前言
主要参考为
- 《统计学习》—李航(蓝皮)
- 《机器学习》—周志华(西瓜书)
- 部分来自网络的内容(liaohuiqiang的博客为主,感谢他!)
统计学习(机器学习)
- 学习:Herber A. Simon曾对“学习”给出以下定义:“如果一个系统能够通过执行某个过程改进它的性能,这就是学习”。
- 统计学习:统计学习就是计算机系统通过运用数据及统计方法提高系统性能的机器学习。现在人们提及的机器学习,往往就是指统计机器学习。
- 统计学习的前提:统计学习关于数据的基本假设是同类数据具有一定的统计规律性。由于它们具有统计规律性,所以可以用概率统计方法来加以处理。比如,可用随机变量描述数据中的特征,用概率分布描述数据的统计规律。
- 统计学习包括:监督学习,无监督学习,强化学习,半监督学习、主动学习
- 统计学习的三要素:模型,策略,算法
模型
-
模型和假设空间:统计学习首要考虑的问题是学习什么样的模型。监督学习中,模型就是所要学习的条件概率分布或决策函数,模型的假设空间包含所有可能的条件概率分布或决策函数。
- 决策函数族:假设空间可以定义为决策函数的集合,
\mathcal{F}=\{f|Y=f_{\theta}(X),X\in R^n\} - 条件概率分布族:假设空间也可以定义为条件概率的集合,
\mathcal{F}=\{P|P(Y|X)=f_{\theta}(X),X\in R^n\}
- 决策函数族:假设空间可以定义为决策函数的集合,
-
概率模型和非概率模型:用决策函数表示的模型为非概率模型,用条件概率表示的模型为概率模型。有时模型兼有两种解释,既可以看作概率模型,也可以看作非概率模型。为了简便起见,当论及模型时,有时只用其中一种模型。
策略(损失函数)
常用损失函数:
- 0-1损失:L(Y,f(x))=\left\{\right . \begin{matrix}0 & Y= f(X)\\1 & Y\ne f(X)\end{matrix}
- 平方损失:L(Y,f(X))=(Y-f(X))^2
- 绝对损失:L(Y,f(X))=|Y-f(X)|
- 对数损失:L(Y,f(X))=-\log(P(Y|X))
期望风险与经验风险
- 期望风险:理论上模型f(X)关于联合分布P(X,Y)下的平均意义下的损失,称为期望风险(expected risk)。学习的目的是选择期望风险最小的模型,但是实际上因为联合分布P(X,Y)是未知的,我们通常不能直接得到它
R_{exp}(f)=E_P[L(Y,f(X))]=\int_{\mathcal{X}\times\mathcal{Y}}L(Y,f(X))P(X,Y)dxdy
即损失·概率的连续和(积分),“损失的期望”是这么来的 - 经验风险:模型关于训练数据的平均损失,称为经验风险(empirical risk)。根据大数定律,当样本N趋于无穷时经验风险会无限趋近于期望风险,故我们可以用经验风险来估计期望风险。经验风险最小的模型我们认为是最优的模型
R_{emp}(f)=\frac{1}{N}\sum_{i=1}^{N}L(y_i,f(x_i))
我们的最优模型f^*,就可以表示为
f^*=\min_{f\in \mathcal{F}}R_{emp}(f)
结构风险最小化
结构风险最小化:现实中训练样本有限,甚至很小,需要对R_{emp}进行矫正。结构风险最小化(structure risk minimization)是为了防止过拟合(见下方)提出来的策略,在经验风险的基础上加上表示模型复杂度的正则化项或者惩罚项
算法(最优化算法)
-
算法到最优化:统计学习基于训练集(data),根据学习策略(loss),从假设空间中选择最优模型(model),最后需要考虑用什么算法(algorithm)求解最优模型。这时,统计学习问题归结为最优化问题,统计学习的算法称为最优化问题的算法。
-
最优化:如果最优化问题有显式的解析解就比较简单,但通常解析解不存在,这就需要用数值计算的方法来求解。如何保证找到全局最优解,并使求解的过程高效,就成为一个重要问题。统计学习可以用已有的最优化算法(常用的有梯度下降法,牛顿法和拟牛顿法),有时也需要开发独自的优化算法。
模型评估与模型选择(重要)
评估标准
评估标准:当损失函数给定时,基于损失函数的模型的训练误差和测试误差就自然称为学习方法的评估标准。注意,统计学习方法具体采用的损失函数未必是评估时使用的损失函数,当然,让二者一致是比较理想的(现实中由于0-1损失不是连续可导的,评估时用0-1损失,训练时使用另外的损失,比如分类任务中大多用对数损失)。
训练误差
训练误差:模型关于训练集的平均损失(就是经验损失R_{emp}(f))。训练误差的大小,对判断给定问题是不是一个容易学习的问题是有意义的,但本质上不重要。
测试误差
测试误差:模型关于测试集的平均损失e_{test}(当损失函数是0-1损失时,测试误差就变成了测试集上的误差率error rate,误差率加准确率为1)。测试误差反映了学习方法对未知的测试数据集的预测能力,通常将学习方法对未知数据的预测能力称为泛化能力。
模型选择
模型选择:当假设空间含有不同复杂度(例如,不同的参数个数)的模型时,就要面临模型选择的问题,我们希望学习一个合适的模型。如果假设空间中存在“真”模型,那么所选择的模型应该逼近“真”模型。
过拟合和欠拟合
- 过拟合:如果一味追求提高对训练数据的预测能力,所选模型的复杂度往往会比“真”模型更高,这种现象称为过拟合。过拟合是指学习时选择的模型所包含的参数过多,以至于出现这一模型对已知数据预测得很好,但对未知数据预测很差的现象。
- 欠拟合:如果限制模型复杂度,降低拟合能力,可能会欠拟合,未能很好的捕捉数据的模型和特征,导致在训练和测试数据上表现均较差
正则化
正则化是结构风险最小化策略的实现,是在经验风险上加上一个正则化项或惩罚项。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值越大。正则化项可以是模型参数向量的范数,比如L_1范数或L_2范数。如下式子回归问题中的平方损失加L_2范数。
::: align-center
L(\omega)=\frac{1}{N}\sum_{i=1}^{n}f(x_i,\omega)^2+\frac{\lambda}{2}||\omega||^2_2
:::
正则化符合奥卡姆剃刀原理:在所有可能选择的模型中,能够很好地解释已知数据并且十分简单才是最好的模型,也就是应该选择的模型。
训练测试与验证
训练/验证/测试:如果样本充足,模型选择的一个简单方法是把数据随机划分为训练集,验证集,测试集。训练集用来训练模型,验证集用于模型的选择,测试集用于最终对学习方法的评估。在学习到的不同复杂度的模型中,选择对验证集有最小预测误差的模型,由于验证集有足够多的数据,这样进行模型选择是有效的。
但是实际应用中数据是不充足的,为了选择好的模型,可以采用交叉验证的方法。其基本思想是重复使用数据,划分为训练集和测试集,在此基础上反复训练,测试以及模型选择。
- 简单交叉验证:随机划分两部分数据,一部分作为训练集,一部分作为测试集(比如三七分)。然后用训练集在各种条件下(比如不同的参数个数)训练模型,在测试集上评价各个模型,选择测试误差最小的模型。
- S折交叉验证(应用最多):随机切分成S个互不相交,大小相同的子集;用S-1个子集的数据训练模型,余下的子集做测试;将可能的S种选择重复进行,会得到一个平均误差;选择平均测试误差最小的模型作为最优模型。
- 留一交叉验证:S折交叉验证的特殊情形是S=N(样本容量),称为留一验证,往往在数据缺乏的情况下使用。
泛化能力
- 泛化能力:学习方法的泛化能力指由该方法学习到的模型对未知数据的预测能力。
- 测试误差:现实中采用最多的办法是通过测试误差来评价学习方法的泛化能力,但这种评价是依赖于测试数据集的,因为测试数据集是有限的,很有可能由此得到的评价结果是不可靠的。
- 泛化误差:泛化误差就是学习到的模型的期望风险。
性能度量
对学习器的泛化能力进行评估,不仅需要有效的可行的实验估计方法,还需要有衡量模型泛化能力的评价标准,这就是性能度量(performance measure)。要评估学习器f的性能,就需要把学习期预测结果f(x)同真实标记y进行比较
错误率与精度
- 错误率:分类错误样本数占样本总数的比例
对数据集D,错误率为E(f,D)=\frac{1}{m}\sum_{i=1}^{m}\mathbf{I}(f(x_i)\ne y_i) - 精度:分类正确的样本数占样本总数的比例
对数据集D,精度为Acc(f,D)=\frac{1}{m}\sum_{i=1}^{m}\mathbf{I}(f(x_i)= y_i)
I为一个指示函数,在符合条件时为1,不符合时为0
查准率,查全率与F1
对于二分类任务,可将样例根据其真实类别与学习器预测类别的组合划分为几种类别
- TP(True Positive):真正例
- TN(True Negatvie):真负例
- FP(False Positive):假正例
- FN(False Negative):假负例
均是对从学习器的角度出发说的
| 真实\预测 | 正 | 负 |
|---|---|---|
| 正 | TP | FN |
| 负 | FP | TN |
- 查准率(Precision):P=\frac{TP}{TP+FP},即学习器预测为正结果中,有多少是真为正的
- 查全率(Recall):R=\frac{TP}{TP+FN},即实际为正的结果中,学习器找到了多少为正的
二者均是针对正例而言的,一般情况下二者相互矛盾,查准率高查全率就低
P-R曲线的平衡点与F1度量
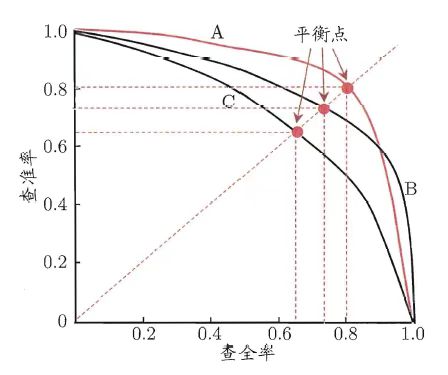
- 越靠右上越好
- 平衡点BEP:如果一个学习器的P-R曲线完全包裹了另一个,则认为前者性能由于后者,但是如果出现交点(比如图中A,B的情况)时,就需要引入平衡点(Break-Event Point, BEP)来度量优劣,平衡点是查准率=查全率时的取值
- F1度量:BEP太过简化,更多常用F1度量,\frac{2}{F1}=\frac{1}{P}+\frac{1}{R}
ROC与AUC
很多学习器都是为测试样本产生一个实值或者概率预测,然后将这个预测值与一个分类阈值去比较,若大于阈值则分为正类,否则为负类,实际上可将测试样本进行排序,“最可能是正例”排在最前面,“最不可能”是正例排在后面。排序本身的质量好坏,体现了学习器的“期望泛化性能”的好坏,ROC就是从这个角度出发去研究学习器泛化性能的有力工具
- ROC曲线的纵轴是“真正例率”(True Positive Rate, TPR)TPR=\frac{TP}{TP+FN},是前面的查全率的另一种说法
- 横轴是“假正例率”(False Positive, FPR)
FPR=\frac{FP}{FP+TN} - 越靠左上越好
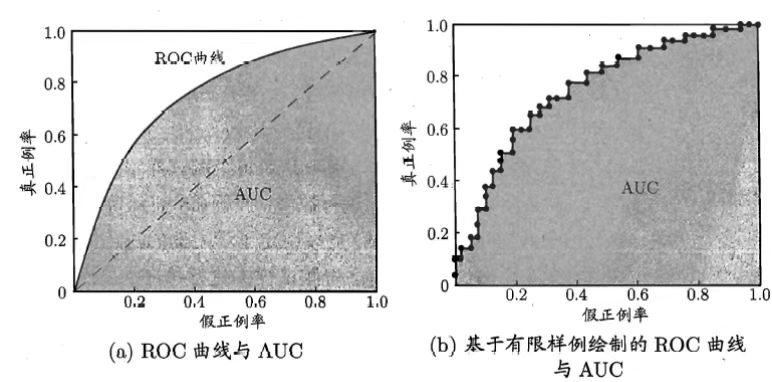
- AUC(Area Under ROC Curve):表示ROC曲线下的面积,当一个学习器的ROC曲线完全包裹另一个时此学习器性能较好,但如果有交点,则此时AUC大的那个学习器性能较好,AUC的最大值为1
全部评论 (0)
暂无评论,快来抢沙发吧~