前言
参考:
- 《统计学习》—李航(蓝皮)
- 部分来自网络的内容(主要是liaohuiqiang的博客)
感知机
模型
基本模型:感知机1957年由Rosenblatt提出,是神经网络与SVM的基础。它是一个二分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取+1和-1二值。
假设向量\mathbf{x}是我们的数据向量,\mathbf{y}是标签向量,学习器为
::: align-center
f(\mathbf{x})=sign(\mathbf{\omega}^T\mathbf{x}+\mathbf{b})
:::
其中sign(x)是符号函数,为
::: align-center
sign(x)=\left\{\begin{matrix}1 & x\ge 0\\-1 & x<0\end{matrix}\right .
:::
线性方程\mathbf{\omega x + b}=0对应于特征空间\mathbb{R}^n中的一个超平面S,其中\omega是超平面的法向量,\mathbf{b}是超平面的截距。超平面将特征空间划分为两个部分。位于两个部分的点(特征向量)分别被分为正负两类。
- \mathbf{\omega}^T\mathbf{x}+\mathbf{b}>0的点被认为是正类点,此时符号函数返回+1
- \mathbf{\omega}^T\mathbf{x}+\mathbf{b}<0的点被认为是负类点,此时符号函数返回-1
优缺点为:
- 优点:简单,容易实现
- 缺点:假设了线性可分,且无法解决最基本的异或问题
策略(一元)
损失函数的一个自然选择是误分类点的总数,但是这样的损失函数不是参数\omega,b的连续可导函数,不易优化。损失函数的另一个选择是误分类点到超平面S的总距离,这是感知机所采用的。
点到超平面的距离
::: align-center
\frac{1}{||\omega||}|\omega x+b|
:::
其中||\omega||为L2范数
误分类点到超平面的距离
因为误分类点总有(\omega x_i+b)y_i\le0,故对于误分类点组成的集合M,其中的点到超平面的距离为
::: align-center
-\frac{1}{||\omega||}\sum_{x_i\in M}y_i(\omega x_i+b)
:::
损失函数
去掉\frac{1}{||\omega||}并不影响优化结果,故损失函数为
::: align-center
L(\omega,b)=-\sum_{x_i\in M}y_i(\omega x_i+b)
:::
此时\mathbf{x_i}为一元数据向量,对于多元情况,要将所有\mathbf{x_i,y_i}写为一个矩阵加全1偏置列,同时将\mathbf{b}收进\omega变为\mathbf{\omega_0}则也有
::: align-center
L(\mathbf{\omega})=-\mathbf{y}^T(\mathbf{x\omega})
:::
算法(一元)
感知机的原始算法
采用随机梯度下降算法,求解最优化问题
::: align-center
\min_{\omega,\mathbf{b}}L(\omega,b)
:::
迭代获得\omega,\mathbf{b}的最优解
::: align-center
\begin{aligned}
(\omega^{k+1},b^{k+1})&=(\omega^{k},b^k)-\lambda_k(\nabla L(\omega,b)|_{(x_i,y_i)\in M})\\
&=(\omega^{k}, b^k)+\lambda_k(x_iy_i,y_i)
\end{aligned}
:::
其中初始的x_i,y_i通常随机选取错误分类点(x_i,y_i) \in M
注:全局梯度下降法需要不断计算全局\nabla L,而随机梯度下降法只挑选符合条件(这里是错误分类点)的\nabla L(\omega,b)|_{(x_i,y_i)\in M},随机梯度下降法在简化了计算的同时,也造成了解的不唯一问题,同时不同解的好坏无法评判
\omega,b通常采用常规初始化初始化为全0
停止条件为
::: align-center
y_i(\omega x_i+b)\left\{\begin{matrix}end & >0\\continue & \le0\end{matrix}\right .(对任意x)
:::
感知机算法的对偶形式
在原始的感知机算法中,设\omega,b修改了n次,则\omega,b关于(x_i,y_i)全部增量分别是a_ix_iy_i和a_iy_i,其中a_i=n\lambda_k,a_i表示第i个实例点因误分类而进行更新的次数,\lambda_k是当前的学习率
在\omega,b由常规初始化初始化为全0时,最后学习到的模型可表示为
::: align-center
f(x)=sign(\sum_{i=1}^{N}a_iy_ix_i\cdot x+b)
:::
其中b=\sum_{i=1}^Na_iy_i
迭代过程变为
::: align-center
(a^{k+1},b^{k+1})=(a^k,b^k)+(\lambda_k,\lambda_k y_i)
:::
判断条件变为
::: align-center
y_i(\sum_{i=1}^{N}a_iy_ix_i\cdot x+b)\left\{\begin{matrix}end & >0\\continue & \le0\end{matrix}\right .(对任意x)
:::
因为x_i\cdot x总有定值,故可将其事先计算出来以矩阵的形式存储,以空间换时间提高计算效率,这个矩阵就是所谓的Gram矩阵
::: align-center
G=[x_i\cdot x_j]_{N\times N}
:::
简单练习
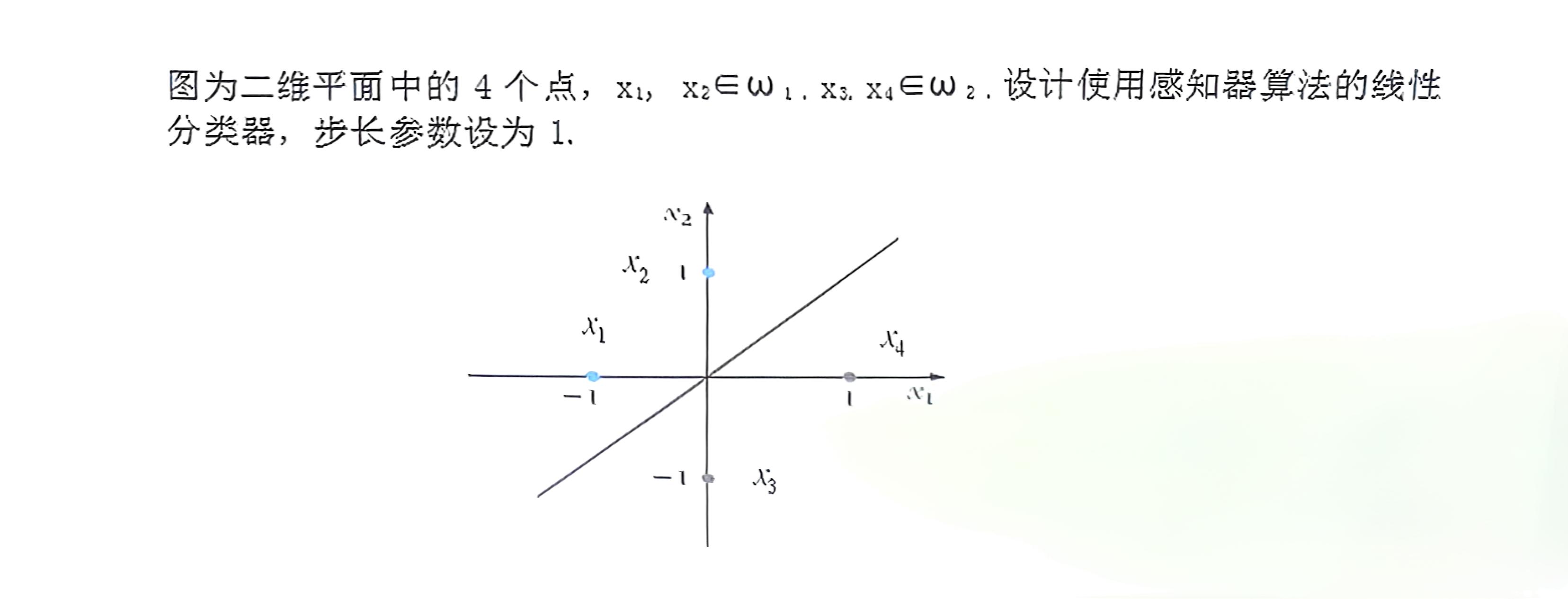
注:蓝色为正例,灰色为反例
解:
首先设感知机分离超平面为
::: align-center
y=\omega^T\mathbf{x}+b
:::
其中\omega=\begin{bmatrix}\omega_1\\\omega_2\end{bmatrix},b\in \mathbb{R}
(或者增广特征向量形式,这里我们设为保留截距的形式)
最小化点到分离超平面的距离,选择随机梯度下降法,我们的迭代公式为
::: align-center
\begin{aligned}
(\omega^{k+1},b^{k+1})&=(\omega^{k},b^k)-\lambda_k(\nabla L(\omega,b)|_{(x_i,y_i)\in M})\\
&=(\omega^{k}, b^k)+\lambda_k(x_iy_i,y_i)
\end{aligned}
:::
其中\lambda_k=1
迭代判断条件为
::: align-center
y_i(\omega x_i+b)\left\{\begin{matrix}end & >0\\continue & \le0\end{matrix}\right .(对任意x)
:::
现初始化\omega=\begin{bmatrix}0\\0\end{bmatrix},b=0
开始迭代(注意以下迭代过程为示例,实际上由于随机梯度下降算法的多解性读者得到的解可能与下方不同,但只要满足停止条件即可)
- 迭代所有样本:
-
x_1: ( y_1(\omega \cdot x_1 + b) = (+1)(0 \cdot (-1) + 0 \cdot 0 + 0) = 0 \leq 0 ) → 误分类
- 更新:
\omega := [0, 0] + 1 \cdot (+1) \cdot (-1, 0) = [-1, 0], \quad b := 0 + 1 \cdot (+1) = 1
- 更新:
-
更新后参数:\omega = [-1, 0]^T, b = 1
- 重新检查所有样本:
- x_1:(+1)(-1 \cdot (-1) + 0 \cdot 0 + 1) = (+1)(1 + 1) = 2 > 0 → 正确
- x_2:(+1)(-1 \cdot 0 + 0 \cdot 1 + 1) = (+1)(1) = 1 > 0 → 正确
- x_3:(-1)(-1 \cdot 0 + 0 \cdot (-1) + 1) = (-1)(1) = -1 \leq 0 → 误分类
- 更新: \omega := [-1, 0]^T + 1 \cdot (-1) \cdot [0, -1]^T = [-1, 1]^T, \quad b := 1 + 1 \cdot (-1) = 0
- 更新后参数:\omega = [-1, 1]^T, b = 0
- 再次检查所有样本:
- x_1:(+1)(-1 \cdot (-1) + 1 \cdot 0 + 0) = 1 > 0 → 正确
- x_2:(+1)(-1 \cdot 0 + 1 \cdot 1 + 0) = 1 > 0 → 正确
- x_3:(-1)(-1 \cdot 0 + 1 \cdot (-1) + 0) = (-1)(-1) = 1 > 0 → 正确
- x_4:(-1)(-1 \cdot 1 + 1 \cdot 0 + 0) = (-1)(-1) = 1 > 0 → 正确
所有样本已正确分类,停止迭代。
最终分类超平面方程为
::: align-center
y=\omega^T\mathbf{x}+b=-x_1+x_2
:::
感知机模型为
::: align-center
f(\mathbf{x})=sign(\omega^T\mathbf{x}+b)=sign(-x_1+x_2)
:::
全部评论 (0)
暂无评论,快来抢沙发吧~