目标
简介
设计一个Molang解释器,将Molang脚本解释为对应操作,并在运行时调用获得求得的值
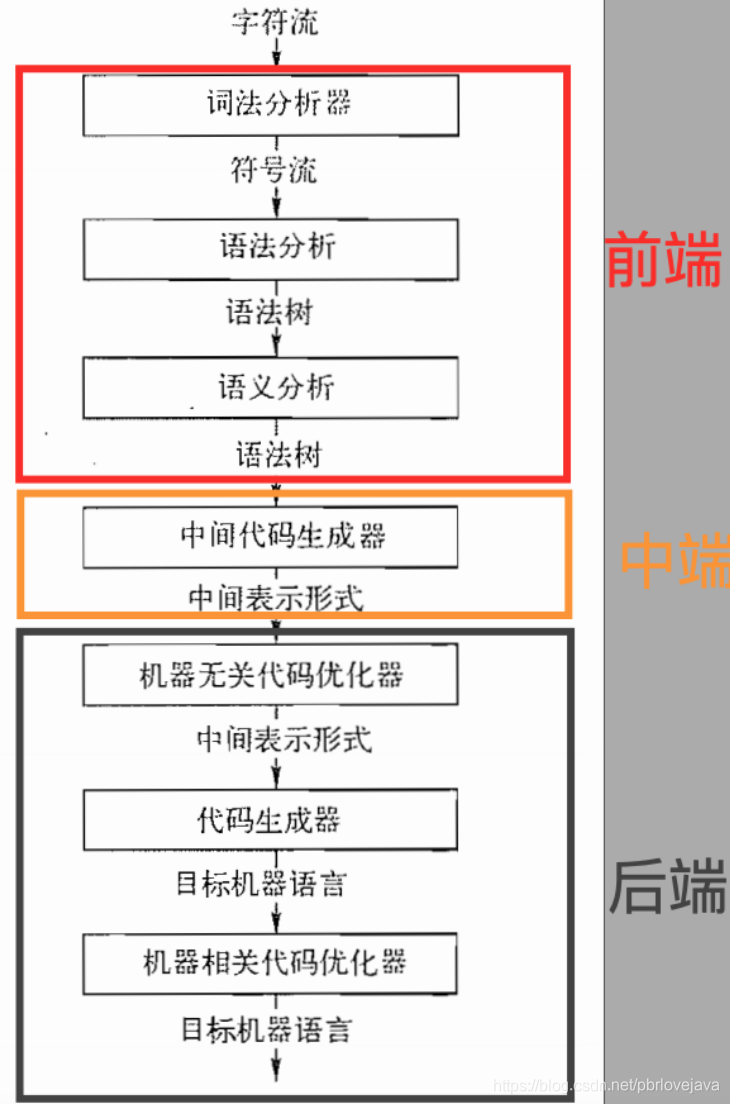
按照编译原理的过程,我们需要实现前端部分,中后端我们直接调用Java实现对应的操作,不转为机器码,即我们的这个解析器主要将Molang脚本解析为Java操作
注意:本文的解释器不完整,它只用于解析暴雪粒子,尤其是缺少if,for,while这样的控制流语句解析,因此仅供学习,切勿使用到生产环境
更为完整的解释器请查看AW的Molang虚拟机,或者MoonFlower的Molang编译器(直接将Molang编译为JVM字节码),或者更原生的带JIT的Rust Molang解释/编译器
功能
基元类型
- 数字类型
- 42 // 整数
- 3.14159 // 浮点数
- .5 // 小数(等价于 0.5)
- -123.456 // 负数
- 字符串类型
- "hello" // 字符串字面量
- "a" + "b" // 字符串拼接 → "ab"
- 布尔类型(通过数字模拟)
- 0 // false
- 非0 // true
- x > 5 // 比较返回 1 或 0
- NaN 处理
- 未初始化变量 // 默认值为 NaN
- x ?? 10 // 空值合并:如果 x 是 NaN,返回 10
函数
- 基础数学函数
- abs(-5) // 绝对值 → 5
- floor(3.7) // 向下取整 → 3
- ceil(3.2) // 向上取整 → 4
- round(3.6) // 四舍五入 → 4
- trunc(3.9) // 截断小数 → 3
- sqrt(16) // 平方根 → 4
- exp(1) // e^x → 2.718...
- ln(2.718) // 自然对数 → 1
- pow(2, 10) // 幂函数 → 1024
- mod(17, 5) // 模运算 → 2
- 范围限制函数
- min(1, 5, 3, 9) // 最小值 → 1
- max(1, 5, 3, 9) // 最大值 → 9
- clamp(15, 0, 10) // 限制范围 → 10
- 三角函数(度数制)
- sin(30) // 正弦 → 0.5 (注意是度数,不是弧度)
- cos(60) // 余弦 → 0.5
- asin(0.5) // 反正弦 → 30 (返回度数)
- acos(0.5) // 反余弦 → 60
- atan(1) // 反正切 → 45
- atan2(1, 1) // 双参数反正切 → 45
- 插值函数
- lerp(0, 100, 0.5) // 线性插值 → 50
- lerprotate(10, 350, 0.5) // 角度插值(最短路径) → 0
- hermite(0.5) // Hermite 平滑曲线 → 0.5
- 随机函数
- random(0, 100) // 随机浮点数 [0, 100)
- randomi(1, 6) // 随机整数 [1, 6],模拟骰子
- roll(6) // 掷骰子:1/6 概率返回 1,否则 0
- rolli(2, 6) // 掷 2 次 6 面骰子,返回点数
- 函数别名
所有函数都支持 math. 前缀:
- math.sin(45) // 等价于 sin(45)
- math.random(0, 1) // 等价于 random(0, 1)
- math.random_integer // 别名:randomi
- math.die_roll // 别名:roll
- math.hermite_blend // 别名:hermite
- 自定义函数注册:允许用户自定义函数注册 (在表达式解析前)
变量
- 普通变量
- variable.health // 访问变量
- v.health // 短名称(自动展开为 variable.health)
- 查询变量(只读)
- query.life_time // 查询生命周期
- q.life_time // 短名称(自动展开为 query.life_time)
- 临时变量(每帧清理)
- temp.x = 5 // 临时存储
- t.x // 短名称(自动展开为 temp.x)
- 短名称自动展开
- v.test → variable.test
- q.age → query.age
- t.calc → temp.calc
- 数组变量(在解析表达式前手动注册)
- colors[0] // 访问第一个元素
- colors[-1] // 负索引:访问最后一个元素
- colors[10] // 循环索引:超出范围会取模
其他优化
- 表达式缓存:同一个表达式字符串只会解析一次
- 预热优化:预先编译常用表达式
- 常量优化:
colors[3] // 索引 3 在编译时就确定
colors[v.index] // 索引是变量,运行时计算
开始!
词法分析
首先定义Token类型:
Token 类型枚举
- 字面量:NUMBER(123等), STRING(""括起来的字符串), IDENTIFIER(标识符)
- 运算符:PLUS(+), MINUS(-), MULTIPLY(*), DIVIDE(/), POWER(**), MODULO(%)
- 比较运算符:EQUAL(==), NOT_EQUAL(!=), LESS(<), GREATER(>), LESS_EQUAL(<=),GREATER_EQUAL(>=)
- 逻辑运算符:AND(&&), OR(||), NOT(!)
- 位运算符:BIT_AND(&), BIT_OR(|), BIT_XOR(^^), LEFT_SHIFT(<<), RIGHT_SHIFT(>>)
- 特殊运算符:NULL_COALESCE(??), QUESTION(?), COLON(:)
- 括号:LPAREN((), RPAREN()), LBRACKET([), RBRACKET(])
- 分隔符:COMMA(,), SEMICOLON(;), ASSIGN(=)
java
package com.molang.math.parser;
/**
* Token 类型枚举
*/
public enum Token {
// 结束符
EOF,
// 字面量
NUMBER,
STRING,
IDENTIFIER,
// 括号
LPAREN, // (
RPAREN, // )
LBRACKET, // [
RBRACKET, // ]
// 运算符
PLUS, // +
MINUS, // -
MULTIPLY, // *
DIVIDE, // /
MODULO, // %
POWER, // ^
// 比较运算符
EQUAL, // ==
NOT_EQUAL, // !=
LESS, // <
LESS_EQUAL, // <=
GREATER, // >
GREATER_EQUAL, // >=
// 逻辑运算符
AND, // &&
OR, // ||
NOT, // !
// 位运算符
BIT_AND, // &
BIT_OR, // |
BIT_XOR, // ^^
LEFT_SHIFT, // <<
RIGHT_SHIFT, // >>
// 特殊运算符
NULL_COALESCE, // ??
QUESTION, // ?
COLON, // :
// 分隔符
COMMA, // ,
SEMICOLON, // ;
ASSIGN // =
}之后开始实现词法分析器,由DFA实现
- 跳过空白字符
- 根据首字符判断Token类型,按照优先级
- 数字/小数点(123或.123):扫描数字
- 双引号("):扫描字符串
- 字母/下划线(abc,_abc):扫描标识符
- 双字符运算符:优先考虑
- 根据读取到的类型判断是否属于某个Token类型,如果属于则改变状态
currenToken - 提供相应的Token获取方法给后面的语法分析
优先级顺序有限考虑
- 空白字符
- 结束符EOF
- 数字,避免歧义,比如运算符比数字优先级更高时.5会被解析为 字符(.) NUMBER(5),而.在我们的Token中不存在,这就会导致错误
- 字符串,比如标识符若比字符串优先级更高会出现"hello"被解析成 字符(") IDENTIFIER(hello) 字符("),而"在我们的Token中并不存在,这就会导致错误
- 标识符,比如variable.test如果运算符优先会被拆为 IDENTIFIER(variable) 字符(.) IDENTIFIER(test)
- 双运算符,比如果单运算符=的优先级高于双运算符==,那么==就会被解析为 ASSIGN ASSIGN而不是EQUAL
- 单运算符
现在实现词法分析的核心方法:读取下一个Token
java
/**
* 读取下一个 Token
*/
public Token nextToken() {
skipWhitespace();
if (pos >= source.length()) {
currentToken = Token.EOF;
return currentToken;
}
char c = source.charAt(pos);
tokenStart = pos;
// 数字
if (Character.isDigit(c) || (c == '.' && pos + 1 < source.length() && Character.isDigit(source.charAt(pos + 1)))) {
return scanNumber();
}
// 字符串
if (c == '"') {
return scanString();
}
// 标识符
if (Character.isLetter(c) || c == '_') {
return scanIdentifier();
}
// 双字符运算符
if (pos + 1 < source.length()) {
String twoChar = source.substring(pos, pos + 2);
Token token = matchTwoCharOperator(twoChar);
if (token != null) {
pos += 2;
tokenEnd = pos;
currentToken = token;
return token;
}
}
// 单字符运算符
pos++;
tokenEnd = pos;
currentToken = matchSingleCharOperator(c);
return currentToken;
}- 先跳过空格
- 判断是否超出字符串索引,超出就设当前Token为结束符,结束
- 判断是否是数字(数字或.数字),是就扫描并结束当前Token检查
- 判断是否是字符串("打头),是就扫描并结束当前Token检查
- 判断是否是标识符(字符打头或_打头),是就扫描并结束当前Token检查
- 判断是否是单字符运算符,是就扫描并结束当前Token检查
- 都不是,设为null
对于跳过空格的分问题:
死循环,只要当前索引的字符是是空字符,且没有越界就一直向后
java
private void skipWhitespace() {
while (pos < source.length() && Character.isWhitespace(source.charAt(pos))) {
pos++;
}
}对于判断数字的分问题,只要是数字或者.指针pos就移动到当前位置,直到不是,设置当前Token类型为NUMBER,token结束为pos(方便后边和tokenStart一块取Token解析用),返回Token类型:
java
private Token scanNumber() {
while (pos < source.length()) {
char c = source.charAt(pos);
if (Character.isDigit(c) || c == '.') {
pos++;
} else {
break;
}
}
tokenEnd = pos;
currentToken = Token.NUMBER;
return currentToken;
}对于判断字符串分问题,直接往后扫到结尾的"出现之前为止就行,如果字符串没结束把指针pos再向后移一位跳过结尾的",注意token开始和token结束需要把前面的"和后面的"都跳了,也就是tokenStart是开始的指针位置pos加1,tokenEnd要在指针pos后移一位跳过尾部"之前设置
java
private Token scanString() {
pos++; // 跳过开头的 "
tokenStart = pos;
while (pos < source.length() && source.charAt(pos) != '"') {
pos++;
}
tokenEnd = pos;
if (pos < source.length()) {
pos++; // 跳过结尾的 "
}
currentToken = Token.STRING;
return currentToken;
}对于标识符分问题,没什么说法,只要是字母或者_或者.(标识符里就允许出现这仨)就一直往后扫
java
private Token scanIdentifier() {
while (pos < source.length()) {
char c = source.charAt(pos);
if (Character.isLetterOrDigit(c) || c == '_' || c == '.') {
pos++;
} else {
break;
}
}
tokenEnd = pos;
currentToken = Token.IDENTIFIER;
return currentToken;
}之后对于双运算符分问题,这时候指针不能直接后移扫了,需要先peek一下后面的两个字符判断是否是双运算符,如果是(即不返回null)指针pos直接后移两位,然后改变状态currentToken,tokenEnd
java
private Token matchTwoCharOperator(String op) {
return switch (op) {
case "==" -> Token.EQUAL;
case "!=" -> Token.NOT_EQUAL;
case "<=" -> Token.LESS_EQUAL;
case ">=" -> Token.GREATER_EQUAL;
case "&&" -> Token.AND;
case "||" -> Token.OR;
case "^^" -> Token.BIT_XOR;
case "<<" -> Token.LEFT_SHIFT;
case ">>" -> Token.RIGHT_SHIFT;
case "??" -> Token.NULL_COALESCE;
default -> null;
};
}最后,再判断单运算符,这时候如果再不匹配那就是脚本语法有问题,就可以直接返回结束符了。如果是改变状态
java
private Token matchSingleCharOperator(char c) {
return switch (c) {
case '+' -> Token.PLUS;
case '-' -> Token.MINUS;
case '*' -> Token.MULTIPLY;
case '/' -> Token.DIVIDE;
case '%' -> Token.MODULO;
case '^' -> Token.POWER;
case '<' -> Token.LESS;
case '>' -> Token.GREATER;
case '!' -> Token.NOT;
case '&' -> Token.BIT_AND;
case '|' -> Token.BIT_OR;
case '?' -> Token.QUESTION;
case ':' -> Token.COLON;
case '(' -> Token.LPAREN;
case ')' -> Token.RPAREN;
case '[' -> Token.LBRACKET;
case ']' -> Token.RBRACKET;
case ',' -> Token.COMMA;
case ';' -> Token.SEMICOLON;
case '=' -> Token.ASSIGN;
default -> Token.EOF;
};
}最后整个词法分析器的代码:
java
package com.molang.math.parser;
/**
* 词法分析器
*
* 零分配设计,直接在原字符串上操作
*/
public class Lexer {
private final String source;
private int pos;
private Token currentToken;
private int tokenStart;
private int tokenEnd;
public Lexer(String source) {
this.source = source.toLowerCase();
this.pos = 0;
this.currentToken = Token.EOF;
}
/**
* 读取下一个 Token
*/
public Token nextToken() {
skipWhitespace();
if (pos >= source.length()) {
currentToken = Token.EOF;
return currentToken;
}
char c = source.charAt(pos);
tokenStart = pos;
// 数字
if (Character.isDigit(c) || (c == '.' && pos + 1 < source.length() && Character.isDigit(source.charAt(pos + 1)))) {
return scanNumber();
}
// 字符串
if (c == '"') {
return scanString();
}
// 标识符
if (Character.isLetter(c) || c == '_') {
return scanIdentifier();
}
// 双字符运算符
if (pos + 1 < source.length()) {
String twoChar = source.substring(pos, pos + 2);
Token token = matchTwoCharOperator(twoChar);
if (token != null) {
pos += 2;
tokenEnd = pos;
currentToken = token;
return token;
}
}
// 单字符运算符
pos++;
tokenEnd = pos;
currentToken = matchSingleCharOperator(c);
return currentToken;
}
private Token scanNumber() {
while (pos < source.length()) {
char c = source.charAt(pos);
if (Character.isDigit(c) || c == '.') {
pos++;
} else {
break;
}
}
tokenEnd = pos;
currentToken = Token.NUMBER;
return currentToken;
}
private Token scanString() {
pos++; // 跳过开头的 "
tokenStart = pos;
while (pos < source.length() && source.charAt(pos) != '"') {
pos++;
}
tokenEnd = pos;
if (pos < source.length()) {
pos++; // 跳过结尾的 "
}
currentToken = Token.STRING;
return currentToken;
}
private Token scanIdentifier() {
while (pos < source.length()) {
char c = source.charAt(pos);
if (Character.isLetterOrDigit(c) || c == '_' || c == '.') {
pos++;
} else {
break;
}
}
tokenEnd = pos;
currentToken = Token.IDENTIFIER;
return currentToken;
}
private void skipWhitespace() {
while (pos < source.length() && Character.isWhitespace(source.charAt(pos))) {
pos++;
}
}
private Token matchTwoCharOperator(String op) {
return switch (op) {
case "==" -> Token.EQUAL;
case "!=" -> Token.NOT_EQUAL;
case "<=" -> Token.LESS_EQUAL;
case ">=" -> Token.GREATER_EQUAL;
case "&&" -> Token.AND;
case "||" -> Token.OR;
case "^^" -> Token.BIT_XOR;
case "<<" -> Token.LEFT_SHIFT;
case ">>" -> Token.RIGHT_SHIFT;
case "??" -> Token.NULL_COALESCE;
default -> null;
};
}
private Token matchSingleCharOperator(char c) {
return switch (c) {
case '+' -> Token.PLUS;
case '-' -> Token.MINUS;
case '*' -> Token.MULTIPLY;
case '/' -> Token.DIVIDE;
case '%' -> Token.MODULO;
case '^' -> Token.POWER;
case '<' -> Token.LESS;
case '>' -> Token.GREATER;
case '!' -> Token.NOT;
case '&' -> Token.BIT_AND;
case '|' -> Token.BIT_OR;
case '?' -> Token.QUESTION;
case ':' -> Token.COLON;
case '(' -> Token.LPAREN;
case ')' -> Token.RPAREN;
case '[' -> Token.LBRACKET;
case ']' -> Token.RBRACKET;
case ',' -> Token.COMMA;
case ';' -> Token.SEMICOLON;
case '=' -> Token.ASSIGN;
default -> Token.EOF;
};
}
/**
* 获取当前 Token
*/
public Token getCurrentToken() {
return currentToken;
}
/**
* 获取当前 Token 的数字值
*/
public double getNumber() {
return Double.parseDouble(source.substring(tokenStart, tokenEnd));
}
/**
* 获取当前 Token 的字符串值
*/
public String getString() {
return source.substring(tokenStart, tokenEnd);
}
/**
* 检查当前位置
*/
public int getPosition() {
return pos;
}
}语法分析
拿到Token以后还需要进行语法分析,语法分析主要负责递归向下构造抽象语法树(AST),构造计算图,比如:
- 输入:variable.x > 10 ? math.sin(45) * 2 : 0
- 词法分析→ Token流: IDENTIFIER(variable.x) GREATER NUMBER(10) QUESTION IDENTIFIER(math.sin) LPAREN NUMBER(45) RPAREN MULTIPLY NUMBER(2) COLON NUMBER(0) EOF
- 语法分析 AST被包装为三元运算根,条件,左右操作为包装为子结点,接着递归向下。所有的字面量被包装为Value,所有的变量被包装为Var,含有函数的IDENTIFIER被包装为FuncCall
plaintext
TernaryOp
/ | \
GREATER | Value(0)
/ \ |
Var(x) Value(10) MUL
/ \
FuncCall 2
(sin, 45)优先级:
- 优先级 0:三元运算符 ?:,包装为三元运算TernaryOp
- 优先级 1:空值合并 ??,包装为二元运算BinaryOp
- 优先级 3:逻辑与 &&,包装为二元运算BinaryOp
- 优先级 4:位或 |,包装为二元运算BinaryOp
- 优先级 5:位异或 ^^,包装为二元运算BinaryOp
- 优先级 6:位与 &,包装为二元运算BinaryOp
- 优先级 7:比较运算符 ==, !=, <, <=, >, >=,包装为二元运算BinaryOp
- 优先级 8:位移 <<, >>,包装为二元运算BinaryOp
- 优先级 9:加减 +, -,包装为二元运算BinaryOp
- 优先级 10:乘除模 *, /, %,包装为二元运算BinaryOp
- 优先级 11:幂运算 ^,包装为二元运算BinaryOp
- 优先级 12:一元运算符 !, -,包装为一元运算UnaryOp
- 优先级 13:基本元素(数字、变量、函数、括号、数组)
- 优先级1:数字字面量,包装为Value
- 优先级2:字符串字面量,包装为Value
- 优先级3:左括号((数学上的),返回开始从三元运算符开始解析
- 优先级4:标识符
到这里先取Token值转为String,作为标识符的名字,然后查下一个Token- 优先级1:函数调用(通过检查现在还有没有左括号(来实现,如果现在还有左括号(那一定是出现在标识符中的函数调用中的形参列表中的左括号),如果有则名字解析为函数名,()中的部分分割为实参,分别再从头从三元运算开始递归向下解析,最后把结果包装成函数调用句柄FunctionCall
- 优先级2:数组访问(通过检查现在还有没有左括号[来实现,如果现在还有左括号(那一定是出现在标识符中的数组访问的左括号)如果有则名字解析为数组变量,[]中的部分为数组索引推导式,从头从三元运算开始向下递归解析,最后把结果包装成数组访问运算ArrayAccess
- 优先级3:上面都没有,那现在此标识符只能是普通变量,包装为变量Variable
- 结束,最后返回一个Expression对象,三元运算TernaryOp,二元运算BinaryOp,一元运算UnaryOp,函数句柄FunctionCall,数组访问运算ArrayAccess都是它的继承类,其中每个运算中的被操作对象,函数句柄中传入的每个实参对象又是一个Expression对象,这样就构成了树的结构
java
package com.molang.math.operator;
import com.molang.math.core.Expression;
/**
* 三元运算符
*
* condition ? ifTrue : ifFalse
*/
public class TernaryOp implements Expression {
private final Expression condition;
private final Expression ifTrue;
private final Expression ifFalse;
public TernaryOp(Expression condition, Expression ifTrue, Expression ifFalse) {
this.condition = condition;
this.ifTrue = ifTrue;
this.ifFalse = ifFalse;
}
@Override
public double evaluate() {
return condition.evaluateBoolean() ? ifTrue.evaluate() : ifFalse.evaluate();
}
@Override
public String evaluateString() {
return condition.evaluateBoolean() ? ifTrue.evaluateString() : ifFalse.evaluateString();
}
@Override
public String toString() {
return "(" + condition + " ? " + ifTrue + " : " + ifFalse + ")";
}
}
java
package com.molang.math.operator;
import com.molang.math.core.Expression;
/**
* 二元运算符
*/
public class BinaryOp implements Expression {
public enum Type {
// 算术运算
ADD("+", 4),
SUB("-", 4),
MUL("*", 5),
DIV("/", 5),
MOD("%", 5),
POW("^", 6),
// 比较运算
EQUAL("==", 2),
NOT_EQUAL("!=", 2),
LESS("<", 3),
LESS_EQUAL("<=", 3),
GREATER(">", 3),
GREATER_EQUAL(">=", 3),
// 逻辑运算
AND("&&", 1),
OR("||", 0),
// 位运算
BIT_AND("&", 2),
BIT_OR("|", 2),
BIT_XOR("^^", 2),
LEFT_SHIFT("<<", 4),
RIGHT_SHIFT(">>", 4),
// 特殊运算
NULL_COALESCE("??", -1);
private final String symbol;
private final int precedence;
Type(String symbol, int precedence) {
this.symbol = symbol;
this.precedence = precedence;
}
public String getSymbol() {
return symbol;
}
public int getPrecedence() {
return precedence;
}
public double calculate(double a, double b) {
return switch (this) {
case ADD -> a + b;
case SUB -> a - b;
case MUL -> a * b;
case DIV -> a / b;
case MOD -> a % b;
case POW -> Math.pow(a, b);
case EQUAL -> a == b ? 1 : 0;
case NOT_EQUAL -> a != b ? 1 : 0;
case LESS -> a < b ? 1 : 0;
case LESS_EQUAL -> a <= b ? 1 : 0;
case GREATER -> a > b ? 1 : 0;
case GREATER_EQUAL -> a >= b ? 1 : 0;
case AND -> (a != 0 && b != 0) ? 1 : 0;
case OR -> (a != 0 || b != 0) ? 1 : 0;
case BIT_AND -> (long) a & (long) b;
case BIT_OR -> (long) a | (long) b;
case BIT_XOR -> (long) a ^ (long) b;
case LEFT_SHIFT -> (long) a << (long) b;
case RIGHT_SHIFT -> (long) a >> (long) b;
case NULL_COALESCE -> Double.isNaN(a) ? b : a;
};
}
}
private final Type type;
private final Expression left;
private final Expression right;
public BinaryOp(Type type, Expression left, Expression right) {
this.type = type;
this.left = left;
this.right = right;
}
@Override
public double evaluate() {
return type.calculate(left.evaluate(), right.evaluate());
}
@Override
public String evaluateString() {
// 特殊处理字符串拼接
if (type == Type.ADD) {
return left.evaluateString() + right.evaluateString();
}
return String.valueOf(evaluate());
}
@Override
public String toString() {
return "(" + left + " " + type.symbol + " " + right + ")";
}
}
java
package com.molang.math.operator;
import com.molang.math.core.Expression;
/**
* 一元运算符
*/
public class UnaryOp implements Expression {
public enum Type {
NEGATE("!"), // 逻辑非
NEGATIVE("-"); // 算术负
private final String symbol;
Type(String symbol) {
this.symbol = symbol;
}
public String getSymbol() {
return symbol;
}
public double calculate(double value) {
return switch (this) {
case NEGATE -> value != 0 ? 0 : 1;
case NEGATIVE -> -value;
};
}
}
private final Type type;
private final Expression operand;
public UnaryOp(Type type, Expression operand) {
this.type = type;
this.operand = operand;
}
@Override
public double evaluate() {
return type.calculate(operand.evaluate());
}
@Override
public String toString() {
return type.symbol + operand;
}
}
java
package com.molang.math.function;
import com.molang.math.core.Expression;
/**
* 函数调用表达式
*/
public class FunctionCall implements Expression {
private final String name;
private final Function function;
private final Expression[] args;
public FunctionCall(String name, Function function, Expression[] args) {
this.name = name;
this.function = function;
this.args = args;
}
@Override
public double evaluate() {
return function.execute(args);
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder(name).append("(");
for (int i = 0; i < args.length; i++) {
if (i > 0) sb.append(", ");
sb.append(args[i]);
}
return sb.append(")").toString();
}
}
java
package com.molang.math.core;
/**
* 数组访问表达式
*
* array[index]
*/
public class ArrayAccess implements Expression {
private final ArrayVariable array;
private final Expression index;
private final Integer constantIndex;
public ArrayAccess(ArrayVariable array, Expression index) {
this.array = array;
this.index = index;
// 优化:如果索引是常量,预先计算
this.constantIndex = index.isConstant() ? (int) index.evaluate() : null;
}
@Override
public double evaluate() {
int idx = constantIndex != null ? constantIndex : (int) index.evaluate();
return array.getAt(idx);
}
@Override
public String toString() {
return array.getName() + "[" + index + "]";
}
}它们都继承了统一的表达式接口
java
package com.molang.math.core;
/**
* 表达式接口
*
* 所有数学表达式的基础接口,支持求值和类型转换
*/
public interface Expression {
/**
* 求值为 double
*/
double evaluate();
/**
* 求值为 boolean(0 为 false,非 0 为 true)
*/
default boolean evaluateBoolean() {
return evaluate() != 0;
}
/**
* 求值为 String
*/
default String evaluateString() {
return String.valueOf(evaluate());
}
/**
* 是否为常量表达式
*/
default boolean isConstant() {
return false;
}
}开始统一解析为double,而后的布尔及String转换再分别处理
首先是三元运算解析,在这之前递归向下解析下一优先级的空值合并,等下一优先级的空置合并解析完毕后(这时假如存在三元运算 条件 ? 是 : 否,条件应该已经解析完毕了),查当前Token是否是问号?如果是,跳下一个Token(是)接着从头递归向下解析,等待解析完毕后再查是否有引号:,如果是,跳下一个Token(否)接着从头递归向下解析。如果出现问题抛出异常,没出现问题包装为三元运算TernaryOp
java
/**
* 优先级 0:三元运算符 ?:
*/
private Expression parseTernary(Lexer lexer) throws ParseException {
Expression condition = parseNullCoalesce(lexer);
if (lexer.getCurrentToken() == Token.QUESTION) {
lexer.nextToken();
Expression ifTrue = parseTernary(lexer);
if (lexer.getCurrentToken() != Token.COLON) {
throw new ParseException("Expected ':' in ternary operator", lexer.getPosition());
}
lexer.nextToken();
Expression ifFalse = parseTernary(lexer);
return new TernaryOp(condition, ifTrue, ifFalse);
}
return condition;
}接着是解析空值合并??,在这之前先递归向下解析下一优先级的逻辑或||,解析完毕后查当前Token是否是空值合并运算符??,并包装为二元运算BinaryOp,这里套了个while用于在前面的Token们解析完毕后再尝试解析后面的
java
/**
* 优先级 1:空值合并 ??
*/
private Expression parseNullCoalesce(Lexer lexer) throws ParseException {
Expression left = parseLogicalOr(lexer);
while (lexer.getCurrentToken() == Token.NULL_COALESCE) {
lexer.nextToken();
Expression right = parseLogicalOr(lexer);
left = new BinaryOp(BinaryOp.Type.NULL_COALESCE, left, right);
}
return left;
}之后一直到一元运算符之前都是这样
java
/**
* 优先级 2:逻辑或 ||
*/
private Expression parseLogicalOr(Lexer lexer) throws ParseException {
Expression left = parseLogicalAnd(lexer);
while (lexer.getCurrentToken() == Token.OR) {
lexer.nextToken();
Expression right = parseLogicalAnd(lexer);
left = new BinaryOp(BinaryOp.Type.OR, left, right);
}
return left;
}
/**
* 优先级 3:逻辑与 &&
*/
private Expression parseLogicalAnd(Lexer lexer) throws ParseException {
Expression left = parseBitwiseOr(lexer);
while (lexer.getCurrentToken() == Token.AND) {
lexer.nextToken();
Expression right = parseBitwiseOr(lexer);
left = new BinaryOp(BinaryOp.Type.AND, left, right);
}
return left;
}
/**
* 优先级 4:位或 |
*/
private Expression parseBitwiseOr(Lexer lexer) throws ParseException {
Expression left = parseBitwiseXor(lexer);
while (lexer.getCurrentToken() == Token.BIT_OR) {
lexer.nextToken();
Expression right = parseBitwiseXor(lexer);
left = new BinaryOp(BinaryOp.Type.BIT_OR, left, right);
}
return left;
}
/**
* 优先级 5:位异或 ^^
*/
private Expression parseBitwiseXor(Lexer lexer) throws ParseException {
Expression left = parseBitwiseAnd(lexer);
while (lexer.getCurrentToken() == Token.BIT_XOR) {
lexer.nextToken();
Expression right = parseBitwiseAnd(lexer);
left = new BinaryOp(BinaryOp.Type.BIT_XOR, left, right);
}
return left;
}
/**
* 优先级 6:位与 &
*/
private Expression parseBitwiseAnd(Lexer lexer) throws ParseException {
Expression left = parseComparison(lexer);
while (lexer.getCurrentToken() == Token.BIT_AND) {
lexer.nextToken();
Expression right = parseComparison(lexer);
left = new BinaryOp(BinaryOp.Type.BIT_AND, left, right);
}
return left;
}
/**
* 优先级 7:比较运算符 ==, !=, <, <=, >, >=
*/
private Expression parseComparison(Lexer lexer) throws ParseException {
Expression left = parseShift(lexer);
Token token = lexer.getCurrentToken();
while (token == Token.EQUAL || token == Token.NOT_EQUAL ||
token == Token.LESS || token == Token.LESS_EQUAL ||
token == Token.GREATER || token == Token.GREATER_EQUAL) {
BinaryOp.Type opType = switch (token) {
case EQUAL -> BinaryOp.Type.EQUAL;
case NOT_EQUAL -> BinaryOp.Type.NOT_EQUAL;
case LESS -> BinaryOp.Type.LESS;
case LESS_EQUAL -> BinaryOp.Type.LESS_EQUAL;
case GREATER -> BinaryOp.Type.GREATER;
case GREATER_EQUAL -> BinaryOp.Type.GREATER_EQUAL;
default -> throw new ParseException("Unexpected comparison operator", lexer.getPosition());
};
lexer.nextToken();
Expression right = parseShift(lexer);
left = new BinaryOp(opType, left, right);
token = lexer.getCurrentToken();
}
return left;
}
/**
* 优先级 8:位移 <<, >>
*/
private Expression parseShift(Lexer lexer) throws ParseException {
Expression left = parseAddSub(lexer);
Token token = lexer.getCurrentToken();
while (token == Token.LEFT_SHIFT || token == Token.RIGHT_SHIFT) {
BinaryOp.Type opType = token == Token.LEFT_SHIFT ?
BinaryOp.Type.LEFT_SHIFT : BinaryOp.Type.RIGHT_SHIFT;
lexer.nextToken();
Expression right = parseAddSub(lexer);
left = new BinaryOp(opType, left, right);
token = lexer.getCurrentToken();
}
return left;
}
/**
* 优先级 9:加减 +, -
*/
private Expression parseAddSub(Lexer lexer) throws ParseException {
Expression left = parseMulDiv(lexer);
Token token = lexer.getCurrentToken();
while (token == Token.PLUS || token == Token.MINUS) {
BinaryOp.Type opType = token == Token.PLUS ? BinaryOp.Type.ADD : BinaryOp.Type.SUB;
lexer.nextToken();
Expression right = parseMulDiv(lexer);
left = new BinaryOp(opType, left, right);
token = lexer.getCurrentToken();
}
return left;
}
/**
* 优先级 10:乘除模 *, /, %
*/
private Expression parseMulDiv(Lexer lexer) throws ParseException {
Expression left = parsePower(lexer);
Token token = lexer.getCurrentToken();
while (token == Token.MULTIPLY || token == Token.DIVIDE || token == Token.MODULO) {
BinaryOp.Type opType = switch (token) {
case MULTIPLY -> BinaryOp.Type.MUL;
case DIVIDE -> BinaryOp.Type.DIV;
case MODULO -> BinaryOp.Type.MOD;
default -> throw new ParseException("Unexpected operator", lexer.getPosition());
};
lexer.nextToken();
Expression right = parsePower(lexer);
left = new BinaryOp(opType, left, right);
token = lexer.getCurrentToken();
}
return left;
}
/**
* 优先级 11:幂运算 ^
*/
private Expression parsePower(Lexer lexer) throws ParseException {
Expression left = parseUnary(lexer);
if (lexer.getCurrentToken() == Token.POWER) {
lexer.nextToken();
Expression right = parsePower(lexer); // 右结合
return new BinaryOp(BinaryOp.Type.POW, left, right);
}
return left;
}一元运算符直接查Token是否是一元运算:
java
/**
* 优先级 12:一元运算符 !, -
*/
private Expression parseUnary(Lexer lexer) throws ParseException {
Token token = lexer.getCurrentToken();
if (token == Token.NOT) {
lexer.nextToken();
return new UnaryOp(UnaryOp.Type.NEGATE, parseUnary(lexer));
}
if (token == Token.MINUS) {
lexer.nextToken();
return new UnaryOp(UnaryOp.Type.NEGATIVE, parseUnary(lexer));
}
return parsePrimary(lexer);
}最后到最底下是解析标识符
java
/**
* 优先级 13:基本元素(数字、变量、函数、括号、数组)
*/
private Expression parsePrimary(Lexer lexer) throws ParseException {
Token token = lexer.getCurrentToken();
// 数字
if (token == Token.NUMBER) {
double value = lexer.getNumber();
lexer.nextToken();
return new Value(value);
}
// 字符串
if (token == Token.STRING) {
String value = lexer.getString();
lexer.nextToken();
return new Value(value);
}
// 括号
if (token == Token.LPAREN) {
lexer.nextToken();
Expression expr = parseTernary(lexer);
if (lexer.getCurrentToken() != Token.RPAREN) {
throw new ParseException("Expected ')'", lexer.getPosition());
}
lexer.nextToken();
return expr;
}
// 标识符(变量、函数、数组)
if (token == Token.IDENTIFIER) {
String name = lexer.getString();
lexer.nextToken();
// 函数调用
if (lexer.getCurrentToken() == Token.LPAREN) {
return parseFunction(lexer, name);
}
// 数组访问
if (lexer.getCurrentToken() == Token.LBRACKET) {
return parseArrayAccess(lexer, name);
}
// 变量
return context.getVariable(name);
}
throw new ParseException("Unexpected token: " + token, lexer.getPosition());
}函数解析通过下方代码实现:
java
/**
* 解析函数调用
*/
private Expression parseFunction(Lexer lexer, String name) throws ParseException {
lexer.nextToken(); // 跳过 (
List<Expression> args = new ArrayList<>();
if (lexer.getCurrentToken() != Token.RPAREN) {
args.add(parseTernary(lexer));
while (lexer.getCurrentToken() == Token.COMMA) {
lexer.nextToken();
args.add(parseTernary(lexer));
}
}
if (lexer.getCurrentToken() != Token.RPAREN) {
throw new ParseException("Expected ')' in function call", lexer.getPosition());
}
lexer.nextToken();
Function func = functions.getFunction(name);
if (func == null) {
throw new ParseException("Unknown function: " + name, lexer.getPosition());
}
return new FunctionCall(name, func, args.toArray(new Expression[0]));
}函数名通过检查函数注册表中的哈希表缓存实现,函数注册表是支持用户注册自定义函数的:
java
package com.molang.math.function;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
/**
* 数学函数注册表
*
* 包含所有内置函数的实现
*/
public class MathFunctions {
private final Map<String, Function> functions = new HashMap<>();
private final Random random = new Random();
public MathFunctions() {
registerAllFunctions();
}
/**
* 获取函数
*/
public Function getFunction(String name) {
return functions.get(name);
}
/**
* 注册函数
*/
public void register(String name, Function function) {
functions.put(name, function);
}
private void registerAllFunctions() {
// 基础数学函数
register("abs", args -> Math.abs(args[0].evaluate()));
register("floor", args -> Math.floor(args[0].evaluate()));
register("ceil", args -> Math.ceil(args[0].evaluate()));
register("round", args -> Math.round(args[0].evaluate()));
register("trunc", args -> (double) (long) args[0].evaluate());
register("sqrt", args -> Math.sqrt(args[0].evaluate()));
register("exp", args -> Math.exp(args[0].evaluate()));
register("ln", args -> Math.log(args[0].evaluate()));
register("pow", args -> Math.pow(args[0].evaluate(), args[1].evaluate()));
register("mod", args -> args[0].evaluate() % args[1].evaluate());
// 限制函数
register("min", args -> {
double min = args[0].evaluate();
for (int i = 1; i < args.length; i++) {
min = Math.min(min, args[i].evaluate());
}
return min;
});
register("max", args -> {
double max = args[0].evaluate();
for (int i = 1; i < args.length; i++) {
max = Math.max(max, args[i].evaluate());
}
return max;
});
register("clamp", args -> {
double value = args[0].evaluate();
double min = args[1].evaluate();
double max = args[2].evaluate();
return Math.max(min, Math.min(max, value));
});
// 三角函数(度数制)
register("sin", args -> Math.sin(Math.toRadians(args[0].evaluate())));
register("cos", args -> Math.cos(Math.toRadians(args[0].evaluate())));
register("asin", args -> Math.toDegrees(Math.asin(args[0].evaluate())));
register("acos", args -> Math.toDegrees(Math.acos(args[0].evaluate())));
register("atan", args -> Math.toDegrees(Math.atan(args[0].evaluate())));
register("atan2", args -> Math.toDegrees(Math.atan2(args[0].evaluate(), args[1].evaluate())));
// 插值函数
register("lerp", args -> {
double start = args[0].evaluate();
double end = args[1].evaluate();
double t = args[2].evaluate();
return start + (end - start) * t;
});
register("lerprotate", args -> {
double start = args[0].evaluate();
double end = args[1].evaluate();
double t = args[2].evaluate();
double diff = ((end - start) % 360 + 540) % 360 - 180;
return start + diff * t;
});
register("hermite", args -> {
double t = args[0].evaluate();
return t * t * (3 - 2 * t);
});
// 随机函数
register("random", args -> {
double min = args[0].evaluate();
double max = args[1].evaluate();
return min + random.nextDouble() * (max - min);
});
register("randomi", args -> {
int min = (int) args[0].evaluate();
int max = (int) args[1].evaluate();
return min + random.nextInt(max - min + 1);
});
register("roll", args -> {
int sides = (int) args[0].evaluate();
return random.nextDouble() < 1.0 / sides ? 1 : 0;
});
register("rolli", args -> {
int rolls = (int) args[0].evaluate();
int sides = (int) args[1].evaluate();
return random.nextInt(sides) + 1;
});
// 注册 math.xxx 别名
registerMathAliases();
}
private void registerMathAliases() {
String[] names = {
"abs", "floor", "ceil", "round", "trunc", "sqrt", "exp", "ln",
"pow", "mod", "min", "max", "clamp",
"sin", "cos", "asin", "acos", "atan", "atan2",
"lerp", "lerprotate", "hermite",
"random", "randomi", "roll", "rolli"
};
for (String name : names) {
Function func = functions.get(name);
if (func != null) {
functions.put("math." + name, func);
}
}
// 额外的别名
functions.put("math.random_integer", functions.get("randomi"));
functions.put("math.die_roll", functions.get("roll"));
functions.put("math.die_roll_integer", functions.get("rolli"));
functions.put("math.hermite_blend", functions.get("hermite"));
}
}其中每个函数都实现了函数接口,这个接口提供了统一的execute方法
java
package com.molang.math.function;
import com.molang.math.core.Expression;
/**
* 函数接口
*
* 所有数学函数的基础接口
*/
@FunctionalInterface
public interface Function {
/**
* 执行函数
*
* @param args 参数列表
* @return 计算结果
*/
double execute(Expression[] args);
}数组解析类似:
java
/**
* 解析数组访问
*/
private Expression parseArrayAccess(Lexer lexer, String name) throws ParseException {
Variable var = context.getVariable(name);
if (!(var instanceof ArrayVariable)) {
throw new ParseException("Variable '" + name + "' is not an array", lexer.getPosition());
}
lexer.nextToken(); // 跳过 [
Expression index = parseTernary(lexer);
if (lexer.getCurrentToken() != Token.RBRACKET) {
throw new ParseException("Expected ']' in array access", lexer.getPosition());
}
lexer.nextToken();
return new ArrayAccess((ArrayVariable) var, index);
}其中数组的变量是特殊的ArrayVariable,它继承了Variable
java
package com.molang.math.core;
/**
* 数组变量
*
* 存储 double 数组,支持负索引和越界安全
*/
public class ArrayVariable extends Variable {
private final double[] values;
public ArrayVariable(String name, double[] values) {
super(name);
this.values = values;
}
/**
* 获取数组长度
*/
public int getLength() {
return values.length;
}
/**
* 获取指定索引的值
*
* 支持负索引(-1 表示最后一个元素)
* 越界返回 0
*/
public double getAt(int index) {
if (values.length == 0) {
return 0;
}
// 负索引支持
if (index < 0) {
index = values.length + index;
}
// 循环索引(模运算)
index = index % values.length;
if (index < 0) {
index += values.length;
}
return values[index];
}
/**
* 设置指定索引的值
*/
public void setAt(int index, double value) {
if (values.length == 0) {
return;
}
if (index < 0) {
index = values.length + index;
}
index = index % values.length;
if (index < 0) {
index += values.length;
}
values[index] = value;
}
@Override
public double evaluate() {
return values.length > 0 ? values[0] : 0;
}
@Override
public String toString() {
return getName() + "[" + values.length + "]";
}
}语法分析器的完整代码
java
package com.molang.math.parser;
import com.molang.math.core.*;
import com.molang.math.function.Function;
import com.molang.math.function.FunctionCall;
import com.molang.math.function.MathFunctions;
import com.molang.math.operator.BinaryOp;
import com.molang.math.operator.TernaryOp;
import com.molang.math.operator.UnaryOp;
import java.util.ArrayList;
import java.util.List;
/**
* 表达式解析器
*
* 使用递归下降解析,构建表达式树
*/
public class ExpressionParser {
private final ExpressionContext context;
private final MathFunctions functions;
public ExpressionParser(ExpressionContext context, MathFunctions functions) {
this.context = context;
this.functions = functions;
}
/**
* 解析表达式
*/
public Expression parse(String input) throws ParseException {
Lexer currentLexer = new Lexer(input);
return parseExpression(currentLexer);
}
private Expression parseExpression(Lexer lexer) throws ParseException {
lexer.nextToken();
return parseTernary(lexer);
}
/**
* 优先级 0:三元运算符 ?:
*/
private Expression parseTernary(Lexer lexer) throws ParseException {
Expression condition = parseNullCoalesce(lexer);
if (lexer.getCurrentToken() == Token.QUESTION) {
lexer.nextToken();
Expression ifTrue = parseTernary(lexer);
if (lexer.getCurrentToken() != Token.COLON) {
throw new ParseException("Expected ':' in ternary operator", lexer.getPosition());
}
lexer.nextToken();
Expression ifFalse = parseTernary(lexer);
return new TernaryOp(condition, ifTrue, ifFalse);
}
return condition;
}
/**
* 优先级 1:空值合并 ??
*/
private Expression parseNullCoalesce(Lexer lexer) throws ParseException {
Expression left = parseLogicalOr(lexer);
while (lexer.getCurrentToken() == Token.NULL_COALESCE) {
lexer.nextToken();
Expression right = parseLogicalOr(lexer);
left = new BinaryOp(BinaryOp.Type.NULL_COALESCE, left, right);
}
return left;
}
/**
* 优先级 2:逻辑或 ||
*/
private Expression parseLogicalOr(Lexer lexer) throws ParseException {
Expression left = parseLogicalAnd(lexer);
while (lexer.getCurrentToken() == Token.OR) {
lexer.nextToken();
Expression right = parseLogicalAnd(lexer);
left = new BinaryOp(BinaryOp.Type.OR, left, right);
}
return left;
}
/**
* 优先级 3:逻辑与 &&
*/
private Expression parseLogicalAnd(Lexer lexer) throws ParseException {
Expression left = parseBitwiseOr(lexer);
while (lexer.getCurrentToken() == Token.AND) {
lexer.nextToken();
Expression right = parseBitwiseOr(lexer);
left = new BinaryOp(BinaryOp.Type.AND, left, right);
}
return left;
}
/**
* 优先级 4:位或 |
*/
private Expression parseBitwiseOr(Lexer lexer) throws ParseException {
Expression left = parseBitwiseXor(lexer);
while (lexer.getCurrentToken() == Token.BIT_OR) {
lexer.nextToken();
Expression right = parseBitwiseXor(lexer);
left = new BinaryOp(BinaryOp.Type.BIT_OR, left, right);
}
return left;
}
/**
* 优先级 5:位异或 ^^
*/
private Expression parseBitwiseXor(Lexer lexer) throws ParseException {
Expression left = parseBitwiseAnd(lexer);
while (lexer.getCurrentToken() == Token.BIT_XOR) {
lexer.nextToken();
Expression right = parseBitwiseAnd(lexer);
left = new BinaryOp(BinaryOp.Type.BIT_XOR, left, right);
}
return left;
}
/**
* 优先级 6:位与 &
*/
private Expression parseBitwiseAnd(Lexer lexer) throws ParseException {
Expression left = parseComparison(lexer);
while (lexer.getCurrentToken() == Token.BIT_AND) {
lexer.nextToken();
Expression right = parseComparison(lexer);
left = new BinaryOp(BinaryOp.Type.BIT_AND, left, right);
}
return left;
}
/**
* 优先级 7:比较运算符 ==, !=, <, <=, >, >=
*/
private Expression parseComparison(Lexer lexer) throws ParseException {
Expression left = parseShift(lexer);
Token token = lexer.getCurrentToken();
while (token == Token.EQUAL || token == Token.NOT_EQUAL ||
token == Token.LESS || token == Token.LESS_EQUAL ||
token == Token.GREATER || token == Token.GREATER_EQUAL) {
BinaryOp.Type opType = switch (token) {
case EQUAL -> BinaryOp.Type.EQUAL;
case NOT_EQUAL -> BinaryOp.Type.NOT_EQUAL;
case LESS -> BinaryOp.Type.LESS;
case LESS_EQUAL -> BinaryOp.Type.LESS_EQUAL;
case GREATER -> BinaryOp.Type.GREATER;
case GREATER_EQUAL -> BinaryOp.Type.GREATER_EQUAL;
default -> throw new ParseException("Unexpected comparison operator", lexer.getPosition());
};
lexer.nextToken();
Expression right = parseShift(lexer);
left = new BinaryOp(opType, left, right);
token = lexer.getCurrentToken();
}
return left;
}
/**
* 优先级 8:位移 <<, >>
*/
private Expression parseShift(Lexer lexer) throws ParseException {
Expression left = parseAddSub(lexer);
Token token = lexer.getCurrentToken();
while (token == Token.LEFT_SHIFT || token == Token.RIGHT_SHIFT) {
BinaryOp.Type opType = token == Token.LEFT_SHIFT ?
BinaryOp.Type.LEFT_SHIFT : BinaryOp.Type.RIGHT_SHIFT;
lexer.nextToken();
Expression right = parseAddSub(lexer);
left = new BinaryOp(opType, left, right);
token = lexer.getCurrentToken();
}
return left;
}
/**
* 优先级 9:加减 +, -
*/
private Expression parseAddSub(Lexer lexer) throws ParseException {
Expression left = parseMulDiv(lexer);
Token token = lexer.getCurrentToken();
while (token == Token.PLUS || token == Token.MINUS) {
BinaryOp.Type opType = token == Token.PLUS ? BinaryOp.Type.ADD : BinaryOp.Type.SUB;
lexer.nextToken();
Expression right = parseMulDiv(lexer);
left = new BinaryOp(opType, left, right);
token = lexer.getCurrentToken();
}
return left;
}
/**
* 优先级 10:乘除模 *, /, %
*/
private Expression parseMulDiv(Lexer lexer) throws ParseException {
Expression left = parsePower(lexer);
Token token = lexer.getCurrentToken();
while (token == Token.MULTIPLY || token == Token.DIVIDE || token == Token.MODULO) {
BinaryOp.Type opType = switch (token) {
case MULTIPLY -> BinaryOp.Type.MUL;
case DIVIDE -> BinaryOp.Type.DIV;
case MODULO -> BinaryOp.Type.MOD;
default -> throw new ParseException("Unexpected operator", lexer.getPosition());
};
lexer.nextToken();
Expression right = parsePower(lexer);
left = new BinaryOp(opType, left, right);
token = lexer.getCurrentToken();
}
return left;
}
/**
* 优先级 11:幂运算 ^
*/
private Expression parsePower(Lexer lexer) throws ParseException {
Expression left = parseUnary(lexer);
if (lexer.getCurrentToken() == Token.POWER) {
lexer.nextToken();
Expression right = parsePower(lexer); // 右结合
return new BinaryOp(BinaryOp.Type.POW, left, right);
}
return left;
}
/**
* 优先级 12:一元运算符 !, -
*/
private Expression parseUnary(Lexer lexer) throws ParseException {
Token token = lexer.getCurrentToken();
if (token == Token.NOT) {
lexer.nextToken();
return new UnaryOp(UnaryOp.Type.NEGATE, parseUnary(lexer));
}
if (token == Token.MINUS) {
lexer.nextToken();
return new UnaryOp(UnaryOp.Type.NEGATIVE, parseUnary(lexer));
}
return parsePrimary(lexer);
}
/**
* 优先级 13:基本元素(数字、变量、函数、括号、数组)
*/
private Expression parsePrimary(Lexer lexer) throws ParseException {
Token token = lexer.getCurrentToken();
// 数字
if (token == Token.NUMBER) {
double value = lexer.getNumber();
lexer.nextToken();
return new Value(value);
}
// 字符串
if (token == Token.STRING) {
String value = lexer.getString();
lexer.nextToken();
return new Value(value);
}
// 括号
if (token == Token.LPAREN) {
lexer.nextToken();
Expression expr = parseTernary(lexer);
if (lexer.getCurrentToken() != Token.RPAREN) {
throw new ParseException("Expected ')'", lexer.getPosition());
}
lexer.nextToken();
return expr;
}
// 标识符(变量、函数、数组)
if (token == Token.IDENTIFIER) {
String name = lexer.getString();
lexer.nextToken();
// 函数调用
if (lexer.getCurrentToken() == Token.LPAREN) {
return parseFunction(lexer, name);
}
// 数组访问
if (lexer.getCurrentToken() == Token.LBRACKET) {
return parseArrayAccess(lexer, name);
}
// 变量
return context.getVariable(name);
}
throw new ParseException("Unexpected token: " + token, lexer.getPosition());
}
/**
* 解析函数调用
*/
private Expression parseFunction(Lexer lexer, String name) throws ParseException {
lexer.nextToken(); // 跳过 (
List<Expression> args = new ArrayList<>();
if (lexer.getCurrentToken() != Token.RPAREN) {
args.add(parseTernary(lexer));
while (lexer.getCurrentToken() == Token.COMMA) {
lexer.nextToken();
args.add(parseTernary(lexer));
}
}
if (lexer.getCurrentToken() != Token.RPAREN) {
throw new ParseException("Expected ')' in function call", lexer.getPosition());
}
lexer.nextToken();
Function func = functions.getFunction(name);
if (func == null) {
throw new ParseException("Unknown function: " + name, lexer.getPosition());
}
return new FunctionCall(name, func, args.toArray(new Expression[0]));
}
/**
* 解析数组访问
*/
private Expression parseArrayAccess(Lexer lexer, String name) throws ParseException {
Variable var = context.getVariable(name);
if (!(var instanceof ArrayVariable)) {
throw new ParseException("Variable '" + name + "' is not an array", lexer.getPosition());
}
lexer.nextToken(); // 跳过 [
Expression index = parseTernary(lexer);
if (lexer.getCurrentToken() != Token.RBRACKET) {
throw new ParseException("Expected ']' in array access", lexer.getPosition());
}
lexer.nextToken();
return new ArrayAccess((ArrayVariable) var, index);
}
}解释器
现在我们开始正式设计解释器
脚本上下文
首先我们先设计脚本解释过程中的上下文类,它每次解释都new一个新的,主要用于保存变量
java
package com.molang.math.core;
import java.util.HashMap;
import java.util.Map;
/**
* 表达式上下文
*
* 管理变量、数组和 temp 变量
*/
public class ExpressionContext {
private final Map<String, Variable> variables = new HashMap<>();
private final Map<String, Variable> tempVariables = new HashMap<>();
/**
* 获取或创建变量
*/
public Variable getVariable(String name) {
// temp 变量特殊处理
if (name.startsWith("temp.")) {
return tempVariables.computeIfAbsent(name, n -> new Variable(n, Double.NaN));
}
// 短名称展开
name = expandShortName(name);
// 普通变量
return variables.computeIfAbsent(name, n -> new Variable(n, Double.NaN));
}
/**
* 注册数组变量
*/
public ArrayVariable registerArray(String name, double[] values) {
ArrayVariable array = new ArrayVariable(name, values);
variables.put(name, array);
return array;
}
/**
* 设置变量值
*/
public void setValue(String name, double value) {
getVariable(name).set(value);
}
/**
* 清理 temp 变量
*/
public void clearTempVariables() {
tempVariables.clear();
}
/**
* 获取 temp 变量数量
*/
public int getTempVariableCount() {
return tempVariables.size();
}
/**
* 展开短名称
*/
private String expandShortName(String name) {
if (name.length() > 2 && name.charAt(1) == '.') {
char prefix = name.charAt(0);
String suffix = name.substring(2);
return switch (prefix) {
case 'q' -> "query." + suffix;
case 'v' -> "variable." + suffix;
case 't' -> "temp." + suffix;
default -> name;
};
}
return name;
}
}在ExpressionParser中被语法分析分析为Variable或ArrayVariable的变量会调用此处的getVariable方法注册后存储在哈希表中。
用户可以在脚本正式解释前通过registerArray注册自己的数组,通过setValue声明脚本内没有声明的变量并设置值,这两个方法用于需要动态传入数组和新变量的情况。需要注意的是我们的解释器没有设计脚本内赋值语句的解析,因此所有的变量都是通过这两个方法传入的
脚本缓存
这里我们采用两层缓存
一层小容量热缓存通过哈希表直接实现O(1)查找,每次查都会自增访问次数,如果访问次数大于阈值且数据在冷缓存内,我们就将其升级到热缓存。如果热缓存被穿透了,我们接着检查大容量冷缓存,冷缓存由java集合类中的LinkedHashMap实现,它内部通过维护一个双向链表存储了元素存入的顺序,我们重写它的removeEldestEntry方法使得它在超出75%容量后自动把最先存入的元素删掉,这样就实现了LRU缓存策略。如果冷缓存也没有找到脚本的值,那我们不得不运行解析,在解析后我们将值存入冷缓存
另外提供两个方法
- 预热方法:用于在用户已知此脚本会被大量调用的先验知识时,提前将脚本解析一遍后加入热缓存
- GC方法:用于用户用于在一定调用程度后手动调用清空冷缓存中调用数较少的脚本
java
package com.molang.math.molang;
import com.molang.math.core.Expression;
import org.jetbrains.annotations.NotNull;
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Map;
/**
* MoLang 表达式缓存
*
* 两级缓存:热点缓存 + LRU 冷缓存
*/
public class MolangCache {
private final Map<String, Expression> hotCache;
private final LinkedHashMap<String, Expression> coldCache;
private final Map<String, Integer> accessCount;
private long hits = 0;
private long misses = 0;
private static final int HOT_THRESHOLD = 10;
public MolangCache() {
this.hotCache = new HashMap<>(64);
this.coldCache = new LinkedHashMap<>(256) {
@Override
protected boolean removeEldestEntry(Map.Entry<String, Expression> eldest) {
return size() > 256 * 0.75;
}
};
this.accessCount = new HashMap<>();
}
/**
* 获取缓存的表达式
*/
public Expression get(String expression) {
// 检查热点缓存
Expression hot = hotCache.get(expression);
if (hot != null) {
hits++;
return hot;
}
// 检查冷缓存
Expression cold = coldCache.get(expression);
if (cold != null) {
hits++;
// 统计访问次数
int count = accessCount.merge(expression, 1, Integer::sum);
// 访问频繁,升级到热点缓存
if (count >= HOT_THRESHOLD) {
hotCache.put(expression, cold);
}
return cold;
}
misses++;
return null;
}
/**
* 放入缓存
*/
public void put(String expression, Expression compiled) {
coldCache.put(expression, compiled);
accessCount.put(expression, 1);
}
/**
* 清空缓存
*/
public void clear() {
hotCache.clear();
coldCache.clear();
accessCount.clear();
}
/**
* 垃圾回收(移除低频表达式)
*/
public void gc() {
coldCache.entrySet().removeIf(entry -> {
Integer count = accessCount.get(entry.getKey());
return count == null || count < 2;
});
}
/**
* 预热缓存
*/
public void warmup(String expression, Expression compiled) {
hotCache.put(expression, compiled);
}
/**
* 获取统计信息
*/
public CacheStats getStats() {
return new CacheStats(hits, misses, hotCache.size(), coldCache.size());
}
/**
* 重置统计
*/
public void resetStats() {
hits = 0;
misses = 0;
}
/**
* 缓存统计数据
*/
public record CacheStats(long hits, long misses, int hotSize, int coldSize) {
public double getHitRate() {
long total = hits + misses;
return total == 0 ? 0 : (double) hits / total;
}
@Override
public @NotNull String toString() {
return String.format(
"""
缓存状态:
解析次数: %d
命中: %d (%.2f%%)
穿透: %d
Hot Cache: %d/64
Cold Cache: %d/256
""",
hits + misses,
hits, getHitRate() * 100,
misses,
hotSize,
coldSize
);
}
}
}脚本解析器
最后,脚本解析器封装上下文和缓存,提供统一的解析方法,调用语法分析器的方法分析语法,得到解释后的表达式
java
package com.molang.math.molang;
import com.molang.math.core.*;
import com.molang.math.function.Function;
import com.molang.math.function.MathFunctions;
import com.molang.math.parser.ExpressionParser;
import com.molang.math.parser.ParseException;
/**
* MoLang 解析器
*/
public class MolangParser {
public final ExpressionContext context;
public final MathFunctions functions;
private final ExpressionParser parser;
private final MolangCache cache;
// 常量
public static final MolangExpression ZERO = MolangExpression.ZERO;
public static final MolangExpression ONE = MolangExpression.ONE;
public MolangParser() {
this.context = new ExpressionContext();
this.functions = new MathFunctions();
this.parser = new ExpressionParser(context, functions);
this.cache = new MolangCache();
// 注册常量
context.setValue("math.pi", Math.PI);
context.setValue("pi", Math.PI);
context.setValue("e", Math.E);
}
/**
* 解析表达式(带缓存)- 返回底层 Expression
*/
private Expression parse(String expression) throws ParseException {
// 检查缓存
Expression cached = cache.get(expression);
if (cached != null) {
return cached;
}
// 解析并缓存
Expression result = parser.parse(expression);
cache.put(expression, result);
return result;
}
/**
* 解析表达式(返回 MolangExpression 包装,提供给外界使用)
*/
public MolangExpression parseExpression(String expression) {
try {
Expression expr = parse(expression);
return new MolangExpression(expr, expression);
} catch (ParseException e) {
System.err.println("Failed to parse expression: " + expression + " - " + e.getMessage());
return ZERO;
}
}
/**
* 设置变量值
*/
public void setValue(String name, double value) {
context.setValue(name, value);
}
/**
* 获取变量
*/
public Variable getVariable(String name) {
return context.getVariable(name);
}
/**
* 注册数组
*/
public ArrayVariable registerArray(String name, double[] values) {
return context.registerArray(name, values);
}
/**
* 注册自定义函数
*/
public void registerFunction(String name, Function function) {
functions.register(name, function);
}
/**
* 清理 temp 变量(每帧调用)
*/
public void clearTempVariables() {
context.clearTempVariables();
}
/**
* 获取 temp 变量数量
*/
public int getTempVariableCount() {
return context.getTempVariableCount();
}
/**
* 清空缓存
*/
public void clearCache() {
cache.clear();
}
/**
* 垃圾回收缓存
*/
public void gcCache() {
cache.gc();
}
/**
* 预热缓存
*/
public void warmupCache(String... expressions) {
for (String expr : expressions) {
try {
Expression compiled = parser.parse(expr);
cache.warmup(expr, compiled);
} catch (ParseException e) {
System.err.println("Warmup failed for: " + expr + " - " + e.getMessage());
}
}
}
/**
* 获取缓存统计
*/
public String getCacheStats() {
return cache.getStats().toString();
}
/**
* 获取缓存命中率
*/
public double getCacheHitRate() {
return cache.getStats().getHitRate();
}
/**
* 重置统计
*/
public void resetStats() {
cache.resetStats();
}
}解析后的结果被封装到MolangExpression中,暴露求值方法用于在运行时(Runtime)调用
java
package com.molang.math.molang;
import com.molang.data.types.BaseType;
import com.molang.data.types.StringType;
import com.molang.math.core.Expression;
import com.molang.math.core.Value;
/**
* MoLang 表达式包装类
*
* - 内部使用 Expression 接口进行计算
* - 保留原始字符串用于序列化
*/
public class MolangExpression {
private final Expression expression;
private final String source;
public MolangExpression(Expression expression, String source) {
this.expression = expression;
this.source = source;
}
/**
* 求值(运行时计算)
*/
public double get() {
return expression.evaluate();
}
/**
* 求值(运行时计算)
*/
public boolean getBoolean() { return expression.evaluateBoolean(); }
/**
* 求值(运行时计算)
*/
public String getString() { return expression.evaluateString(); }
/**
* 是否为常量
*/
public boolean isConstant() {
return expression.isConstant();
}
/**
* 获取原始表达式字符串
*/
public String getSource() {
return source;
}
@Override
public String toString() {
return source;
}
// ========== 常量 ==========
public static final MolangExpression ZERO = new MolangExpression(
new Value(0),
"0"
);
public static final MolangExpression ONE = new MolangExpression(
new Value(1),
"1"
);
// ========== 工具方法 ==========
/**
* 检查是否为 0 值
*/
public static boolean isZero(MolangExpression expr) {
return expr != null && Math.abs(expr.get()) < 0.0001;
}
/**
* 检查是否为 1 值
*/
public static boolean isOne(MolangExpression expr) {
return expr != null && Math.abs(expr.get() - 1) < 0.0001;
}
/**
* 检查是否为常量且等于指定值
*/
public static boolean isConstant(MolangExpression expr, double value) {
return expr != null && expr.isConstant() &&
Math.abs(expr.get() - value) < 0.0001;
}
}
全部评论 (0)
暂无评论,快来抢沙发吧~