前言
本篇章主要围绕R语言,但较为杂乱,可能还含有以下内容
- 概率统计
- 机器学习
目前笔者暂无多余精力整理,读者请酌情阅读
R绘图(ggplot2库)
::: align-center
ggplot(data) + aes(x, y) + geom() + theme()
:::
- data:绘图数据集
- aes(x,y,color):美学映射,即数据集到图像横纵轴的映射,color项传入一个向量决定颜色
- geom:需要绘制图像的类型,可选
- geom_point:散点图
- geom_line:线状图
- geom_histogram:直方图
- geom_boxplot:箱图
- geom_density:密度图(数据密度)
- theme:主题,不做概述
其他
- labs(title, x, y):定义图像的大标题,x轴描述和y轴描述,传入字符串
- scale_color_manual(values)和scale_fill_manual(values):手动定义填充颜色集,传入向量(内部为颜色字符串)
- facet wrap() and facet grid(): 用于“分面”作图(见下)
实战
直方图
情景:画出mtcars数据集中不同车型的每加仑可行驶里程数(miles per gallon)
R内置直方图
R
# 载入数据集
data ( mtcars )
# 画图
# breaks为分组方式,可取数字或字符串
# 当取字符串时,有"Sturges","Scott", "FD",分别对应根据数据大小分组/根据Scott公式计算分组,使用近似正态分布的数据/使用FD公式计算分组,适用于有偏分布或有离群值的数据
# 当取数字时,即人为规定将数据分为指定个组
hist (
mtcars$mpg,
col =" lightblue ",
breaks =10 ,
main =" Histogram of Miles Per Gallon ",
xlab =" Miles Per Gallon " , ylab =" Frequency ",
border =" black "
)ggplot2
library ( ggplot2 )
# 这里的bin和上面的breaks类似
ggplot (data = mtcars , aes (x = mpg)) +
geom_histogram (
bins =10,
fill =" lightblue ",
color =" black "
) +
labs (
title =" Distribution of Miles Per Gallon ",
x =" Miles Per Gallon" , y =" Frequency "
) +
theme_classic ()箱线图
首先是箱线图的介绍
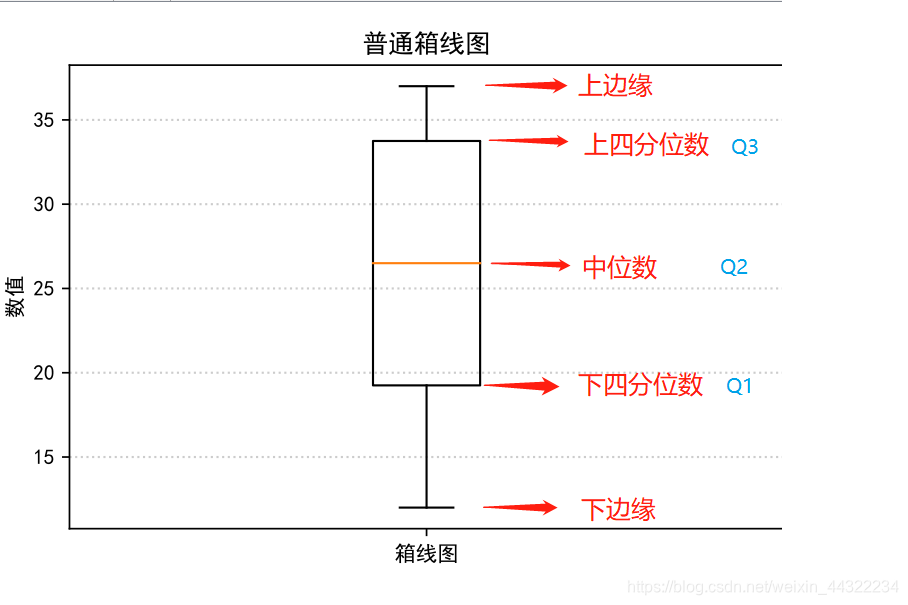
- “箱”(Box):即四分位数范围Q_3-Q_1,对应25%-75%,此部分描述的是位于中间50%的数据 Q_1=X_{\lfloor \frac{n+1}{4}\rfloor},Q_3=X_{\lfloor{\frac{3(n+1)}{4}}\rfloor}
- 中位数(Median):不多解释,可反映数据的“平均”趋势
- 上下边缘组成的“触须”(Whisker):上边缘和下边缘分别对应上/下四分位数\pm四分数范围\times 1.5
- 离群值(Outliers):在“触须”上下的值
R内置箱线图
R
# 加载数据集
data ( mtcars )
# 绘图
# 第一个参数传入公式 绘图变量 ~ 分类变量(factor)
# 这里绘图变量选定为上面的miles per gallon,同时使用as.factor将数据集中的cyl转换为分类变量
boxplot (
mpg ~ as.factor ( cyl ) ,
data = mtcars ,
col =" lightblue ",
main =" Miles Per Gallon by Number of Cylinders ",
xlab =" Number of Cylinders ", ylab =" Miles Per Gallon "
)ggplot2
R
library ( ggplot2 )
# Create a box plot using ggplot2
ggplot (
data = mtcars ,
aes (x = as.factor ( cyl ), y = mpg , fill = as.factor ( cyl ))
) +
geom_boxplot () +
labs (
title =" Miles Per Gallon by Number of Cylinders ",
x =" Number of Cylinders " , y =" Miles Per Gallon"
) +
theme_classic () +
scale_fill_manual ( values =c (" lightblue ", " lightgreen ", "lightcoral ") )在实际处理数据时,我们通常会遇到数据量纲不统一,个别数据缺失或异常等问题,通常我们会使用箱线图来识别离群的数据
密度图
简介
此绘图方式可以绘制出连续型随机变量的概率密度函数(PDF),在概率论中,(单变量)连续型随机变量的概率分布函数(CDF)F(x)与概率密度函数的关系为
::: align-center
F(x)=\int_{-\infty}^{x}f(x)dx
:::
通常f(x)没有解析解,故绘图困难,要从数据中估计f(x)的大致形状,一种经典算法是核密度估计(Kernal Density Estimate, KDE)
粗略阐述KDE
KDE是机器学习中的经典算法,假设随机变量X的概率分布函数为F(x),因为概率密度函数f(x)是概率分布函数F(x)的导数,那么由导数定义有
::: align-center
f(x)=\lim_{h\to 0}\frac{F(x+h)-F(x-h)}{2h}
:::
现在我们假设要求x处的密度函数值,根据上面的思想,可取邻域[x-h,x+h],当h大于0且足够小时,我们便能把此邻域的密度函数值当做此点的密度函数值
::: align-center
\hat{f(x)}=\frac{1}{2h}\lim_{h\to 0}\frac{N_{x_i\in[x-h,x+h]}}{N_{total}}
:::
其中N_{x_i\in[x-h,x+h]}是该邻域中样本点数量,N_{total}是样本集总数量
由此可见,h的选择非常重要,因为如果h太大则违背了h\to 0,h太小那么用于估计f(x)的样本点会很少,由于我们只拥有有限个样本点故h也不能太小,此时
::: align-center
\hat{f(x)}=\frac{1}{2hN_{total}}\sum_{i=x-h}^{i=x+h}x_i=\frac{1}{2hN_{total}}\sum_{i}\frac{|x-x_i|}{h}
:::
此外还存在一个严重问题:那就是概率密度函数依然不够平滑,虽然我们得到了f(x)的估计,但这些估计终究估计的是某一个点的值而不是函数任意部分的值,且按照概率论,单变量时概率密度函数在[-\infty,\infty]上的积分应为1,而此时很显然我们是无法满足这个要求的,因为我们的估计都是离散的,又怎能进行积分(连续求和)呢
所以此时我们需要假设存在已知的概率密度函数K(x),使\hat{f(x)}=\frac{1}{2hN_{total}}\sum_{i}K(\frac{|x-x_i|}{h})
此时
\begin{aligned}
&\int_{-\infty}^{\infty}\frac{1}{2hN_{total}}\sum_{i}K(\frac{|x-x_i|}{h})dx\\
&=\int_{-\infty}^{\infty}\frac{1}{2N_{total}}\sum_{i}K(t)dt\\
&=\frac{1}{2}\int_{-\infty}^{\infty}K(t)dt
\end{aligned}
因为K(x)是已知的概率密度函数,它的积分一定为1,作简单变换让其积分为2即可满足让上式的积分为1
几个概念
- x_i:已观测点(或先验点)Observed data point
- n:总观测数 Total number of observation
- K(x):核函数 Kernel Function
- h:带宽 Bandiwidth
R中的密度图
继续回到R语言,简要介绍如何绘制密度图
R内置
R
# 载入数据集
data ( mtcars )
# 可用density()函数估计概率密度函数
# lwd: Line Width 线粗细
plot (
density ( mtcars$mpg ) ,
col =" blue ",
lwd =2 ,
main =" Density Plot of Miles Per Gallon ",
xlab =" Miles Per Gallon " , ylab =" Density "
)ggplot2
R
library ( ggplot2 )
# Create a density plot using ggplot2
ggplot (
data = mtcars ,
aes ( x = mpg )
) +
geom_density (
fill =" lightblue ",
color =" black ",
alpha =0.5
) +
labs (
title =" Kernel Density Estimate of Miles Per Gallon ",
x =" Miles Per Gallon ", y =" Density "
) +
theme_classic ()茎叶图
茎叶图是一种显示数值分布的图,它的思路是将数按位数进行比较,将数的大小基本不变或变化不大的位作为主干(茎),将变化的位的数作为分支(叶),列在主干的后面,这样就可以清楚地看到每个主干后面的几个数,每个数具体是多少
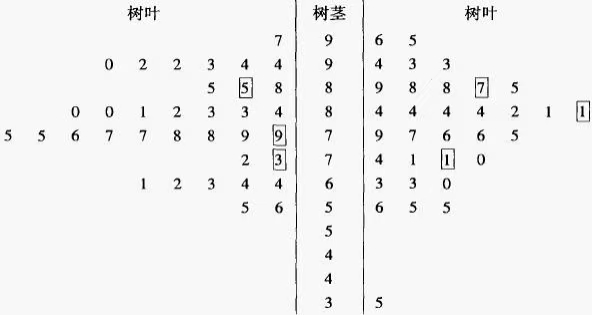
例如:数据为23,25,27,32,35
则茎叶图为:
2 | 3 5 7
3 | 2 5
下面介绍在R中如何绘制茎叶图
R
# 数据集
data <- c (23 , 25 , 27 , 32 , 35 , 40 , 42 , 45 , 47 , 50 , 53 , 55)
# 添加标题并绘图
cat (" Stem - and - Leaf Plot :\ n ")
stem ( data )ggplot2分面作图
ggplot2支持“分面作图”,这里的“分面”指的是一页多图,而不是一图多“面”
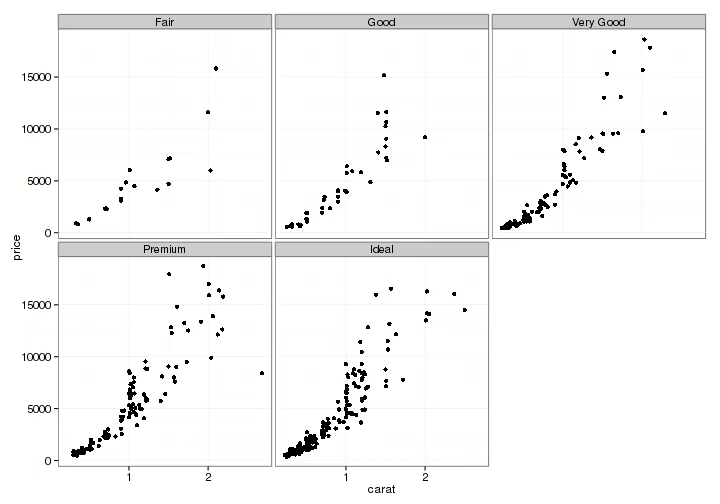
缠绕分面 facet_wrap
此方法下对数据只能用一个标准分类,分类后的数据绘制出的图像将从左到右,从上到下按照“缠绕”顺序进行排列
使用方法
R
+ facet_wrap(~ 分类变量)e.g. 一个分类变量为
::: align-center
c("Fair", "Good", "Very Good", "Premium", "Ideal")
:::
则图会为这样
网格分面 facet_grid
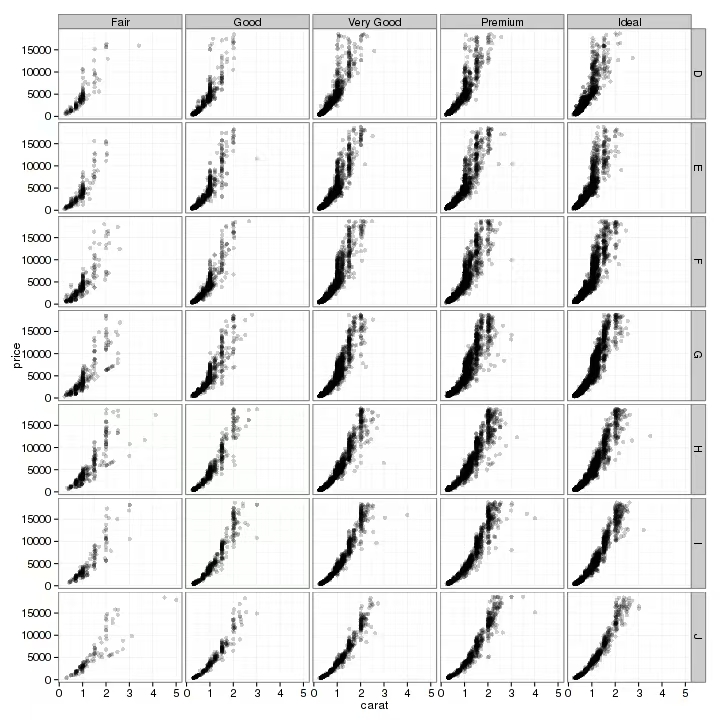
按照两个标准对数据分类
使用方法
R
+ facet_grid(纵列分类变量 ~ 横列分类变量)e.g 新增一个分类变量
::: align-center
c("D", "E", "F", "H", "I", "J")
:::
为纵列分类变量,则图会变为
抽样 Sampling
概念回顾
- 总体(Population):包含了所有可能的观测值或个体
- 样本(Sample):总体中选取的一部分,目的是代表总体,使我们能够通过研究样本来了解和推断总体特征。样本的选择通常基于随机性以确保其代表性
抽样方法
- 简单随机抽样(simple random sampling, SRS):不多解释
- 分层抽样(stratified sampling):先按照某种规则把总体划分为不同的层,然后在层内用其他方法抽样,特别地,当各层使用SRS时称为分层随机抽样
- 整群抽样(cluster sampling):先把总体中的个体划分为称作群的单个组,然后以群为单位抽取一个简单随机样本
- 系统抽样(systematic sampling):先将总体中的抽样单元按某种次序排列,在规定范围内随机抽取一个初始单元,然后按事先规定的规则抽取其他单元
- 方便抽样(convenience sampling):为配合研究主题而由调查者于特定的条件(时间、地点等)随意选择样本(比如询问目击者)的非概率抽样方法
R中的抽样
此部分暂未更新完全
R
# 假设总体是1到100这100个数
population <- 1:100
# 进行不放回随机抽样10次
sample_data <- sample ( population , size = 10 , replace = FALSE )
# 打印
print ( sample_data )期望 Expectation
概念回顾
对于离散型随机变量
::: align-center
E[X]=\sum_i x_iP(X=x_i)
:::
对于连续型随机变量,建设其概率密度函数为f(x)
::: align-center
E[x]=\int_{-\infty}^{\infty}xf(x)dx
:::
期望可以进行线性运算
::: align-center
E[aX+bY]=aE[X]+bE[Y]
:::
R中的期望
粗略介绍蒙特卡洛方法
在面对连续型随机变量时,通常难以找到\int_{-\infty}^{\infty}xf(x)dx的解析解,故我们可以使用蒙特卡洛方法,通过随机抽样来获得期望的估计
::: align-center
E[X]\approx\frac{1}{N}\sum_{i=1}^{N}X_i
:::
其中
- N:抽样次数
- X_i:抽样结果
根据大数定律(LLN),在N趋近无穷时我们的期望会无限接近理论期望
计算期望
对于离散型随机变量
R
probabilities
values <- c (1 , 2, 3, 4, 5)
probabilities <- c (0.1 , 0.2 , 0.3 , 0.2 , 0.2)
expected_value <- sum ( values * probabilities )
print ( expected_value )对于连续型随机变量,需要使用蒙特卡洛方法
R
# 假设连续型随机变量X遵循[0,1]内的均匀分布X~U(0,1)
set . seed (42) # 设置随机数种子方便复现结果
samples <- runif (10000) # 这个函数会从(0,1)内随机抽样10000次
# 计算抽样数据的平均值(蒙特卡洛)
expected_value_simulated <- mean ( samples )
# 打印
print ( expected_value_simulated )方差 Variance
概念回顾
一般定义
::: align-center
Var(X)=E[(X-E[X])^2]
:::
对于离散型随机变量
::: align-center
Var(X)=\sum_{i}(x_i-E[X])^2P(X=x_i)
:::
对于连续型随机变量
::: align-center
Var(X)=\int_{-\infty}^{\infty}(x-E[X])^2f(x)dx
:::
此外还可以得到方差的公式为
::: align-center
Var(X)=E[X^2]-E[X]^2
:::
方差运算并不遵循线性性
::: align-center
Var(aX+bY)=a^2Var(X)+b^2Var(Y)+2abCov(X, Y)
:::
其中Cov(X,Y)为二者的协方差(Covariance),在二者相互独立时它为0
将方差开根即可得到标准差(Standard Deviation)
::: align-center
\sigma_x=\sqrt{Var(X)}
:::
R中的方差和标准差
R
# 数据集
data <- c (5 , 7, 10 , 15 , 20)
# 使用var()函数计算方差
variance_value <- var ( data )
# 使用sd()函数计算标准差
std_dev <- sd ( data )
# 打印
print ( variance_value )
print ( std_dev )R中的相关系数
首先回忆相关系数的公式
::: align-center
\rho_{XY}=\frac{Cov(X,Y)}{\sqrt{D(X)\sqrt{D(Y)}}}=\frac{\sum(x_i-\overline{x})(y_i-\overline{y})}{\sqrt{\sum(x_i-\overline{x})^2}\sqrt{\sum(y_i-\overline{y})^2}}
:::
在R中,处理相关系数的函数为cor(x, y)
R
# 以mtcars数据集为例
data ( mtcars )
# 计算汽车的马力 ( hp ) 和每公里油耗的相关系数( mpg )
cor_hp_mpg <- cor ( mtcars$hp , mtcars$mpg )
全部评论 (0)
暂无评论,快来抢沙发吧~