量没有落到拒绝域)的概率,即P\{z\notin(-z_{\alpha/2},z_{\alpha/2})|\mu=m\}
此时z=\bar{X}\sim(m,1),那么
::: align-center
Power(m)=P\{z\notin(-z_{\alpha/2},z_{\alpha/2})|\mu=m\}=P\{|Z+m|
:::
其中\Phi是标准正态分布的CDF
此时画出Power(m)的图像,为:
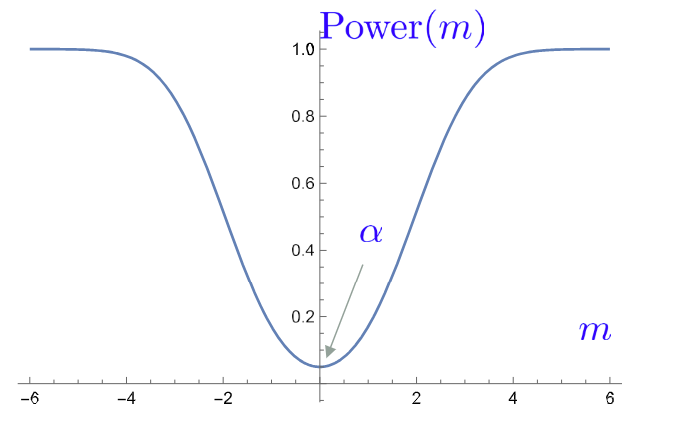
注意当m=\mu_0=0时(实际上不会,因为假设中m严格不等于0),Power(m)的值就是犯第一类错误的概率\alpha,当m离\mu_0=0越来越远时,此功效函数越来越趋近于其上确界1,即功效趋近于1,犯第二类错误的概率趋近0
第一和第二类错误之间的平衡
但是,一味的追求高统计功效不一定好,我们画出上面问题中统计检验量的图像:
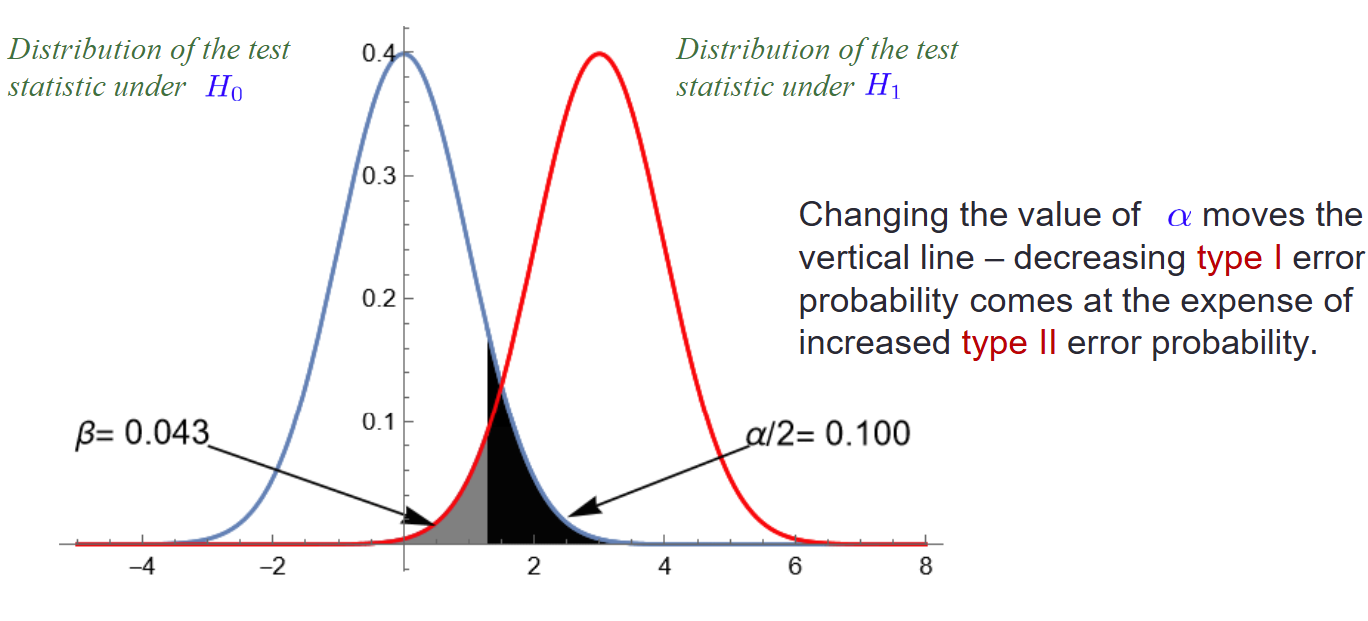
H_0成立时为标准正态分布图(蓝),而H_1成立时因为均值变为了m(假设m>0),所以偏右(红),此时犯第一类错误的右尾为黑色部分,犯第二类错误的左尾为灰色部分,如果我们追求更高的显著性,也就是减小\alpha,坐标轴上的z_{\alpha/2}会右移以确保黑色部分的面积变小,但是此时灰色部分的面积在此图上就会变大了,特别地,如果此时我们的m还离\mu_0=0特别近(假设m=1),那么灰色部分的\beta会特别大,对应的,此时这个检验的统计功效就会特别小:
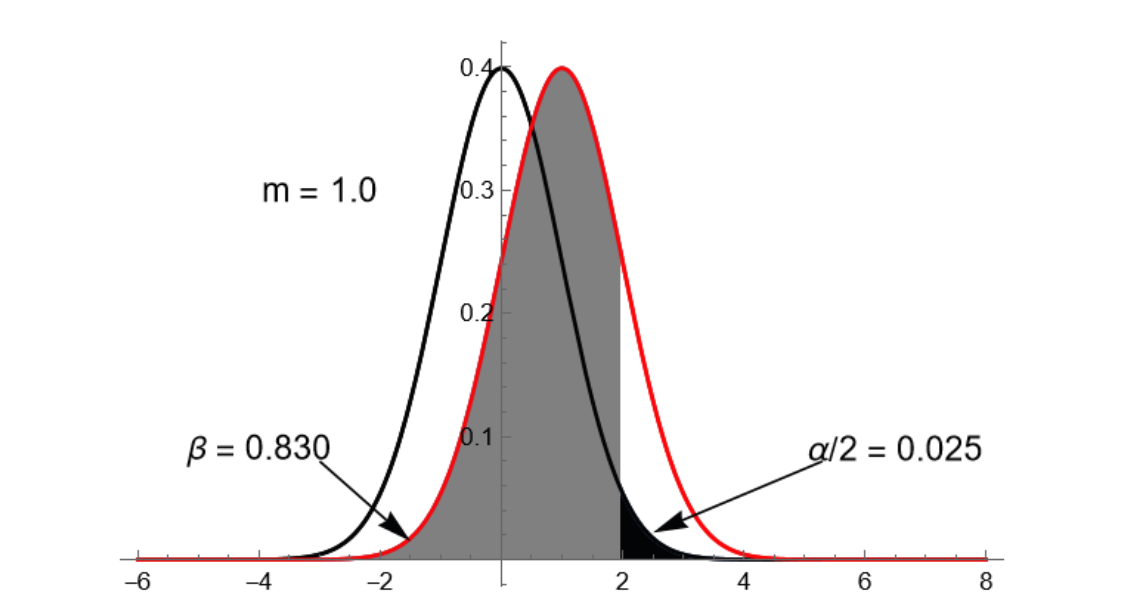
在这个假设下,高显著性是以牺牲功效换来的,通俗地讲,因为我们不知道总体的均值是多少,所以我们做假设检验,当假设总体均值为\mu_0,如果用样本算出来的统计检验量落在了右侧拒绝域,我们拒绝H_0多半不会有问题(很显著),但是假如总体的均值实际其实是m,我们算出来的统计检验量多半是不会落在左侧拒绝域的(功效很低)
所以,一个好的假设检验,应该同时保证较高的显著性和在一系列m上都较为高的统计功效(具体m怎么选,依实际问题而定,你说的算),在图像上表现为红蓝两条函数尽可能的分开,此时这个假设检验是相对优秀的
显著性已知时确定统计功效的一般方式
这里以正态总体的单独立样本均值检验为例,总体\mu未知,方差\sigma^2已知,显著性水平\alpha已知,则总体的分布为N(\mu,\sigma^2),则其样本的均值分布为N(\mu,\frac{\sigma^2}{n})(如果总体分布未知而样本量足够大,则由林德贝格-列维中心极限定理依然可以假设样本符合此正态分布)
此时我们再计算统计检验量(Z检验)的分布,因为
::: align-center
z=\frac{\bar{X}-\mu_0}{\sigma/\sqrt{n}}=\frac{\sqrt{n}}{\sigma}\bar{X}-\frac{\sqrt{n}}{\sigma}\mu_0
:::
其中\mu_0来自于原假设(\mu=\mu_0)
在备择假设H_1:\mu=\mu_1成立时,\bar{X}\sim N(\mu_1,\frac{\sigma^2}{n}),此时统计检验量的分布由期望和方差的线性性得到为:
::: align-center
z\sim N(\frac{\sqrt{n}}{\sigma}(\mu_1-\mu_0),1)
:::
其中\frac{\sqrt{n}}{\sigma}=\frac{1}{SE},在实际计算中只需要对标准误取倒数即可(SE一般在前面的检验中已经获得),而不需要重新计算
之后即可计算统计功效:
::: align-center
\text{Power}=P(|z|>z_{\alpha/2}|\mu=\mu_1)=1-P(|z|
:::
显著性和统计功效已知时确定所需最小样本量的一般方式
还是以上面的正态总体的单独立样本均值检验为例,假设\alpha,\beta已知,假如检验问题是一个单尾检验且备择假设是简单假设(H_0:\mu=\mu_0,H_1:\mu=\mu_1(\mu_1>\mu_0))
此时我们看H_1知道拒绝域是在右尾的,设样本量为n,拒绝样本均值的临界值为k,则\alpha(也就是犯第一类错误的概率,在H_0成立时样本均值落在临界值k的右侧时)可解释为:
::: align-center
\alpha=P(\bar{X}>k|\mu=\mu_0)=P(Z>\frac{k-\\\mu_0}{\sigma/\sqrt{n}})
:::
则有\frac{k-\mu_0}{\sigma/\sqrt{n}}=z_{\alpha}
\beta(也就是犯第二类错误的概率,在H_1成立时样本均值没有落在临界值k的右侧时)可解释为:
::: align-center
\beta=P(\bar{X}\le k|\mu=\mu_1)=P(Z\le\frac{k-\mu_1}{\sigma/\sqrt{n}})
:::
则有\frac{k-\mu_1}{\sigma/\sqrt{n}}=-z_{\beta}
这将得到两个方程,之后先解出n(如果n不是整数,取\lceil n\rceil),如果需要k再代入n求出k即可
在H_1为左尾简单假设时类似,需要修改\alpha表达式为P(\bar{X}
全部评论 (0)
暂无评论,快来抢沙发吧~