ServerSync 分布式数据同步系统 - 从原理到实现
一个为MC跨服架构设计的强一致性数据同步方案
第一章:为什么需要 ServerSync
1.1 从一个痛点说起
假设你正在运营一个 Minecraft 服务器网络,你挂上了 Velocity, 下挂有多个子服务器:玩家可以在这些服务器之间自由切换。
我们假设你有一个看似简单的需求:
::: align-center
玩家在A服获得了一些物品,就比如说金币,要能在B服使用。
:::
这不难吧?我们用 MySQL DB存玩家金币,哪个服都能读写。于是你写了这样的代码:
kotlin
// A服务器:比如玩家杀了一个 Boss,奖励了 100 金币
fun onBossKill(player: Player) {
val current = database.query("SELECT gold FROM player_data WHERE uuid = ?", player.uniqueId)
val newGold = current + 100
database.update("UPDATE player_data SET gold = ? WHERE uuid = ?", newGold, player.uniqueId)
player.sendMessage("获得 100 金币!当前: $newGold")
}
// B服:玩家购买物品,扣除 50 金币
fun onBuyItem(player: Player) {
val current = database.query("SELECT gold FROM player_data WHERE uuid = ?", player.uniqueId)
if (current < 50) {
player.sendMessage("金币不足!")
return
}
val newGold = current - 50
database.update("UPDATE player_data SET gold = ? WHERE uuid = ?", newGold, player.uniqueId)
giveItem(player, "钻石剑")
}上线测试,一切正常。运维说:
::: align-center
有玩家发现自己的金币凭空消失了。
:::
以上的问题是大多数Bukkit插件的缩影,在少人数的服务器上发生的机率是比较小的,但是一旦并发情况恶劣,上面的问题会经常发生
::: align-center
为什么?让我们分析一下
:::
1.2 传统方案为嘛不行
问题一:并发竞态
我们假设玩家在地牢服击杀 Boss 的同时,他的朋友在商店服帮他买了东西。两个操作几乎同时发生:
时刻 T0: 玩家金币 = 1000
时刻 T1: A服读取 gold = 1000
时刻 T2: B服读取 gold = 1000
时刻 T3: A服写入当前金币为查到的值+100 gold = 1100 (1000 + 100)
时刻 T4: B服写入当前金币为查到的值-50 gold = 950 (1000 - 50)
最终结果: gold = 950100 金币凭空消失了。这就是经典的"丢失更新"问题。
问题二:跨服传输的数据一致性
玩家从A服传送到B服,数据怎么同步?
方案 A:传送前保存到 DB
kotlin
fun transferPlayer(player: Player, targetServer: String) {
saveToDatabase(player) // 保存当前数据
player.connect(targetServer)
}问题:如果保存失败怎么办?玩家已经传送过去了,数据却没保存,回档了,那我的金币这块谁给我补啊?
方案 B:传送后从 DB 加载
kotlin
fun onPlayerJoin(player: Player) {
val data = loadFromDatabase(player)
applyToPlayer(player, data)
}问题:如果玩家在传送过程中掉线了,那么数据可能处于不一致状态。如果玩家掉线了加入的服务器又不是掉线前的服务器,那么可能会发生未定义行为。
问题三:缓存与 DB 的双写不一致
假设你为了性能,加了 Redis 缓存:
kotlin
fun updateGold(playerId: UUID, delta: Int) {
// 先更新缓存
redis.incrBy("gold:$playerId", delta)
// 再更新数据库
database.update("UPDATE player_data SET gold = gold + ? WHERE uuid = ?", delta, playerId)
}如果 Redis 更新成功,DB 更新失败呢?或者反过来?缓存和 DB 不一致了。
问题四:审计困难
加入玩家投诉金币异常,你去查日志:
[10:23:45] 玩家 A 金币变更: 1000 -> 1100
[10:23:47] 玩家 A 金币变更: 1100 -> 950啊?什么?谁改的?为什么改?在哪个服务器改的?你完全不知道。
1.3 所以 ServerSync(SS) 要解决什么问题
ServerSync 是笔者为 Minecraft 跨服架构设计的分布式数据同步系统,目标是:
一,强一致性
无论玩家在哪个服务器,看到的数据都是一致的。不会出现"金币凭空消失"或"物品重复"。
二,原子操作
多个字段的修改要么全部成功,要么全部失败。不会出现"扣了金币但没给物品"。
三,跨服传输安全
玩家在服务器间传输时,数据不会丢失、不会回档、不会重复。
四,全链路审计
每一次数据变更都有完整的审计记录:谁改的、为什么改、什么时候改、改了什么。
五,高可用
单个服务器故障完全不影响其他服务器,数据不会丢失。
1.4 系统架构概览
ServerSync 的核心架构可以分为五层:
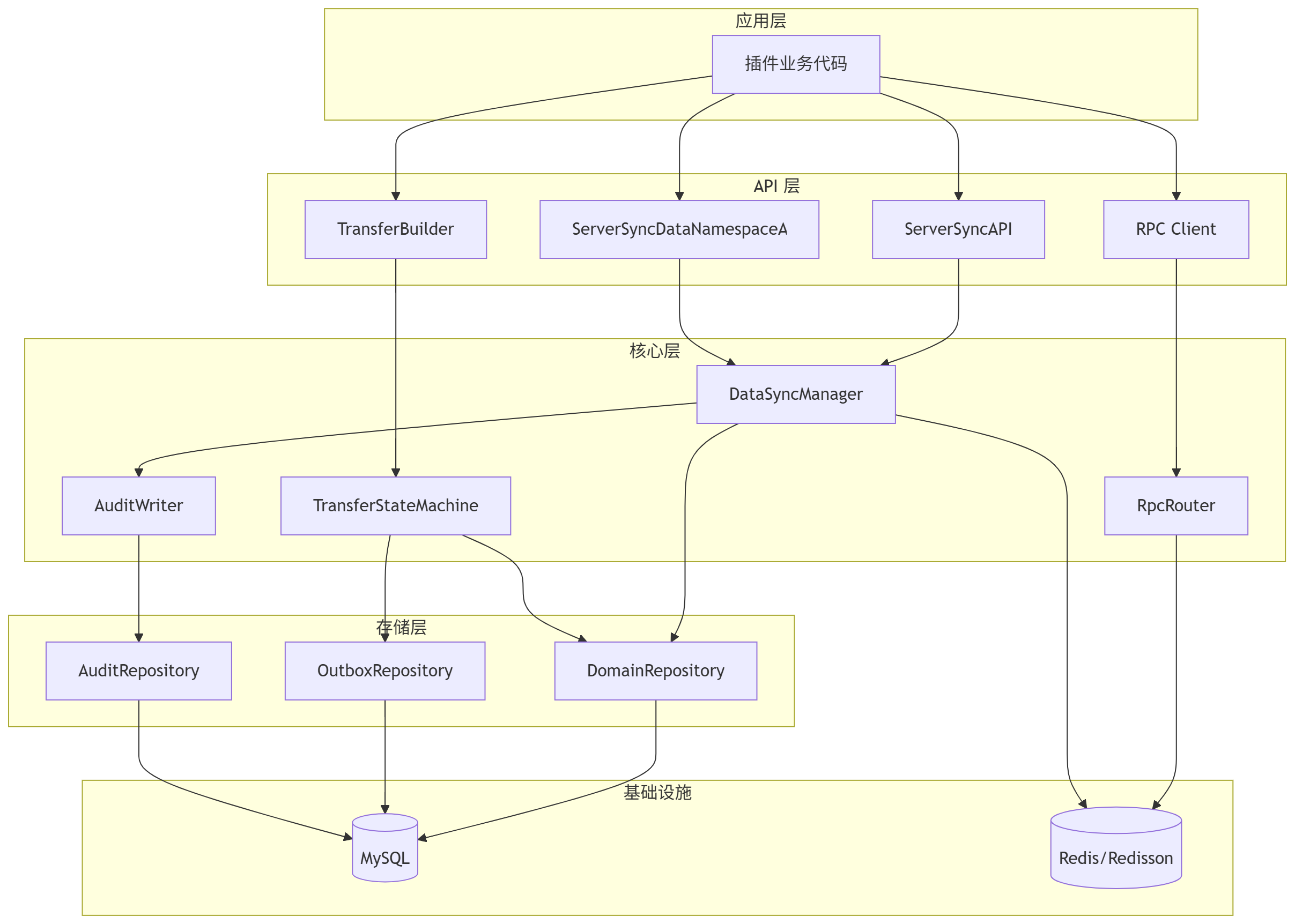
数据流转示意
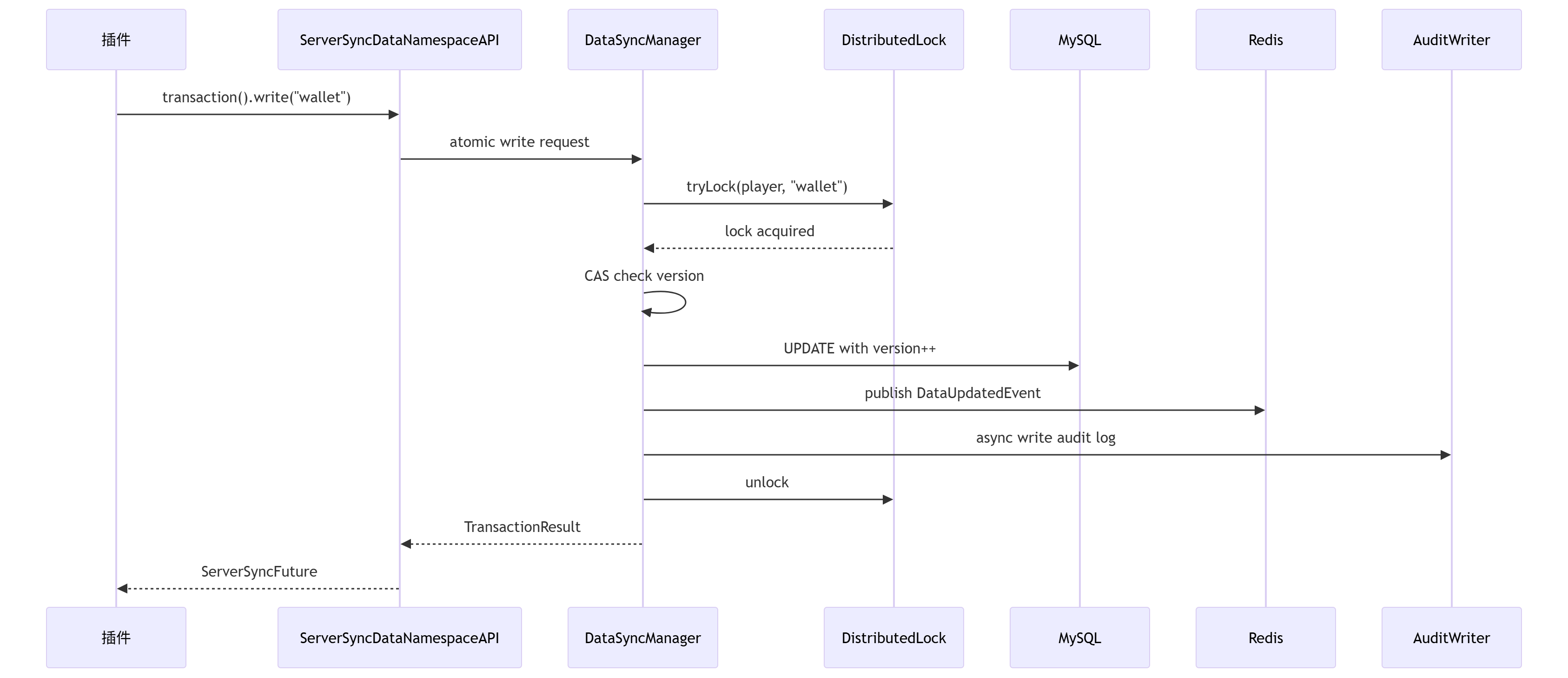
一次完整的数据写入流程:
SS的核心组件职责
| 组件 | 职责 |
|---|---|
| DataSyncManager | 数据同步核心,管理读写、版本控制、锁协调 |
| TransferStateMachine | 玩家跨服传输状态机,保证传输原子性 |
| RpcRouter | RPC 路由与分发,支持 Query/Command/Event |
| AuditWriter | 异步审计日志写入,MPSC 队列批量刷盘 |
| DomainRepository | 数据持久化,支持动态 Shard 和 Schema |
| OutboxRepository | Outbox 事件表,保证 DB + Redis 最终一致性 |
技术选型
缓存与分布式锁: Redisson (Redis)
DB与ORM: MySQL 8.0+ / PostgreSQL,连接池使用 HikariCP,ORM使用 Jetbrains Exposed
消息传递: Redis Pub/Sub
序列化: 优化后的 Gson (包括专为Bukkit设计的序列化器,支持流式序列化)
ServerSync 的代价是高复杂度,但换来的是生产级的可靠性。
1.5 本文章的结构
接下来的章节会按以下顺序展开:
- 第二章:核心概念与数据模型 - 理解 Namespace/Domain/Owner
- 第三章:分布式锁与 Fence Token - 解决锁失效问题
- 第四章:CAS 与版本控制 - 实现乐观锁
- 第五章:Outbox 模式 - 保证 DB + Redis 一致性
- 第六章:跨服传输 - 状态机与原子性
- 第七章:RPC 通信 - CQE 三种语义
- 第八章:审计系统 - 全链路追踪
- 第九章:性能优化 - 缓存与批量操作
第二章:核心概念与数据模型
2.1 Namespace、Domain、Owner 三层模型
为什么需要三层抽象
最朴素的想法是:一个玩家对应一条数据库记录,所有字段都存在一张表里。
sql
CREATE TABLE player_data (
uuid VARCHAR(36) PRIMARY KEY,
gold INT,
level INT,
exp BIGINT,
inventory TEXT,
skills TEXT,
quests TEXT,
... -- 几十个字段
);这个方案能跑,但有几个问题:
问题一:字段爆炸
随着功能增加,字段越来越多。经济系统要加 gold、diamond、points,技能系统要加 skill_tree、cooldowns,任务系统要加 active_quests、completed_quests...
一张表几十个字段,维护困难,查询效率低。
问题二:锁粒度太粗
如果用行锁保护并发,整个玩家数据都被锁住。经济系统在更新金币,技能系统就得等着,即使它们操作的是完全不同的字段。
问题三:业务隔离性差
不同插件的数据混在一起。A 插件想清空玩家的任务数据,有可能开发者SQL写错了就误删了 B 插件的字段。
问题四:无法动态扩展
新插件想存数据,要么就得改表结构(危险),要么就得自己建表(碎片化)。
三层模型的设计
SS 采用 Namespace → Domain → Owner 三层模型:
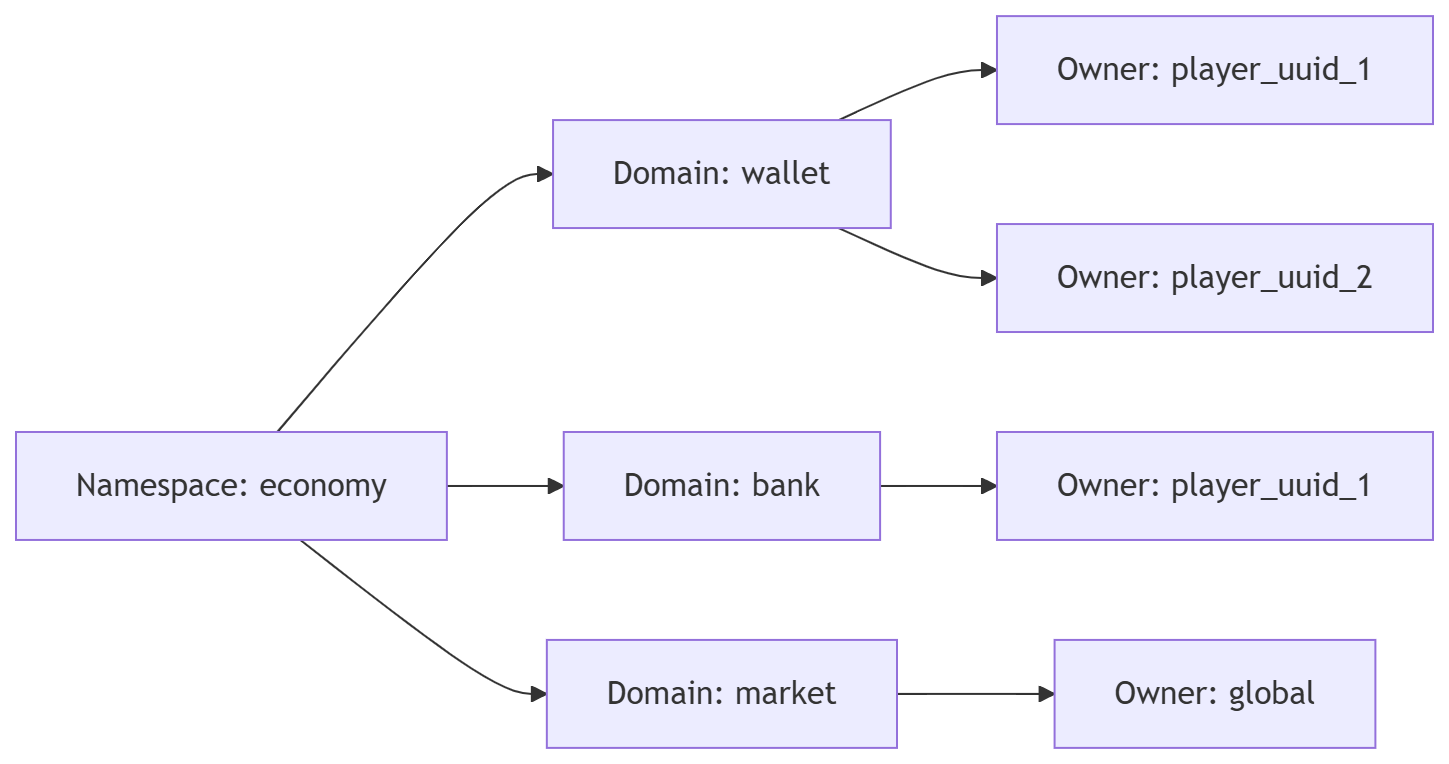
Namespace(命名空间)
- 业务模块的顶层隔离
- 例如:
economy(经济)、skill(技能)、quest(任务) - 不同 Namespace 的数据完全独立,可以有独立的数据库
Domain(数据域)
- Namespace 内的数据分类
- 例如:
economy下有wallet(钱包)、bank(银行)、market(市场) - 每个 Domain 是一个独立的锁单元
Owner(所有者)
- 数据的归属主体
- 玩家数据:
player_{uuid} - 全局数据:
global、guild_{id}
数据存储结构
当前实现不是“单表 JSON 大字段”,而是按 Domain 动态建独立表:
- 玩家域:
ss_{region}_player_{domain} - 全局域:
ss_{region}_global_{domain}
每个域表都带统一元列:
version(CAS 版本)fence_token(防旧写入)updated_at / updated_by_server / updated_by_actor
业务字段则来自你通过 Schema Builder 动态声明的字段定义(INT/LONG/DOUBLE/BOOLEAN/STRING/UUID/JSON)。
示意结构:
sql
CREATE TABLE ss_cn1_player_wallet (
owner_uuid CHAR(36) PRIMARY KEY,
gold BIGINT NOT NULL,
diamond BIGINT NOT NULL,
last_update BIGINT NOT NULL,
version BIGINT NOT NULL DEFAULT 0,
fence_token BIGINT NOT NULL DEFAULT 0,
updated_at BIGINT NOT NULL DEFAULT 0,
updated_by_server VARCHAR(64) NOT NULL DEFAULT '',
updated_by_actor VARCHAR(128) NOT NULL DEFAULT ''
);实际的数据模型声明已经全部使用 API 包装,不需要写任何的 SQL
为什么要使用三层模型,它的优势?
一:锁的粒度够细
锁的粒度是 (owner, domain)。更新 wallet 不影响 bank,不同玩家的 wallet 也互不影响。
二:不同业务隔离
每个插件使用独立的 Namespace。插件 A 崩掉不会影响插件 B 的数据。
三:可以动态扩展
新插件只需注册新的 Namespace 和 Domain,而无需修改表结构。
四:强类型与扩展并存
基元字段是强类型列,复杂对象可以用 DataType.JSON 承载,框架内部会自动将 List、Map 等集合类型序列化为 JSON 存储,这样既有读写性能,也保留扩展弹性。
2.2 DataContainer 与脏数据追踪
内存中的数据容器
SS 在内存中维护一个 DataContainer,缓存玩家的数据,他源自于笔者这篇文章的修改
kotlin
class DirtyDataContainer {
private val data = ConcurrentHashMap<String, DataValue<*>>()
fun <T> get(key: String): T? {
@Suppress("UNCHECKED_CAST")
return (data[key] as? DataValue<T>)?.get()
}
fun <T> set(key: String, value: T) {
val wrapper = data.computeIfAbsent(key) {
if (isDeepType(value)) {
DataValue.Deep(value)
} else {
DataValue.Primitive(value)
}
}
@Suppress("UNCHECKED_CAST")
(wrapper as DataValue<T>).set(value)
}
fun getDirtyKeys(): Set<String> {
return data.entries
.filter { it.value.isDirty() }
.map { it.key }
.toSet()
}
}脏数据的追踪机制
DataValue 分为两种,使用哈希追踪数据变化:
Primitive(基元类型)
kotlin
class Primitive<T>(private var value: T) : DataValue<T>() {
@Volatile
private var dirty = false
override fun set(newValue: T) {
if (value != newValue) {
value = newValue
dirty = true
}
}
override fun isDirty() = dirty
}Deep(深层对象)
kotlin
class Deep<T>(private val value: T) : DataValue<T>() {
@Volatile
private var currentHash = value.hashCode()
private var lastCleanHash = currentHash
override fun isDirty(): Boolean {
val hash = value.hashCode()
return hash != lastCleanHash
}
override fun modify(block: T.() -> T): T {
val result = value.block()
currentHash = value.hashCode()
dirty = true
return result
}
}为什么需要脏数据追踪
第一:减少不必要的写入
举个例子:
kotlin
// 玩家登录,加载数据
val wallet = container.get<Int>("gold") // 1000
// 玩家什么都没做,登出
// 不需要写回数据库,因为没有脏数据第二:便于批处理
例子:
kotlin
// 修改多个字段
container.set("gold", 1100)
container.set("diamond", 55)
container.set("level", 10)
// 只写入脏字段
val dirtyKeys = container.getDirtyKeys()
// ["gold", "diamond", "level"]
// 批量更新
UPDATE ... SET fields = JSON_SET(fields,
'$.gold', 1100,
'$.diamond', 55,
'$.level', 10
)2.3 Snapshot 与 CAS 乐观锁
什么是 Snapshot
DataSnapshot 是数据的只读快照,当你需要一次性读取整个Domain的数据时,SS会直接返回一整个域的快照,而不需要你逐个字段读取(通常这样干还会遇到并发问题):
kotlin
interface DataView {
operator fun <T> get(key: String): T?
fun <T> getOrDefault(key: String, default: T): T
fun containsKey(key: String): Boolean
fun keys(): Set<String>
}
class DataSnapshot(
private val fields: Map<String, Any?>
) : DataView {
override fun <T> get(key: String): T? {
@Suppress("UNCHECKED_CAST")
return fields[key] as? T
}
// 类型安全的 getter
fun getString(key: String, default: String = ""): String {
return get<String>(key) ?: default
}
fun getInt(key: String, default: Int = 0): Int {
return get<Number>(key)?.toInt() ?: default
}
}CAS(Compare-And-Swap)原理
每个 Domain 有一个版本号 version。写入时:
- 读取当前版本号
expectedVersion - 执行业务逻辑
- 写入时检查版本号是否仍是
expectedVersion - 如果是,写入成功并递增版本号
- 如果不是,说明有并发修改,重试
kotlin
fun atomicWrite(
owner: String,
domain: String,
action: (DataEditor) -> Unit
): Boolean {
val (snapshot, expectedVersion) = readWithVersion(owner, domain)
val editor = MutableDataEditor(snapshot)
action(editor)
val dirtyFields = editor.getDirtyFields()
if (dirtyFields.isEmpty()) return true
// CAS 写入
val sql = """
UPDATE ss_{region}_{ownerType}_{domain}
SET <changed_columns>, version = version + 1, updated_at = ?
WHERE owner_id = ? AND version = ?
"""
val affected = jdbc.update(
sql,
System.currentTimeMillis(),
ownerId,
expectedVersion
)
return affected > 0 // 返回 true 表示成功
}CAS 重试机制
kotlin
fun atomicWriteWithRetry(
owner: String,
domain: String,
maxRetries: Int = 3,
action: (DataEditor) -> Unit
): TransactionResult {
repeat(maxRetries) { attempt ->
val success = atomicWrite(owner, domain, action)
if (success) {
return TransactionResult(writes = 1)
}
// 冲突,短暂等待后重试
Thread.sleep(10L * (attempt + 1))
}
throw ConcurrentModificationException(
"CAS failed after $maxRetries retries"
)
}为什么选择乐观锁而非悲观锁
在这篇文章里已经介绍过类似地细节
Minecraft 场景下,读多写少,乐观锁更合适。
2.4 OperationContext 审计链路
为什么需要 Context
为了解决开头讲的审计困难的问题,SS要求每次数据操作都必须携带上下文, SS中的APIOperationContext 是“业务语义”进入数据层的入口。它把 actor/reason/traceId/requestId 一次性带到写链路里,后面审计、排障、幂等都靠它。
java
public final class APIOperationContext {
public static APIOperationContext of(String actor, String reason);
public static APIOperationContext of(String actor, String reason, String traceId);
public static APIOperationContext of(String actor, String reason, String traceId, String requestId);
}使用示例(Java)
java
UUID playerId = player.getUniqueId();
var ns = APIProvider.getAPI()
.serverSync()
.data()
.namespace("economy");
APIOperationContext ctx = APIOperationContext.of(
"DungeonPlugin",
"boss_kill_reward",
"trace:dungeon:run_456",
"req:dungeon:reward:run_456:" + playerId
);
ns.transaction()
.player(playerId)
.context(ctx)
.write("wallet", editor -> {
int gold = editor.getOrDefault("gold", 0);
editor.set("gold", gold + 100);
})
.commit();Context 的传递链路
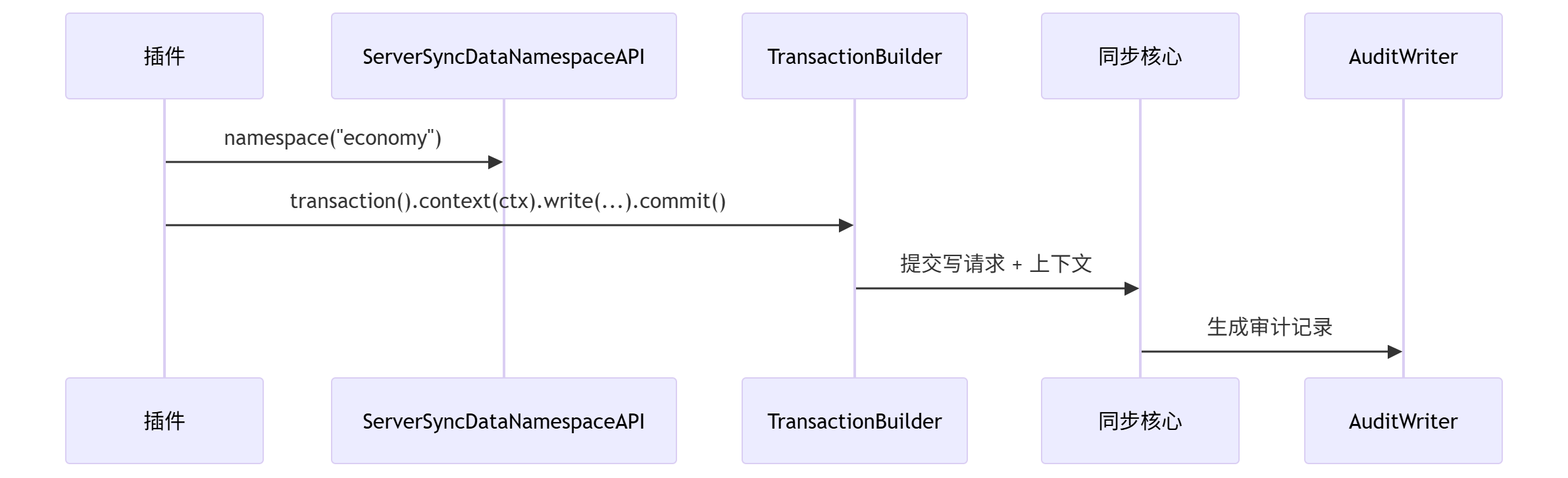
2.5 SS数据API的完整数据读写流程
读取流程(namespace 下按 domain)
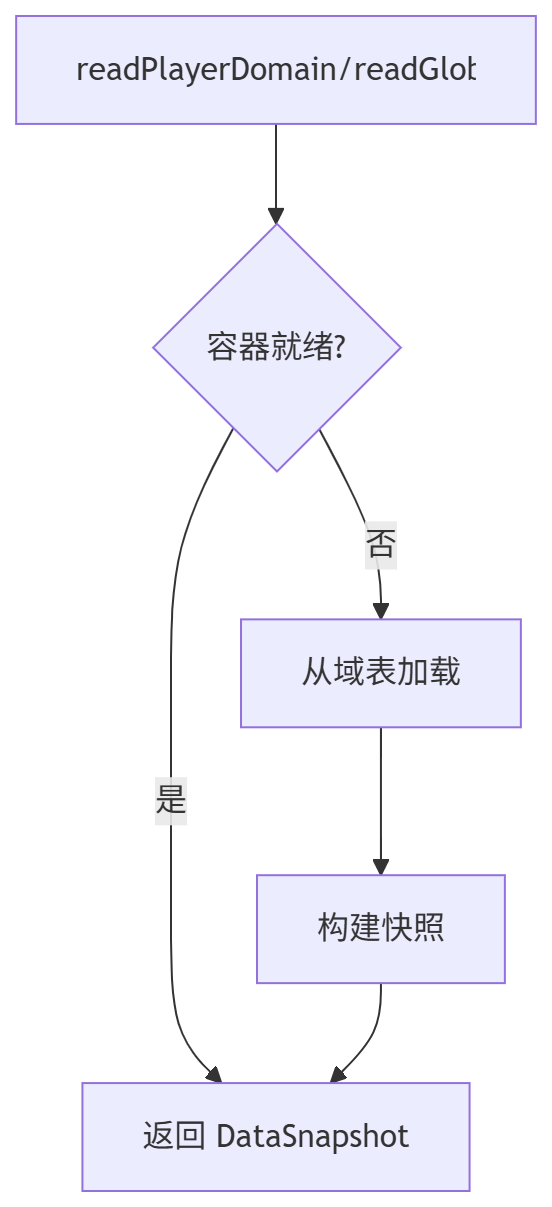
java
var ns = APIProvider.getAPI()
.serverSync()
.data()
.namespace("economy");
var wallet = ns.readPlayerDomain(playerId, "wallet");
int gold = wallet.getOrDefault("gold", 0);
Object taxRate = ns.readGlobalValue("market", "global", "tax_rate");写入流程(transaction 事务)
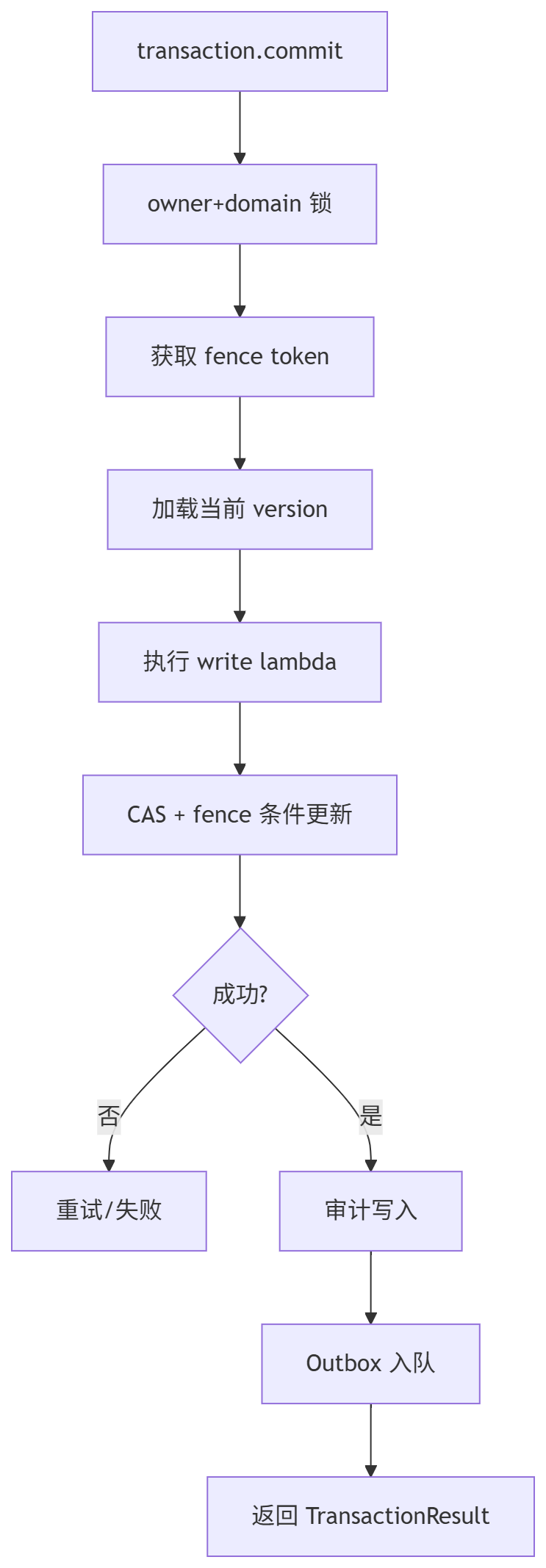
java
ns.transaction()
.player(playerId)
.context(APIOperationContext.of("ShopPlugin", "buy_item"))
.write("wallet", editor -> {
int gold = editor.getOrDefault("gold", 0);
editor.set("gold", gold - 50);
})
.commit()
.handle((result, error) -> {
if (error != null) {
System.out.println("提交失败: " + error.getMessage());
return;
}
System.out.println("写入条目: " + result.getWrites());
});第三章:分布式锁与 Fence Token
3.1 为什么需要分布式锁
场景
我们假设两个服务器同时修改同一个玩家的数据:
服务器 A:
读取 gold = 1000
计算 newGold = 1100
写入 gold = 1100
服务器 B:
读取 gold = 1000
计算 newGold = 950
写入 gold = 950即使用了 CAS,也可能出现问题:
T1: A 读取 version=10, gold=1000
T2: B 读取 version=10, gold=1000
T3: A CAS 写入成功,version=11, gold=1100
T4: B CAS 失败,重试
T5: B 读取 version=11, gold=1100
T6: B CAS 写入成功,version=12, gold=950发现了吗?100 金币又丢了,原因是 B 读取到的还是 gold=1000。CAS 只能保证单次写入的原子性,无法保证"读-改-写"整个过程的原子性。
分布式锁的作用
用分布式锁保护整个"读-改-写"过程:
kotlin
fun updateGold(playerId: UUID, delta: Int) {
val lock = getLock(playerId, "wallet")
lock.lock()
try {
val current = read(playerId, "wallet", "gold")
val newGold = current + delta
write(playerId, "wallet", "gold", newGold)
} finally {
lock.unlock()
}
}现在两个服务器的操作是串行的:
T1: A 获取锁
T2: A 读取 gold=1000
T3: A 写入 gold=1100
T4: A 释放锁
T5: B 获取锁
T6: B 读取 gold=1100
T7: B 写入 gold=1050
T8: B 释放锁3.2 Redisson 锁的问题:lease 过期
Redisson 的基本用法
kotlin
val lock = redisson.getLock("player:$playerId:wallet")
// 方式一:固定租约时间
lock.tryLock(5000, 10000, TimeUnit.MILLISECONDS)
// 等待 5 秒,持有 10 秒后自动释放
// 方式二:Watchdog 自动续租
lock.tryLock(5000, TimeUnit.MILLISECONDS)
// 等待 5 秒,持有期间自动续租固定租约的问题
如果业务逻辑执行时间超过租约时间:
kotlin
val lock = redisson.getLock("player:$playerId:wallet")
lock.tryLock(5000, 10000, TimeUnit.MILLISECONDS) // 10 秒租约
try {
val data = loadFromDatabase(playerId) // 2 秒
processComplexLogic(data) // 9 秒
saveToDatabase(playerId, data) // 1 秒
// 总共 12 秒,超过了 10 秒租约!
} finally {
lock.unlock()
}时间线:
T0: 服务器 A 获取锁,租约 10 秒
T10: 租约过期,锁自动释放
T11: 服务器 B 获取锁
T12: 服务器 A 写入数据(以为自己还持有锁)
T13: 服务器 B 写入数据数据被覆盖了。
Watchdog 的问题
Watchdog 会自动续租,但如果服务器 GC 停顿或网络抖动:
T0: 服务器 A 获取锁
T5: 你的服务器什么东西卡住主线程了,JVM GC Full Stop,停顿 15 秒
T10: Watchdog 尝试续租,但服务器卡住了
T15: 租约过期,锁自动释放
T16: 服务器 B 获取锁
T20: 服务器 A 恢复,继续执行(以为自己还持有锁)又出问题了,SS为了解决这个问题,引入了 FenceToken
3.3 Fence Token 原理详解
什么是 Fence Token
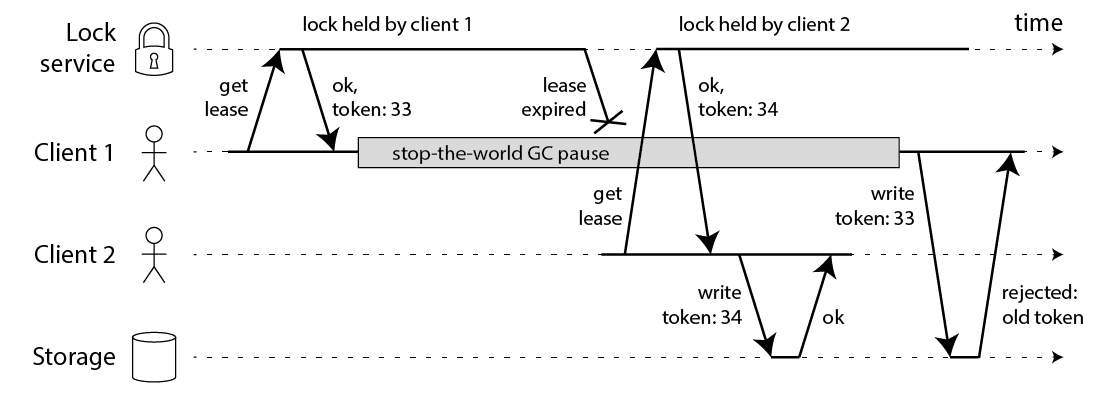
Fence Token 由分布式系统专家 Martin Kleppmann 于2016年提出,是一个单调递增的令牌,每次获取锁时递增。
这其中的关键点是:数据库拒绝旧 token 的写入。
解决锁失效问题
T0: 服务器 A 获取锁,token=42
T10: 锁过期释放
T11: 服务器 B 获取锁,token=43
T12: 服务器 A 尝试写入,token=42
数据库检查:42 < 43,拒绝写入
T13: 服务器 B 写入,token=43,成功即使锁失效,旧的写入也会被拒绝。
Fence Token 的数学保证
令牌必须满足:
- 单调递增:
token(n+1) > token(n) - 全局唯一:不同锁实例的 token 不会重复
- 持久化:token 必须持久化,重启后不能回退
3.4 单调递增令牌的实现
SS的当前实现是“Redis 发号 + DB floor 校验”的组合:
- 先
INCR生成候选 token(快速路径); - 读取/缓存 DB floor(
fence_sequence.current_value); - 如果 Redis 值小于等于 floor,按
floor + 1纠偏; - 在写事务里调用
updateFloor(...)做 CAS 落库。
kotlin
object FenceTokenService {
fun next(owner: String, domain: String): Long {
val redisKey = RegionContext.fenceKey(owner, domain)
val fenceKey = "$owner:$domain"
val redisVal = RedissonManager.client().getAtomicLong(redisKey).incrementAndGet()
val floor = cachedFloorOrLoad(fenceKey, domain)
if (redisVal <= floor) {
val recovered = floor + 1
RedissonManager.client().getAtomicLong(redisKey).set(recovered)
return recovered
}
return redisVal
}
fun updateFloor(fenceKey: String, newValue: Long): Boolean {
// 在事务内执行: 仅当 current_value < newValue 时更新成功
// 成功表示 token 仍有效;失败表示有更高 token 已提交
...
}
}3.5 代码实现与使用示例
DataLockManager 的实现
kotlin
object DataLockManager {
fun getLock(owner: String, domain: String): RLock {
return RedissonManager.client().getLock(
RegionContext.lockKey(owner, domain)
)
}
fun <T> withLock(
owner: String,
domain: String,
leaseTimeMs: Long = -1, // -1 表示使用 Watchdog
waitTimeMs: Long = 5_000,
action: () -> T
): T {
val lock = getLock(owner, domain)
val acquired = if (leaseTimeMs > 0) {
lock.tryLock(waitTimeMs, leaseTimeMs, TimeUnit.MILLISECONDS)
} else {
lock.tryLock(waitTimeMs, TimeUnit.MILLISECONDS)
}
if (!acquired) {
throw IllegalStateException(
"无法获取锁: ${RegionContext.lockKey(owner, domain)}"
)
}
try {
return action()
} finally {
if (lock.isHeldByCurrentThread) {
lock.unlock()
}
}
}
}上面的锁管理器只负责“互斥与释放”。
fence token 的发号和落库是写路径自己做的,典型顺序如下:
kotlin
DataLockManager.withLock(owner, domain) {
val token = FenceTokenService.next(owner, domain)
// ...读取当前行、执行业务修改...
// ...CAS 更新(where version=? and fence_token < token)...
FenceTokenService.updateFloor("$owner:$domain", token)
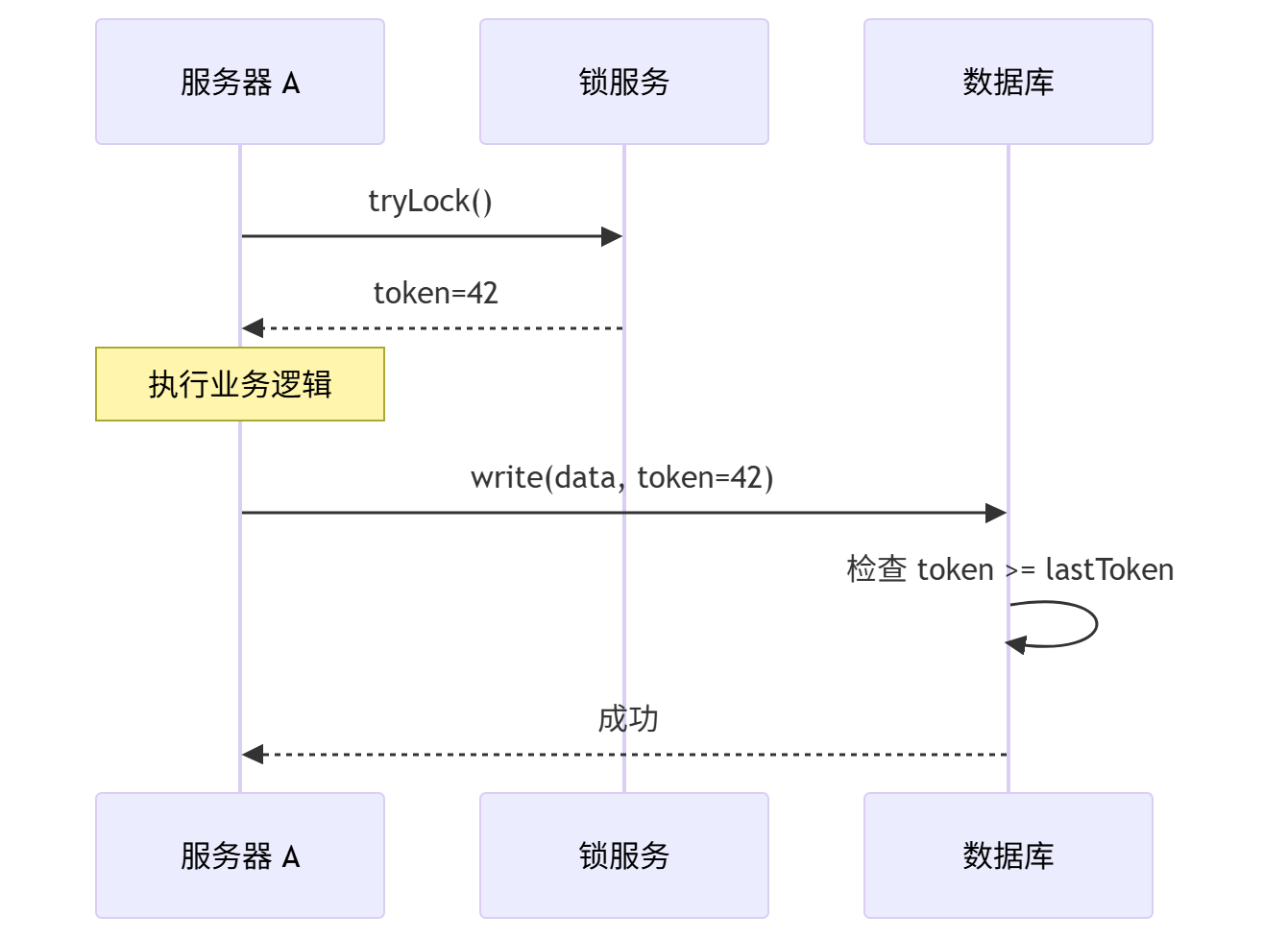
}数据库层的 Token 检查
kotlin
fun atomicWriteWithToken(
owner: String,
domain: String,
token: Long,
fields: Map<String, Any?>
): Boolean {
val sql = """
UPDATE ss_{region}_{ownerType}_{domain}
SET <changed_columns>, version = version + 1,
fence_token = ?, updated_at = ?
WHERE owner_id = ? AND fence_token < ?
"""
val affected = jdbc.update(
sql,
token, // 新 token
System.currentTimeMillis(),
ownerId,
token // 只有当前 token < 新 token 时才更新
)
return affected > 0
}完整的写入流程
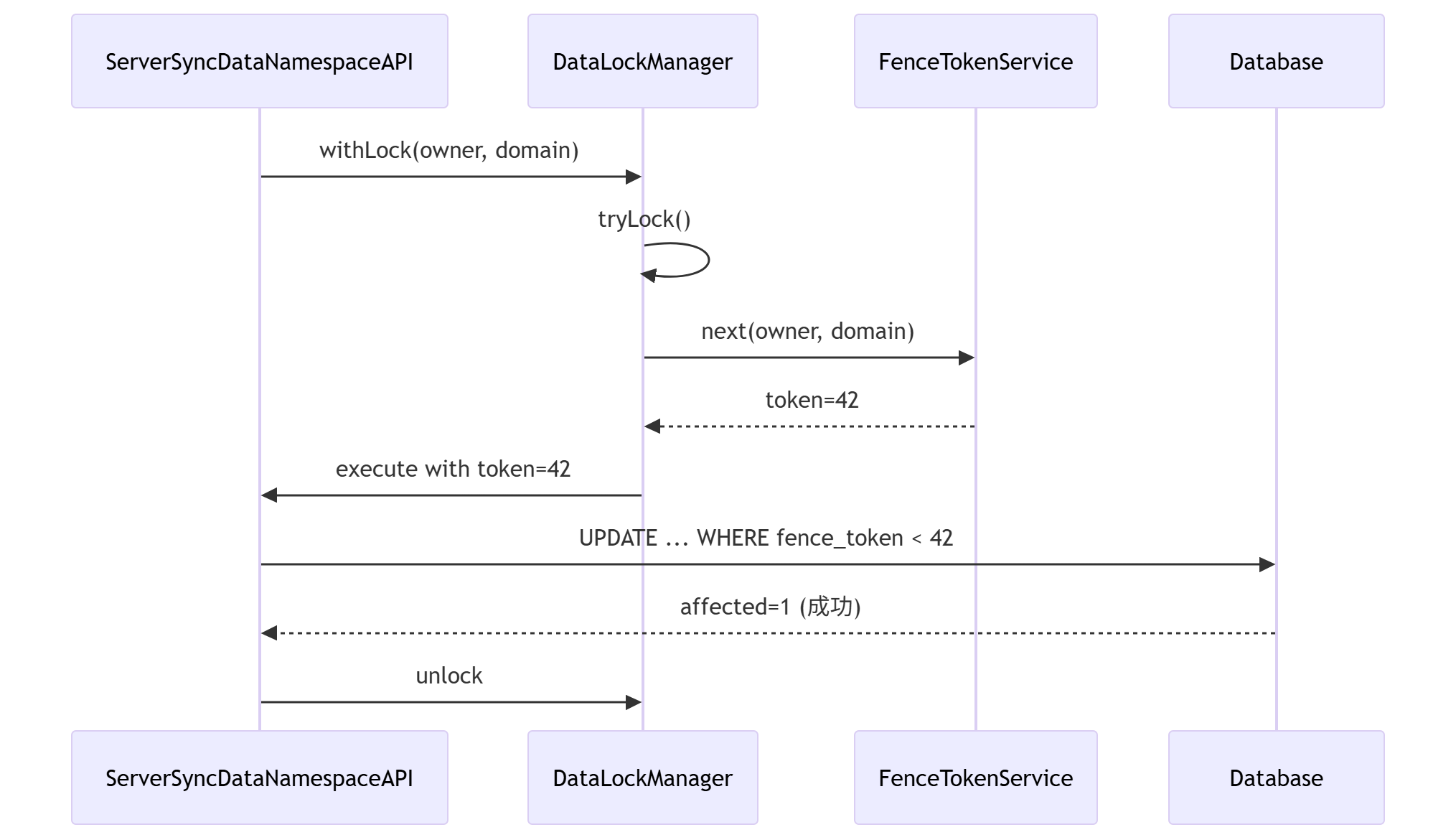
使用示例
kotlin
// 业务代码
fun rewardPlayer(playerId: UUID, gold: Int) {
DataLockManager.withLock(
owner = "player:$playerId",
domain = "wallet",
leaseTimeMs = -1 // 使用 Watchdog
) {
val current = read(playerId, "wallet", "gold")
val newGold = current + gold
write(playerId, "wallet", "gold", newGold)
}
}3.6 Fence Token 的局限性
但是但是,Fence Token 只能防止写入错乱,无法防止:
- 业务逻辑错误:如果业务逻辑本身有 bug,token 也救不了
- 读取脏数据:token 只保护写入,读取时可能读到旧数据
- 性能开销:每次获取锁都要递增 token,有额外开销
第四章:CAS 与版本控制
4.1 乐观锁的本质
这里再提一下
悲观锁和乐观锁
悲观锁:假设冲突一定会发生,先加锁再操作
kotlin
fun updateGold(playerId: UUID, delta: Int) {
lock.lock() // 阻塞等待
try {
val gold = read("gold")
write("gold", gold + delta)
} finally {
lock.unlock()
}
}乐观锁:假设冲突很少发生,先操作再检查
kotlin
fun updateGold(playerId: UUID, delta: Int) {
do {
val (gold, version) = readWithVersion("gold")
val newGold = gold + delta
val success = casWrite("gold", newGold, version)
} while (!success)
}为什么选择乐观锁
Minecraft 场景的特点是
| 特征 | 说明 |
|---|---|
| 读多写少 | 玩家频繁查看数据,偶尔修改 |
| 冲突率低 | 不同玩家的数据独立,冲突少 |
| 延迟敏感 | 加锁等待会影响游戏体验 |
所以比较适合乐观锁
4.2 版本号的维护策略
版本号存储
每个 Domain 有独立的版本号:
sql
CREATE TABLE ss_{region}_{ownerType}_{domain} (
-- ...其他字段
version BIGINT NOT NULL DEFAULT 1,
fence_token BIGINT NOT NULL DEFAULT 0,
-- ...
);版本号递增规则
一:每次写入必须递增
sql
UPDATE ss_{region}_{ownerType}_{domain}
SET <changed_columns>, version = version + 1
WHERE ... AND version = ?二:读取时返回版本号
kotlin
data class VersionedSnapshot(
val snapshot: DataSnapshot,
val version: Long
)
fun readWithVersion(owner: String, domain: String): VersionedSnapshot {
val row = jdbc.queryForMap(
"SELECT <domain_columns>, version FROM ss_{region}_{ownerType}_{domain} WHERE ...",
owner, domain
)
return VersionedSnapshot(
snapshot = DataSnapshot(extractDomainFields(row)),
version = row["version"] as Long
)
}三:写入时检查版本号
kotlin
fun casWrite(
owner: String,
domain: String,
fields: Map<String, Any?>,
expectedVersion: Long
): Boolean {
val affected = jdbc.update(
"""
UPDATE ss_{region}_{ownerType}_{domain}
SET <changed_columns>, version = version + 1
WHERE ... AND version = ?
""",
owner, domain, expectedVersion
)
return affected > 0
}4.3 CAS 重试机制
基础重试
kotlin
fun atomicWrite(
owner: String,
domain: String,
action: (DataEditor) -> Unit,
maxRetries: Int = 3
): TransactionResult {
repeat(maxRetries) { attempt ->
// 读取当前版本
val (snapshot, version) = readWithVersion(owner, domain)
// 执行业务逻辑
val editor = MutableDataEditor(snapshot)
action(editor)
// CAS 写入
val success = casWrite(owner, domain, editor.toMap(), version)
if (success) {
return TransactionResult(writes = 1)
}
// 冲突,等待后重试
Thread.sleep(10L * (attempt + 1))
}
throw ConcurrentModificationException(
"CAS failed after $maxRetries retries"
)
}指数退避
kotlin
fun exponentialBackoff(attempt: Int): Long {
val baseDelay = 10L
val maxDelay = 1000L
val delay = baseDelay * (1 shl attempt) // 2^attempt
return minOf(delay, maxDelay)
}
// 使用
Thread.sleep(exponentialBackoff(attempt))4.4 ABA 问题与规避
什么是 ABA 问题
CAS 有一个经典的陷阱:ABA 问题。
假设:
T1: 线程 A 读取 version=10
T2: 线程 B 修改 version=11
T3: 线程 C 修改 version=10(回退)
T4: 线程 A CAS 写入,version=10 匹配,成功线程 A 以为数据没变,实际上中间经历了两次修改。
SS的规避策略
一:版本号只增不减
kotlin
UPDATE ss_{region}_{ownerType}_{domain}
SET version = version + 1 -- 永远递增
WHERE ... AND version = ?版本号是单调递增的,不可能回退到旧值。这从根本上避免了 ABA。
二:Fence Token 双重保护
即使版本号匹配,Fence Token 也会拒绝旧的写入:
sql
WHERE version = ? AND fence_token < ?这两层保护确保了数据的安全。
4.5 冲突处理策略
冲突的分类
读-读冲突:不存在,读操作不加锁
读-写冲突:
- 读操作读到旧数据(可接受)
- 写操作不受影响
写-写冲突:
- CAS 失败,需要重试
- 这是唯一需要处理的冲突
冲突率的监控
kotlin
class CasMetrics {
private val attempts = AtomicLong(0)
private val conflicts = AtomicLong(0)
fun recordAttempt() = attempts.incrementAndGet()
fun recordConflict() = conflicts.incrementAndGet()
fun conflictRate(): Double {
val total = attempts.get()
return if (total > 0) conflicts.get().toDouble() / total else 0.0
}
}如果冲突率持续 > 10%,考虑改用悲观锁。
第五章:Outbox 模式与最终一致性
5.1 双写为什么一定会炸
我们在开头已经讲过,对于跨服系统,最容易出问题的一段就是:
- 先写业务数据到数据库;
- 再发通知给其他服务器刷新内存。
这两步只要有一步失败,就会出现“库里是新值、别的服还是旧值”的问题。
为此,SS引入了 Outbox(微服务架构-Outbox发件箱模式,知乎) ,Outbox的意义,就是把这件事做成“可重试、可追踪、可恢复”的标准链路。
5.2 当前 Outbox 的状态机
SS里的 Outbox 是完整四态:
NEW:可投递;DISPATCHING:已被某个节点认领,正在发;SENT:发送完成;DEAD:重试上限后进入死信。
另外还有一个关键动作:reclaim。
如果某条消息卡在 DISPATCHING 太久(例如节点崩了),会被回收为 NEW 再投递。
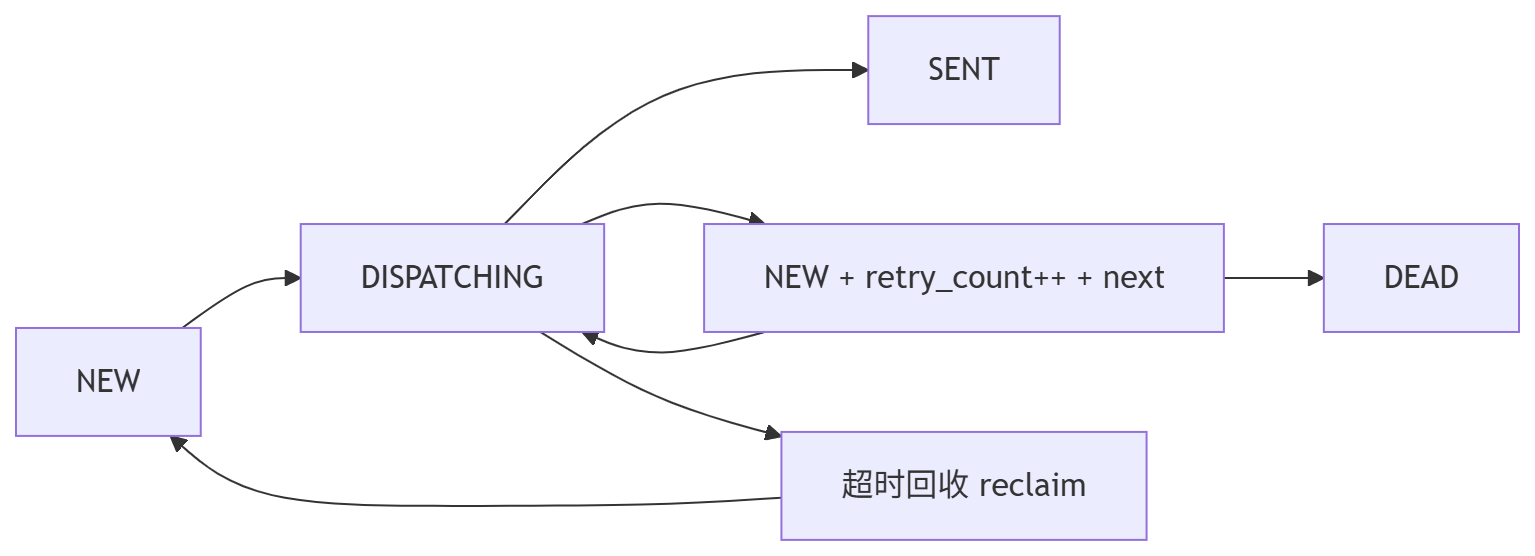
5.3 Outbox 表结构(当前版本)
sql
CREATE TABLE ss_{region}_outbox (
event_id VARCHAR(64) PRIMARY KEY,
aggregate_type VARCHAR(16) NOT NULL,
aggregate_id VARCHAR(128) NOT NULL,
domain VARCHAR(64) NOT NULL,
event_type VARCHAR(64) NOT NULL,
payload BLOB NOT NULL,
status VARCHAR(16) NOT NULL, -- NEW / DISPATCHING / SENT / DEAD
retry_count INT NOT NULL DEFAULT 0,
next_retry_at BIGINT NOT NULL,
created_at BIGINT NOT NULL
);这里的 payload 是二进制 JSON。
之所以这样做,是为了在不同节点间稳定传输,不依赖业务对象在每个服的同构类加载状态。
5.4 写入链路:业务写 + Outbox 入队同事务
在一次写事务里,核心顺序是:
- CAS/fence 写业务域表;
- 在同一事务里插入 Outbox
NEW事件; - 统一提交。
kotlin
transaction(db) {
val updated = domainRepository.casUpdateInTx(
ownerId = ownerId,
fields = changedFields,
expectedVersion = expectedVersion,
newFenceToken = fenceToken,
serverName = serverName,
actor = actor
)
if (!updated) error("CAS/fence conflict")
OutboxRepository.insertInTx(
eventId = eventId,
aggregateType = ownerType,
aggregateId = ownerId,
domain = domain,
eventType = "DATA_UPDATED",
payload = payloadBytes
)
}这一步解决的是“业务成功但没通知”。
5.5 投递链路:claim -> publish -> mark
投递器会定时轮询并认领事件(NEW -> DISPATCHING),然后发到 Redis RTopic。
如果发成功,标 SENT;失败则按退避策略回到 NEW,超限转 DEAD。
kotlin
suspend fun pollAndDispatch() {
reclaimStuckDispatching()
val events = OutboxRepository.pollNewEventsAll(batchSize) // core + shards
for (event in events) {
try {
publishToTopic("ss:{region}:outbox:${event.domain}", event.payload)
OutboxRepository.markSent(event.eventId, event.shardKey)
} catch (e: Exception) {
if (event.retryCount >= maxRetries) {
OutboxRepository.markDead(event.eventId, event.shardKey)
} else {
OutboxRepository.markRetry(event.eventId, event.retryCount, retryBackoffBase, event.shardKey)
}
}
}
}5.6 “至少一次投递”的副作用
Outbox 保证的是“至少一次”,不是“恰好一次”。
所以业务消费方要做幂等。SS内采用:
- 以
event_id做去重键; - 或以“版本高水位”过滤旧事件(例如只接受更高 version)。
第六章:跨服传输与状态机
6.1 跨服不是“传人”,而是“迁移状态”
在业务上,我们看到的是“把玩家送到另一个服”。
但在系统上,真正要保证的是:
- 源服最后一笔有效写入不会丢;
- 目标服接到的是完整可用的数据视图;
- 失败时可以补偿,不会把玩家留在半完成状态。
所以 SS实现的不是“单次跳转动作”,而是一条可追踪、可恢复的传输账本流程。
6.2 传输状态机
SS的传输状态是固定五段:
PREPARE:进入传输态,停止新写入并收敛在途写入;SAVE:把脏数据持久化;PUBLISH:源服宣布“数据可被目标服接管”;APPLY:目标服开始接管并装载;ACK:目标服确认完成。
对应结果状态一般是 PENDING / DONE / TIMEOUT。
TIMEOUT 不是“错误被吞掉”,而是显式落账,便于后续补偿和排查。

6.3 发起端(源服)到底做了什么
以 player -> group("dungeon") 为例,源服并不是直接发一个“连接指令”就结束,而是先做数据上的收口:
java
var api = APIProvider.getAPI().serverSync();
var request = TransferRequest.builder(player.getUniqueId())
.targetGroup("dungeon")
.selectionStrategy(SelectionStrategy.LEAST_PLAYERS)
.fallbackPolicy(FallbackPolicy.QUEUE)
.build();
api.transfer().execute(request).handle((result, error) -> {
if (error != null) {
player.sendMessage("切服失败:" + error.getMessage());
return;
}
if (result.getCode() == TransferCode.SUCCESS ||
result.getCode() == TransferCode.CROSS_REGION_SUCCESS) {
player.sendMessage("正在进入Dungeon服...");
} else if (result.getCode() == TransferCode.QUEUED) {
player.sendMessage("当前排队位置:" + result.getQueuePosition());
} else {
player.sendMessage("切服失败:" + result.getCode() + " / " + result.getMessage());
}
});它的内部动作可以理解为:
- 获取玩家传输锁,避免同一玩家并发发起多次传输;
- 调
beginTransfer,收口在途写入; - 推进账本到
PREPARE -> SAVE -> PUBLISH; - 通过代理层请求真正的连接切换;
- 如果代理切换失败,进入补偿(标记
TIMEOUT+ 尝试恢复源服容器)。
这一步的价值是:就算网络抖动或目标服拒绝连接,源服状态也能回到可用状态,而不是“人在线、容器没了”。
6.4 接收端(目标服)怎么接管
玩家进入目标服时,目标服不会盲目按普通 Join 流程加载数据,而是先看有没有“自己该接手的账本记录”。
命中传输账本时,流程是:
- 从
PUBLISH推进到APPLY; - 加载并应用玩家域数据;
- 推进到
ACK,标记接管完成。
没命中账本,或者账本不合法,则回退到普通登录加载流程。
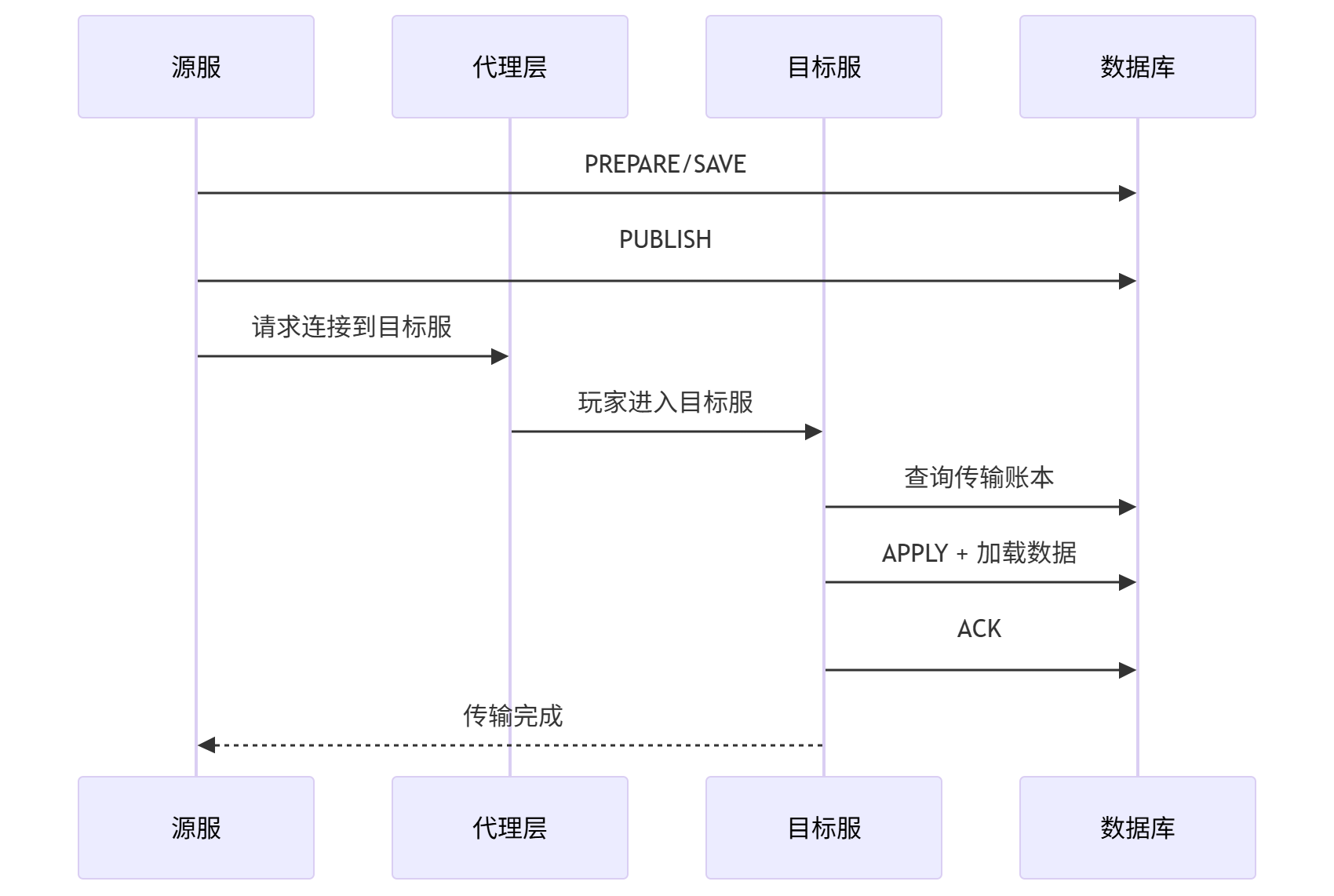
6.5 为什么这套流程能抗复杂故障
典型问题与应对的方式:
- 代理返回失败:源服会走回滚路径,账本超时且可见;
- 目标服接管异常:不直接吞错,回退普通加载并且会返回错误码;
- 停服:SS内的关服栅栏会先关写入口拒绝新写入,再做脏数据冲刷把目前等待写入的请求处理完毕之后才会允许服务器关闭。
第七章:RPC 通信与 CQE 模式
7.1 RPC 在SS里负责什么
在SS的使用场景,你可以把RPC理解为“跨服函数调用”:
它不是去查数据库,而是直接让目标服执行逻辑并回包。
常见场景:
- 查询某个子服实时状态(比如在线人数);
- 执行跨服动作(发放奖励、同步状态);
- 向一组服务器广播事件(活动开始、配置刷新)。
SS将RPC分为三个模型,以下统称“CQE”
7.2 CQE 的三种语义
| 类别 | 典型用途 | 可靠性语义 | 返回值 |
|---|---|---|---|
QUERY |
只读查询 | at-most-once | 有 |
COMMAND |
有副作用命令 | at-least-once(可重试) | 有 |
EVENT |
单向通知 | at-most-once | 无 |
一句话:
- 要查数据,用
QUERY; - 要改状态,用
COMMAND(并保证处理器幂等); - 纯通知,用
EVENT。
7.3 SS内RPC的真实协议
SS内的RPC协议现在是“描述符 + 信封”双层约束。
描述符(Descriptor)
它定义一个消息的稳定身份:
messageIdcategory(QUERY/COMMAND/EVENT)schemaVersion / supportedVersions- ACL(来源限制、QPS、payload 上限)
- COMMAND 的幂等存储级别
RPC传输信封(Envelope)
每一条消息传输时都会带上:
requestIdsourceServer / targetServermessageId / schemaVersion / protocolVersionmessageCategorynonce / timestamp / signature / keyId
这些额外的信息允许接收端不是“收到就执行”,而是先过完整校验链检查该消息是否是伪造的,是否有效等。
7.4 传输链路:RTopic + Router 校验流水线
当前SS的RPC传输层走 Redis RTopic。
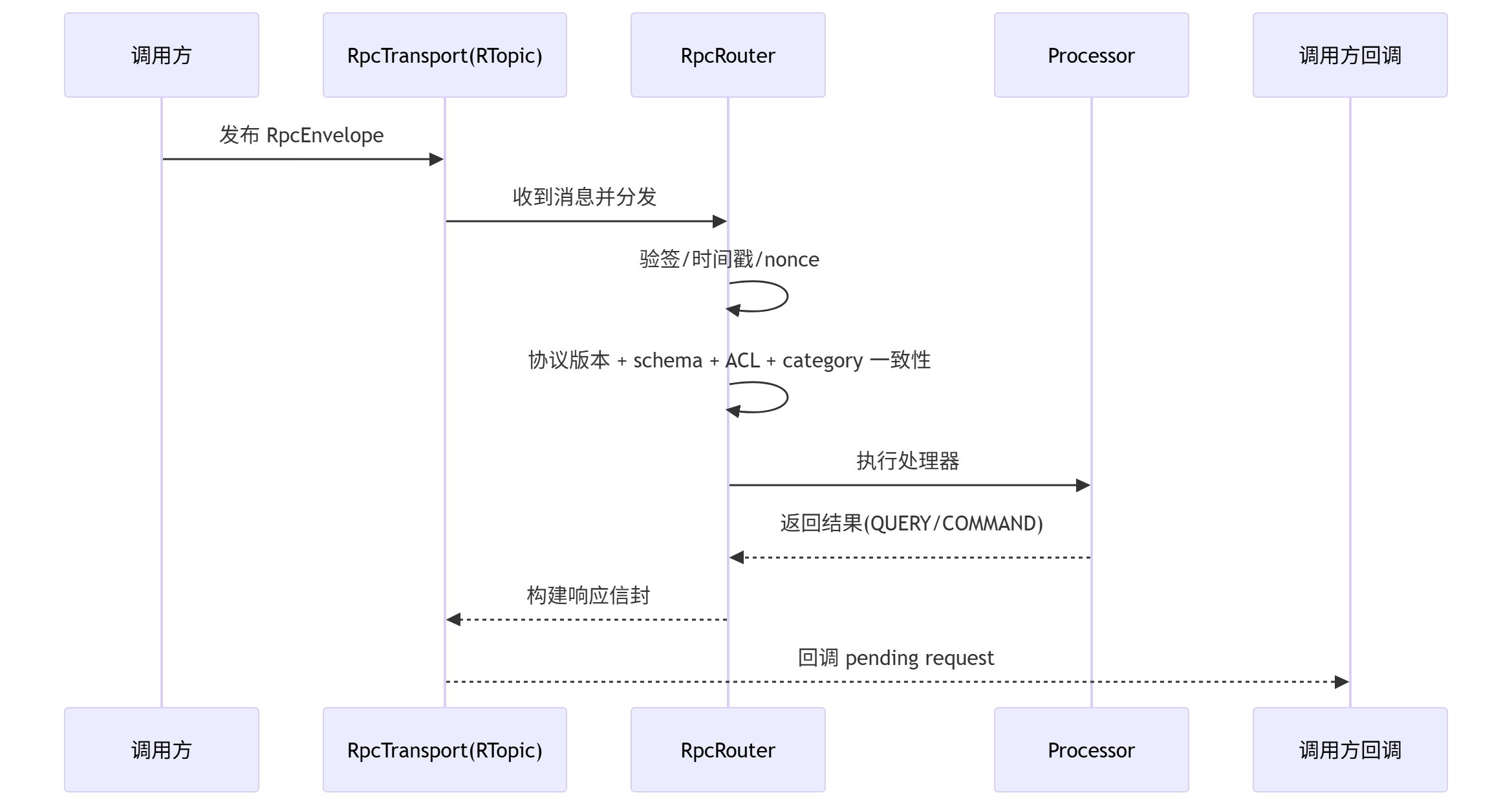
处理顺序上的重点是:
- 安全校验先于业务执行;
envelope.category必须和 descriptor.category 一致;EVENT没有响应包,QUERY/COMMAND才回响应。
7.5 第三方的调用示例
1) 注册处理器
java
public final class ChatRpcBootstrap {
public static void register() {
ServerSyncAPI serverSync = APIProvider.getAPI().serverSync();
ServerSyncRPCAPI rpc = serverSync.rpc();
// QUERY:查询在线人数
rpc.onQuery("chat.online.count", ChatOnlineQuery.class, (ctx, req) ->
new ChatOnlineResp(org.bukkit.Bukkit.getOnlinePlayers().size())
);
// COMMAND:执行跨服静音(有副作用,处理器要幂等)
rpc.onCommand("chat.mute.player", MuteCommand.class, (ctx, req) -> {
boolean ok = MuteService.mute(req.playerId(), req.minutes(), req.opId());
return new MuteResult(ok);
});
// EVENT:广播聊天提示(无返回)
rpc.onEvent("chat.notify", ChatNotifyEvent.class, (ctx, req) ->
org.bukkit.Bukkit.broadcastMessage("[跨服] " + req.message())
);
}
}2) 发起调用
java
ServerSyncAPI serverSync = APIProvider.getAPI().serverSync();
// QUERY 到指定服务器
serverSync.rpc()
.toServer("lobby-1")
.query(new ChatOnlineQuery("global"), ChatOnlineResp.class, 1500L)
.thenAccept(resp -> {
System.out.println("lobby-1 在线: " + resp.online());
});
// COMMAND 到玩家所在服务器(自动路由)
serverSync.rpc()
.toPlayer(playerUuid)
.command(new MuteCommand(playerUuid, 10, "op:20260308:1001"), MuteResult.class, 2500L)
.handle((resp, error) -> {
if (error != null) {
System.out.println("静音失败: " + error.getMessage());
return;
}
System.out.println("静音结果: " + resp.ok());
});
// EVENT 广播
serverSync.rpc()
.broadcast()
.event(new ChatNotifyEvent("全服维护倒计时 5 分钟"));
// queryAll:向指定 tag 组并发查询
serverSync.rpc()
.toTag("dungeon")
.queryAll(new DungeonLoadQuery(), DungeonLoadResp.class, 1200L)
.thenAccept(multi -> {
multi.getSuccesses().forEach((server, load) ->
System.out.println(server + " -> " + load.players())
);
multi.getFailures().forEach((server, ex) ->
System.out.println(server + " 查询失败: " + ex.getMessage())
);
});第八章:审计系统与链路追踪
8.1 审计系统在解决什么问题
一个实际的问题就是:业务里最常见的问题不是报错,报错总能修掉,最害怕的是数据变了但你说不清是谁改的。
比如:
- 玩家说东西突然少了;
- 某次活动奖励发重了;
- 你知道是跨服流程触发的,但不知道哪一段改了值。
审计系统要回答的就是四件事:
- 谁改的(actor)
- 为什么改(reason)
- 改了哪一个字段(field_key)
- 这次改动属于哪条业务链路(traceId/requestId)
8.2 SS的审计模型
SS内每次数据变更会拆成“字段级行记录”。
也就是 gold 改一次是一条,diamond 改一次又是一条。
示意结构如下:
sql
CREATE TABLE ss_{region}_audit_log (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
owner_type VARCHAR(16) NOT NULL, -- player / global
owner_id VARCHAR(128) NOT NULL, -- 玩家 UUID 或聚合 ID
domain VARCHAR(64) NOT NULL, -- 如 wallet / profile
field_key VARCHAR(64) NOT NULL, -- 如 gold
old_value TEXT NULL,
new_value TEXT NULL,
actor VARCHAR(128) NOT NULL,
reason VARCHAR(128) NULL,
trace_id VARCHAR(64) NOT NULL,
request_id VARCHAR(64) NOT NULL,
server_name VARCHAR(64) NOT NULL,
ts BIGINT NOT NULL
);这样做的直接好处是:
- 查询“某个字段历史”非常直接;
- 做风控规则更简单(比如只盯
wallet.gold); - 不需要每次解析大 JSON 差异。
8.3 写入策略:同步审计 + 异步审计
不是所有审计都要同步写。
SS现在按字段元信息分两条路径:
audited=true && auditAsync=false:事务内同步写(强一致);audited=true && auditAsync=true:先入异步缓冲,再批量刷库(允许高吞吐)。
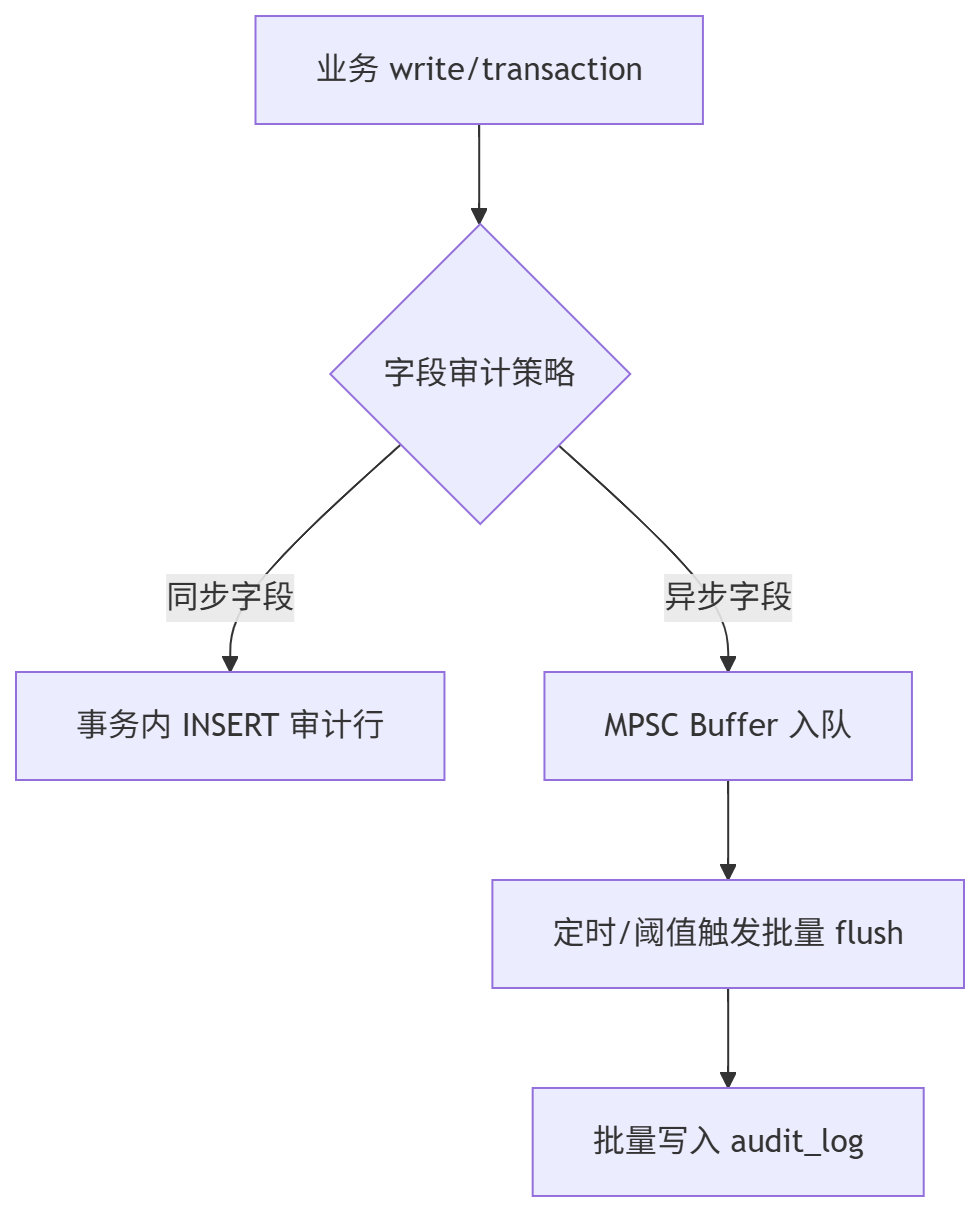
在业务侧SS要求写操作要带 APIOperationContext。
上下文里至少要有 actor + reason,最好再带固定 traceId。
java
UUID playerId = player.getUniqueId();
ServerSyncDataNamespaceAPI economy =
APIProvider.getAPI().serverSync().data().namespace("economy");
APIOperationContext ctx = APIOperationContext.of(
"DungeonPlugin",
"boss_kill_reward",
"trace:dungeon:run_456"
);
economy.transaction()
.player(playerId)
.context(ctx)
.write("wallet", editor -> {
int oldGold = editor.getOrDefault("gold", 0);
editor.set("gold", oldGold + 150);
})
.commit()
.handle((result, error) -> {
if (error != null) {
System.out.println("奖励写入失败: " + error.getMessage());
return;
}
System.out.println("写入成功,提交条数: " + result.getWrites());
});8.4 审计查询的用法
java
var audit = APIProvider.getAPI().serverSync().audit();
// 1) 按 owner 查最近记录
var ownerLogs = audit.queryByOwner("player", playerId.toString(), "wallet", 50);
// 2) 按 traceId 查整条链路
var traceLogs = audit.queryByTraceId("trace:dungeon:run_456");
// 3) 按时间范围查某域
long now = System.currentTimeMillis();
var rangeLogs = audit.queryByTimeRange(
"player",
playerId.toString(),
"wallet",
now - 3600_000L,
now,
200
);这样你拿到的每条记录都带:
fieldKeyoldValue/newValueactor/reasontraceId/requestIdserverName/ts
第九章:性能优化与监控
9.1 SS遇到的历史性能瓶颈
常见的瓶颈
| 瓶颈点 | 表现 | 原因 |
|---|---|---|
| 数据库连接 | 高并发时超时 | 没连接池(使用HirakiCP) |
| 锁等待 | 写入延迟高 | 锁粒度太粗(使用分布式锁) |
| 序列化 | CPU 占用高 | JSON 序列化慢(使用优化的Gson,并在以后考虑换为Apache Fory) |
9.2 缓存优化
本地缓存
对于频繁读取的数据,考虑加本地缓存,这里用Caffeine:
kotlin
class WalletReadCache(
private val ns: ServerSyncDataNamespaceAPI
) {
private val cache = Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build<String, DataSnapshot?>()
fun readPlayerWallet(playerId: UUID): DataSnapshot? {
val key = "player:$playerId:wallet"
return cache.get(key) {
ns.readPlayerDomain(playerId, "wallet")
}
}
fun invalidatePlayerWallet(playerId: UUID) {
cache.invalidate("player:$playerId:wallet")
}
}缓存失效策略
这里通过 Redis Pub/Sub 通知其他服务器失效缓存:
kotlin
// 写入后发布事件
redis.getTopic("cache_invalidate").publish(
CacheInvalidateEvent(owner, domain)
)
// 订阅事件
redis.getTopic("cache_invalidate").addListener { event ->
cache.invalidate("${event.owner}:${event.domain}")
}9.3 考虑批量操作
批量读取
kotlin
fun batchRead(requests: List<Pair<String, String>>): Map<Pair<String, String>, DataSnapshot> {
val sql = """
SELECT owner_id, domain, fields, version
FROM ss_{region}_{ownerType}_{domain}
WHERE (owner_id, domain) IN (${requests.joinToString { "(?, ?)" }})
"""
val results = jdbc.query(sql, ...).associateBy { it.owner to it.domain }
return results
}批量写入
使用 JDBC batch update:
kotlin
fun batchWrite(updates: List<UpdateRequest>) {
jdbc.batchUpdate(
"UPDATE ss_{region}_{ownerType}_{domain} SET <changed_columns>, version = version + 1 WHERE ...",
updates.map { arrayOf(it.owner, it.domain) }
)
}全文完
全部评论 (0)
暂无评论,快来抢沙发吧~