前言
参考:
- 机器学习—周志华(西瓜书)
- 部分网络的内容(主要是CHH3213的博客)
- 高教社《高等代数》
- 浙大《概率论与数理统计》第五版
线性回归
介绍
- 线性:两个变量之间的关系是一次函数关系的——图象是直线,叫做线性。
- 非线性:两个变量之间的关系不是一次函数关系的——图象不是直线,叫做非线性。
- 回归:人们在测量事物的时候因为客观条件所限,求得的都是测量值,而不是事物真实的值,为了能够得到真实值,无限次的进行测量,最后通过这些测量数据计算回归到真实值,这就是回归的由来。
线性回归问题就是试图学到一个线性模型尽可能准确地预测新样本的输出值。解决的就是通过已知的数据得到未知的结果。例如:对房价的预测、判断信用评价、电影票房预估等。
分析
有时输入的属性值并不能直接被我们的学习模型所用,需要进行相应的处理。
- 对于连续值的属性,一般都可以被学习器所用,有时会根据具体的情形作相应的预处理,例如:归一化等;
- 对于离散值的属性,可作下面的处理:
若属性值之间存在“序关系”,则可以将其转化为连续值,例如:身高属性分为“高”“中等”“矮”,可转化为数值:{1, 0.5, 0}。
若属性值之间不存在“序关系”,则通常将其转化为向量的形式,例如:性别属性分为“男”“女”,可转化为二维向量:{(1,0),(0,1)}。
一元线性回归(机器学习角度建模)
模型
假设我们的数据为\mathbf{x}=\begin{bmatrix}x_1\\x_2\\\vdots\\x_n\end{bmatrix}和\mathbf{y}=\begin{bmatrix}y_1\\y_2\\\vdots\\y_n\end{bmatrix}
则模型为
::: align-center
f(x_i)=\omega\cdot x_i+b
:::
策略
我们将均方误差MSE作为损失函数,在下面的算法中尝试最小化它来计算\omega和b
::: align-center
\begin{aligned}
&(\omega^*,b)=\arg \min\sum_{i=1}^{m}(y_i-f(x_i))^2(MSE)\\
&=\arg \min\sum_{i=1}^{m}(y_i-\omega x_i-b)^2\\
&E(\omega,b)=\sum_{i=1}^{m}(y_i-\omega x_i-b)^2
\end{aligned}
:::
算法
此时可使用解析方法求解
::: align-center
\begin{aligned}&\frac{\partial E}{\partial \omega}=0\\
&\frac{\partial E}{\partial b}=0
\end{aligned}
:::
解方程可得
::: align-center
\begin{aligned}
&\omega=\frac{\sum_{i=i}^{m}y_i(x_i-\overline{x})}{\sum_{i=1}^{m}x_i^2-\frac{1}{m}(\sum_{i=1}^mx_i)^2}\\
&b=\frac{1}{m}\sum_{i=1}^m(y_i-\omega x_i)
\end{aligned}
:::
此值一定在最小值点取到,读者可自行使用Hessian矩阵验证,由柯西-施瓦兹不等式可得Hessian矩阵正定
上方的\omega此表达式还有几种形式,常见的还有
::: align-center
\omega=\frac{S_{XY}}{S_{XX}}=\frac{\sum_i(X_i-\bar{X})(Y_i-\bar{Y})}{\sum_i(X_i-\bar{X})^2}=\frac{\sum_i X_iY_i-n\bar{X}\bar{Y}}{\sum_i X_i^2-n\bar{X}^2}
:::
截距为
::: align-center
b=\bar{Y}-\omega\bar{X}
:::
OLS(线性代数角度建模)
假设我们有一个包含N_p个数据点的数据集,对于每个数据点i,我们有一个特征向量x_i和真实值y_i,目标是找到一个函数(模型),能够根据x来预测y,现在我们使用一元线性模型
::: align-center
\hat{y}=mx+c
:::
其中:
- \hat{y}是预测值
- m是斜率
- c是截距
我们将c和m组合为一个参数向量\theta:
::: align-center
\theta=(c,m)^T
:::
同样的,可以将所有的特征数据构造成一个设计矩阵(Design Matrix)X,它带有一列偏置:
::: align-center
X=\begin{pmatrix}1&x_1\\1&x_2\\\vdots&\vdots\\1&x_{N_p}\end{pmatrix}
:::
则有:
::: align-center
\hat{y}=X\theta
:::
损失使用MSE
::: align-center
\mathcal{E}(\theta)=\frac{1}{N_p}\sum_{i=1}^{N_p}(y_i-\hat{y}_i)^2=\frac{1}{N_p}||y-X\theta||_2^2
:::
这里我们使用另一种方法——变分法来解决问题,考虑给当前参数\theta加上一个微小的扰动向量v,因为N_p不影响最小化的位置,我们暂时忽略它,现在损失变为
::: align-center
N_p\mathcal{E}(\theta+v)=||y-X(\theta+v)||_2^2=||y-X\theta-Xv||_2^2
:::
将其展为内积
::: align-center
\begin{aligned}
||y-X\theta-Xv||_2^2&=
:::
因为有
::: align-center
:::
所以原式
::: align-center
\begin{aligned}
&=||y-X\theta||_2^2+2
:::
故有
::: align-center
\mathcal{E}(\theta+v)=\mathcal{E}(\theta)+\frac{2}{N_p}
:::
观察第三项\frac{1}{N_p}||Xv||_2^2,它总大于0
关键在第二项\frac{2}{N_p}
因此为了确保\theta点任何微小的移动v都不会让成本减小,唯一的办法就是让此线性项的系数为零,即
::: align-center
X^T(X\theta-y)=0
:::
即
::: align-center
X^TX\theta=X^Ty
:::
这个方程被称为正规方程
当此条件满足时,成本函数的变化简化为
::: align-center
\mathcal{E}(\theta+v)=\mathcal{E}(\theta)+\frac{1}{N_p}||Xv||_2^2\ge\mathcal{E}(\theta)
:::
所以解析方法得到\theta可以通过求解正规方程得到
一元线性回归(统计学角度建模)
考虑样本对(x_i,y_i),其中y_i是在x_i确定时于联合概率分布f(x,y)中观察得到的,在这个角度下线性回归问题就与概率分布建立起了联系
现在考虑拟合x_i和y_i,使用拟合式:
::: align-center
y_i=\alpha+\beta x_i+\epsilon_i
:::
在统计学角度上我们将x称之为解释变量(Explanatory Variable),y称之为响应变量(Response Variable),\epsilon是误差
理想情况下,我们自然会想令误差的期望为0
::: align-center
E[\epsilon_i]=0,\forall i
:::
我们也希望拟合方程在任意点的误差与在其他点的误差无关
::: align-center
Cov[\epsilon_i,\epsilon_j]=0,\forall i\ne j
:::
我们也希望拟合方程在任意点的误差的方差都是同一个恒定的数
::: align-center
Var[\epsilon_i]=\sigma^2
:::
于是我们可以考虑假设误差的分布符合正态分布,一个\epsilon_i\in N(0,\sigma^2)的正态分布完美符合上述三条假设
有了分布假设,有了样本数据,在统计学上,我们就可以做参数估计了,而其中最为经典的方法莫过于极大似然估计,将拟合方程变换为:
::: align-center
\epsilon_i=y_i-\alpha-\beta x_i
:::
写出\epsilon_i关于x_i,y_i的似然函数
::: align-center
L(x_i,y_i)=\prod_{i}\frac{1}{\sqrt{2\pi}\sigma}\exp[-\frac{(y_i-\alpha-\beta x_i)^2}{2\sigma^2}]
:::
取对数获得对数似然函数,并取其关于x_i,y_i的偏导为0,最后我们会发现,对数似然函数最大时当且仅当
::: align-center
\Omega=\sum_i (y_i-\alpha-\beta x_i)^2
:::
最小,于是我们便又回到了最小化\Omega的问题,在统计学上我们通过极大似然估计这个方法架起了线性回归和概率分布之间的桥梁
回归系数的性质
这里不再做过多证明
我们首先研究回归系数的期望和方差,对最小二乘法估计出的\hat{\beta}(或\omega)取期望,容易证明求得的\hat{\beta}是实际模型中\beta的无偏估计
::: align-center
E(\hat{\beta})=\beta
:::
\hat{\alpha}亦同
\hat{\beta}的方差可以求得为
::: align-center
Var(\hat{\beta})=\frac{\sigma^2}{S_{XX}}
:::
类似的,\hat{\alpha}的方差可求得为
::: align-center
Var(\hat{\alpha})=\frac{\sigma^2}{S_{XX}}\bar{x}^2
:::
其中\sigma^2就是我们设出的误差\epsilon的方差,可以证明其无偏估计是
::: align-center
\hat{\sigma^2}=\frac{SSE}{n-2}
:::
其中
::: aliign-center
SSE=\sum_{i}(\hat{y}_i-y_i)^2=SST-SSSR=\sum_i(y_i-\bar{y})^2-\sum_i(\hat{y}_i-\bar{y})^2
:::
因为\hat{y_i}=\hat{\alpha}+\hat{\beta}x=\bar{y}+\hat{\beta}(x_i-\bar{x}),所以又有
::: align-center
SSE=S_{YY}-\hat{\beta}^2S_{XX}
:::
拟合效果分析
本处介绍几种分析拟合效果的方法
几个指标
首先是相关系数\rho_{XY}或r
::: align-center
r=\frac{S_{XY}}{\sqrt{S_{XX}S_{YY}}}=\frac{\sum_i (X_i-\bar{X})(Y_i-\bar{Y})}{\sqrt{\sum_i(X_i-\bar{X})^2\sum_i(Y_i-\bar{Y})^2}}=\frac{n\sum_i X_iY_i-\sum_i X_i\sum_iY_i}{\sqrt{n\sum_i X_i^2-(\sum_iX_i)^2}\sqrt{n\sum_i Y_i^2-(\sum_iY_i)^2}}
:::
其值属于[-1,1],反映自因变量之间的线性相关性关系,绝对值越接近1线性关系越强
其次是决定系数(通常也叫做R方)
::: align-center
R^2=\frac{SSR}{SST}=1-\frac{SSE}{SST}
:::
其中SSR是回归平方和:SSR=\sum(\hat{y_i}-\bar{y})^2
SSE是残差平方和SSE=\sum(\hat{y}_i-y_i)^2
SST是总平方和:SST=\sum(y_i-\bar{y})^2
其值属于[0,1],反映模型的拟合优度(对Y变化的解释程度),越接近1越好
回归系数的Wald检验
下面的\beta即\omega
原假设:H_0:\beta=0(即X对Y无影响)
备择假设:H_{\alpha}:\beta\ne 0(即X对Y有影响)
统计检验量:t=\frac{\beta}{SE(\beta)}(t分布,自由度为n-2)
其中\beta的标准误为:SE(\beta)=\sqrt{\frac{\hat{\sigma}^2}{S_{XX}}}
方差的估计为:\hat{\sigma}^2=\frac{SSE}{n-2}
代入\beta=\frac{S_{XY}}{S_{XX}}可得t=\frac{S_{XY}}{\sqrt{\hat{\sigma}^2S_{XX}}}
\hat{\beta}置信区间的计算方式类似,使用上方的标准误计算即可
预测值的假设检验
同样地我们可以研究\hat{y}(通过线性模型预测的,理论上在取到某个点x_i时因变量的均值,也就是拟合出来的线性模型中,当x=x_i时在直线上的对应点)和\hat{y}_i(实际上在我们模型假设下可能会实际观测到的点)是否符合我们的要求
首先是\hat{y},假设其符合N(?,Var(\hat{y})),对其做假设检验,因为我们通过最小二乘法估计得到的模型为\hat{y}=\hat{\alpha}+\hat{\beta}x=\bar{y}+\hat{\beta}(x-\bar{x}),由方差的线性性可以得到
::: align-center
Var(\hat{y})=Var(\bar{y})+(x-\bar{x})^2Var(\hat{\beta})+2Cov(\bar{y},\hat{\beta}(x-\bar{x}))
:::
可以证明最后一项的协方差为0,于是有
::: align-center
Var(\hat{y})=\frac{\sigma^2}{n}+(x-\bar{x})^2\frac{\sigma^2}{S_{XX}}
:::
将\sigma^2用其无偏估计\hat{\sigma}^2代替,我们便可以用其计算SE,然后做假设检验/置信区间估计了
而对于实际上的观测值值\hat{y}_i,由于误差项\epsilon_i(方差我们假设为\sigma^2)的影响,它会偏离我们的理论拟合点\hat{y},它的方差经推导为
::: align-center
Var(\hat{y}_i|x=x_i)=\frac{\sigma^2}{n}+(x-\bar{x})^2\frac{\sigma^2}{S_{XX}}+\sigma^2
:::
同样可以由他计算SE并做假设检验/CI
多元线性回归
模型
也就是上面的更一般模型,为
::: align-center
f(\mathbf{x})=\mathbf{x\omega}
:::
其中
\omega=\begin{bmatrix}
\omega_1\\
\omega_2\\
\vdots\\
\omega_n\\
\omega_0
\end{bmatrix},\mathbf{x}=\begin{bmatrix}
\mathbf{x_1}^T & 1\\
\mathbf{x_2}^T & 1\\
\vdots & \vdots\\
\mathbf{x_n}^T & 1
\end{bmatrix}
注意此时我们的\mathbf{x}已经不再是一个向量,而是多个向量转置为行向量形成的矩阵
\mathbf{x}的最后全1偏置列用于保证获得\omega_0,即一元线性回归中的常数项b
策略
我们同样最小化MSE,此时需要将其写成内积
::: align-center
\begin{aligned}&\mathbf{\omega^*}=\arg\min(\mathbf{y-x\omega})^T(\mathbf{y-x\omega})\\
&E_w=(\mathbf{y-x\omega})^T(\mathbf{y-x\omega})
\end{aligned}
:::
通过矩阵微分得到
::: align-center
\frac{\partial E_w}{\partial \mathbf{\omega}}=2\mathbf{x}^T(\mathbf{x}\omega-\mathbf{y})
:::
使用OLS我们同样可以通过正规方程获得\omega
::: align-center
\hat{\omega}=(X^TX)^{-1}X^TY
:::
结果是一个列向量,从每一行读出对应的\omega_i(或\beta_i)即可
统计学上,依然可以得到\hat{\beta_i}无偏性,且其方差为Var(\beta_i)=\sigma^2((X^TX)^{-1})_{ii}
其中\sigma^2是我们假设的\epsilon_i的方差,后方的(X^TX)^{-1}取其对角线上的值(其他值不是我们需要的,它们与协方差有关)
将\sigma^2用其无偏估计\hat{\sigma}^2代替即可获得Var(\hat{\beta}_i),现在的\hat{\sigma}^2为
::: align-center
\hat{\sigma}^2=\frac{SSE}{n-k-1}
:::
其中k是不带偏置项的回归系数的数量(参考一元线性回归时分母为2),SSE此时可以由
::: align-center
SSE=Y^TY-\hat{\beta}^TX^TY
:::
获得,这与我们在一元线性回归里见到的SSE=S_{YY}-\hat{\beta}^2S_{XX}类似(最后出现X^TY而不是X^TX是因为正规方程给出了X^TX\beta=X^TY,在推导时简化二次型时将其简化为了带X^TY的形式)
之后便可以使用其计算SE,并做假设检验/CI,注意自由度此时为df=n-k-1
算法
在上面微分中\mathbf{x}满秩的情况下可得到解析解,这里不多叙述,但在其不满秩时获得的解析解会有多个,且计算量非常大
- 针对计算量较大的问题:可用梯度下降法
- 针对多个解的问题,我们在这些解中进一步找出较优的,同时为对抗过拟合问题:可用正则化
梯度下降算法
首先我们回顾在多元函数中梯度\mathbf{grad}f=\nabla f(其中\nabla为Nabla算子)这个向量总是指向变化率最大的方向
若我们随机选取多元函数f(x)上的某一点,若它的梯度为某个向量,则我们按照梯度的反方向更新这个点,在我们更新步长得当的基础下我们最终就会达到局部最小值点的附近或到达最小值点
故我们可设此多元函数为J(\theta_1,\theta_2,\cdots,\theta_n),选取点(\theta_{p1},\theta_{p2},\cdots,\theta_{pn})则它的梯度为向量
::: align-center
\mathbf{grad}J=(\frac{\partial J}{\partial\theta_1},\frac{\partial J}{\theta_2},\cdots,\frac{\partial J}{\partial\theta_n})|_{(\theta_{p1},\theta_{p2},\cdots,\theta_{pn})}
:::
此向量的反方向即为变化率最大(但是是函数值减小方向)的方向,如此我们可以使用此向量的负向量的各个分量\times某个步长a来不断更新(\theta_{p1},\theta_{p2},\cdots,\theta_{pn}),经过有限次迭代后我们就会接近或到达局部最低点
::: align-center
\begin{aligned}
\widetilde{\theta_{p_i}}=\theta_{p_i}-a\frac{\partial J}{\partial \theta_i}
\end{aligned}
:::
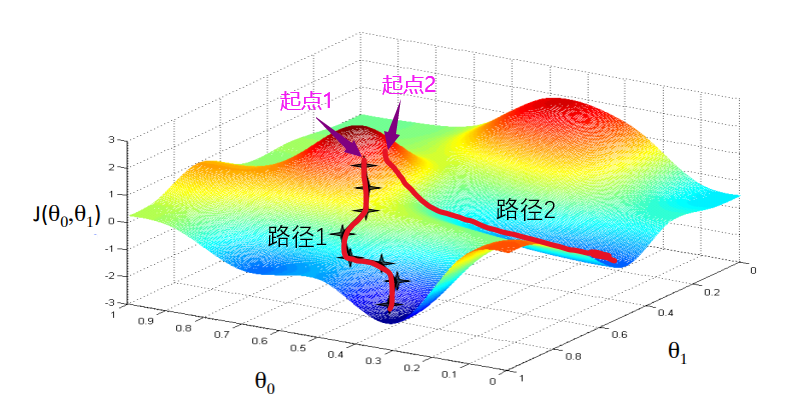
这种可迭代方法对于计算机非常友好,但与此同时它又是有缺陷的,那就是在函数的凹凸性不能保证时,它到达的终究是局部最值点,用上图的例子,它只能保证到“坑”里,但它不能保证你到最深的“坑”里,如果在函数的凹凸性不能得到保证的前提下依然采用此方法,并想要到尽可能达全局最值点,可能需要考虑一些其他的方法,比如给点加一些轻微的扰动让其掉到其他可能更深的“坑”中。
此外迭代步长的选择也非常的重要,太小计算量太大,太大则我们不能保证最后和最值点足够接近,这里不再做过多叙述
正则化
正则化在第一篇文章已经提到,目前正则化的方法主要有两种
L2正则化(岭回归)
即在损失函数中加入\omega的L2范数,即
::: align-center
L_2=\lambda\sum_\omega\omega^2
:::
此时的算法就变成了在L约束下求最小值的问题
这里我们假设\omega为二维向量
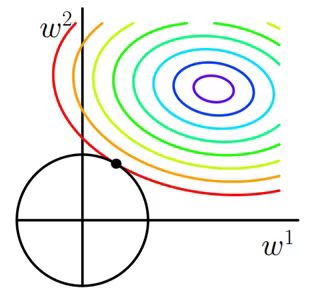
用梯度下降法+岭回归求\omega时,在几何上即寻找彩色等值线与黑色圆的交点,注意到这个交点很难出现在坐标轴上,那么它就达到了\omega内部变量的相对平衡
但在数据维度较高,且线性关系稀疏时,使用岭回归就不太合适
L1正则化(Lasso回归)
在损失函数中加入\omega的L1范数
::: align-center
L_1=\lambda\sum_\omega|\omega|
:::
它和L2正则化的区别在于罚项的不同,这种正则化可以使得一些特征的系数变小,甚至使一些绝对值较小的系数直接变为0,从而增强模型的泛化能力,对于高维且线性关系稀疏的数据L1正则化表现更好
ElaticNet回归
L1回归优点也是它的缺点:它会将一些特征稀疏为0
此方法综合了L1和L2回归,在两种回归效果均不好时可使用此方法
此方法的公式为
::: align-center
\min(\frac{1}{2m}[\sum_{i=1}^m(y_i'-y_i)^2+L_1]+L_2)
:::
对数回归
读到此时读者应该已经发现我们的问题都在针对回归问题,粗略说即给定一个数据,输出预测数据,但如果我们想要进行分类操作呢?
::: align-center
也就是说我们给定数据,输出的不再是预测数据,而是一个类别
:::
对于线性回归,这就需要我们建立线性预测数据与“类别”之间的关系,对数回归问题考虑的就是最简单的二分类问题
我们考虑将数据最终分为两类“1”和“0”,如果出现了“0.5”则可将其分为两类中的任一类,如此我们便可以建立预测值z与“类”y之间的关系
::: align-center
y=\left\{ \begin{matrix}
0 & z<0\\
0.5 & z=0\\
1 & z>0
\end{matrix}\right .
:::
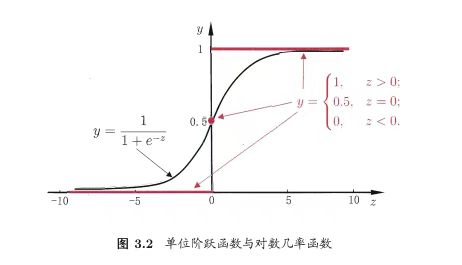
一种建模是y=\frac{1}{1+e^{-z}},我们管它叫做“对数几率函数”,它是一种“Sigmoid函数”,即把预测值转化为一个接近0或1的值,并在z=0附近变化很陡
对其取反函数我们便得到了
::: align-center
\ln(\frac{y}{1-y})=z
:::
若将y视为样本z作为正例的可能性,则1-y为其反例的可能性,二者的比值称作几率(odds),而对几率取对数则会得到对数几率(log odds,也称logit)
分位回归 QR
简介
分位回归是一种比传统均值回归(见上)在极端情况下更“有用”的工具,传统的OLS只能拟合数据均值,而QR能让我们看清数据在各个角落的分布情况。举个例子,假如你开了一家奶茶店,想预测气温对冰红茶销量的影响,传统回归告诉我们“气温x每升高1度平均可多卖\beta_1杯”,但如果某一天气温是极端高温,那这个模型可能就失效了。而QR可以告诉我们“在最冷的那a%的日子里,气温每升高1度会多卖几杯(可能最多2杯),或在气温最热的那b%的日子里,气温每升高1度会多卖几杯(可能猛增20杯)”
QR的模型和OLS的模型假设是一致的,它们都属于线性模型
策略(损失)
QR与OLS最大的不同是,它的损失不再是MSE,而是非对称绝对值损失(Absolute Deviations),又称为弹球损失(Pinball loss),或检验函数(Check function),它与MSE最大的不同在于对预测值估高了和估低了的惩罚是不平等的
它的损失函数为:
::: align-center
\rho_{\tau}(u)=u(\tau-I(u<0))
:::
其中I是指示函数,u是残差y-\hat{y},\tau是分位比。将其展开,结果是一个分段函数:
::: align-center
\left\{\begin{matrix}u\tau & u\ge 0\\u(1-\tau)&u\le 0\end{matrix}\right .
:::
- 对于高分位回归(比如\tau=0.9),如果估低了(残差u>0),此时的惩罚是0.9u,相对较重,如果估高了(残差u<0),此时的惩罚是0.1u,相对较轻。所以高分位回归惩罚低估计
- 对于低分位回归(比如\tau=0.1),如果估高了(残差u<0),此时的惩罚是0.9u,相对较重,而如果估低了(残差u>0),此时的惩罚是0.1u,相对较轻。所以低分位回归惩罚高估计
- u>0\rightarrow“估低了”,u<0\rightarrow“估高了”
所以QR的损失函数更鼓励极端情况下的拟合保持,这使得它针对左/右尾回归时往往效果比OLS要好
| 回归类型 | 均值回归(OLS) | 分位回归(QR) |
|---|---|---|
| 损失 | \arg\min_{\beta}\sum(y_i-\beta^Tx_i)^2 | \arg\min_{\beta}\sum\rho_{\tau}(y_i-\beta^Tx_i) |
| 目的 | 找到一组\beta,让所有样本的预测误差的平方和最小 | 找到一组\beta,让所有样本的加权绝对误差和最小 |
| 偏见 | 均等 | 鼓励“底层”(\tau<0.5)/ 鼓励顶层(\tau> 0.5),特别地,|u|/2(\tau=0.5) |
| 对异常值 | 敏感(容易被极端值拉偏) | 鲁棒(不受极端值影响太大) |
广义线性模型 GLM
阅读完上面的内容后,想必读者已经意识到我们的线性回归问题可以转化为其他问题,只要我们可以找到线性回归问题和我们问题之间的关系,基于此,广义线性模型应运而生,而刚才的logit函数,在广义线性模型框架下属于链接函数(Linking Function) 的一种
我们不再多介绍GLM的具体框架内容,只简单的给大家一些链接函数
| 链接函数 | 公式 | 适用 | 示例模型 |
|---|---|---|---|
| 恒等链接 | g(\mu)=\mu | 连续型数据(如正态分布) | 线性回归 |
| Logit链接 | g(\mu)=\ln\frac{\mu}{1-\mu} | 二分类问题、Beta回归问题 | 逻辑斯蒂回归、Beta回归 |
| Log链接 | g(\mu)=\ln(\mu) | 计数问题(泊松分布)或生存时间(Gamma分布) | 泊松回归、Cox回归 |
| 逆链接 | g(\mu)=\frac{1}{\mu} | 正数连续数据(Gamma分布) | Gamma回归 |
广义回归
思维
在学习了简单线性模型到GLM之后,我们对于回归问题应该有了一个新的认识:
- 开始自变量和因变量之间只是显式的线性关系,此时不需要进行任何变换即可直接列出线性方程,通过解析方法求偏导获得参数的闭式解
- 后来我们意识到自变量可能有一些“取值要求”(比如自变量有范围约束,必须在0到1之间,在比例回归中常用)
- 再后来我们意识到只采用最基本的线性模型可能很难拟合自变量与因变量之间的关系了,于是我们开始寻找一些函数:这些函数应被广泛研究,它们的参数应可以调控函数的基本形状,我们开始通过回归这些非线性函数的参数,使得经由这些函数的“链接”,对于我们的一个自变量样本点,经由这个非线性函数的映射后能尽可能的逼近我们的因变量样本点。特别地,有这样一类“被广泛研究的非线性函数”就是概率密度函数(PDF),而对应地,若我们研究关于它们的参数的回归问题,我们便进入了概率统计中的参数估计领域,对于PDF而言,此时极大似然估计等方法此时可用。我们的回归问题开始与概率统计这个领域之间建立联系
简单来讲,这个思维是:
::: align-center
“取值要求”确定的情况下,可以使用“链接”函数对齐取值空间,简化问题
:::
以Beta回归作为例子:
- 最开始人们发现Beta函数的定义域为[0,1],Beta函数有两个参数\alpha和\beta,可以调控其“形状”
- 后来统计领域学者通过构造归一化建立了Beta分布,Beta分布PDF的定义域依然在(0,1)
- 社会面产生了回归比例的需求,例如给定我们各地的天气情况、温度湿度,要求给出明天下雨的概率(也在0到1之间),而这显然不是线性模型可以解决的
- 部分学者开始意识到,若将“明天下雨的概率”这个概率/比例空间映射到Beta函数的定义域,由于二者的“取值要求”是相同的,Beta函数不需要像其他函数一样“进行修改”就可以完美胜任这个任务
- 直接通过解析方法几乎无法得到Beta函数参数的闭式解,但概率统计的知识进一步启发我们,将“Beta函数的参数求解”这个数学分析领域的问题,变为“Beta分布PDF的参数估计”这个数理统计领域的问题,有费希尔等人创立的极大似然估计等工具可以为我们“保驾护航”
- 但进一步我们发现,即使使用极大似然估计来估计Beta分布的参数,其运算过程依然十分困难,且参数的实际可解释性往往很差
- 但是,“取值要求确定情况下可以使用链接函数简化”的思想再一次提醒我们,若我们尝试对Beta分布的参数进行一定程度的变换,使得构造出的新参数“取值要求”唯一确定,我们便可以再次使用链接函数的思想简化计算
- 2004年,一些学者找到了这个变换,使得经过变换后的新Beta分布的参数\mu,\phi中,\mu的范围一定在(0,1),\phi的范围一定在(0,\infty),此时广义线性模型的相关研究已经非常成熟,学者们发现只需要使用logit链接(logit函数的定义域为(0,1),值域为正负无穷)和ln链接(\ln函数的定义域为(0,\infty),值域为正负无穷),便可以将新参数\mu,\phi的取值空间“对齐”到传统线性模型的取值空间(值域也为正负无穷,定义域取决于样本)
- 于是,Beta回归成熟了,其被广泛用于较为简单的比例回归问题
简单练习

解:
(1)略
(2)这是一个一元线性回归问题,设方程为
::: align-center
y=\omega x+b
:::
当最小化均方误差时,我们的参数可由解析方法求得为:
::: align-center
\begin{aligned}
&\omega=\frac{\sum_{i=i}^{m}y_i(x_i-\overline{x})}{\sum_{i=1}^{m}x_i^2-\frac{1}{m}(\sum_{i=1}^mx_i)^2}\\
&b=\frac{1}{m}\sum_{i=1}^m(y_i-\omega x_i)
\end{aligned}
:::
带入数据得\omega=0.7,b=0.35
故y关于x的线性回归方程为
::: align-center
y=0.7x+0.35
:::
(3)
带入x=100到(2)中的方程,得y=70.35吨,则节省100-70.35=19.65吨煤
全部评论 (0)
暂无评论,快来抢沙发吧~