前言
参考:
- 《统计学习》—李航(蓝皮)
- 部分来自网络的内容(主要是liaohuiqiang的博客)
朴素贝叶斯
简介
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练数据集,首先基于“特征条件独立”的假设学习输入/输出的联合概率分布。然后基于此模型,对给定输入x,利用贝叶斯定理求后验概率最大的y。
朴素贝叶斯实现简单,学习与预测的效率都很高,是一种常用的方法。
基本方法
基本方法:朴素贝叶斯方法通过训练数据集学习联合概率分布P(X,Y)。具体地,学习以下先验概率分布及条件概率分布,从而学习到联合概率分布。
先验概率分布
::: align-center
P(Y=c_k),k=1,2,\cdots,K
:::
条件概率分布
::: align-center
P=(\mathbf{X}=\mathbf{x}|Y=c_k)=P(\mathbf{X}=(x^{(1)},x^{(2)},\cdots,x^{(n)})|Y=c_k)
:::
属性变量独立性假设:朴素贝叶斯假设“用于分类的特征在类确定的条件下是条件独立的”。这是一个较强的假设,它使得算法变得简单(因此称为朴素),但有时会牺牲一定的分类准确率。
在此独立假设下
::: align-center
P=(\mathbf{X}=\mathbf{x}|Y=c_k)=\prod_{j=1}^{n}P(X^{(j)}=x^{(j)}|Y=c_k)
:::
朴素贝叶斯分类
贝叶斯公式
首先回顾贝叶斯公式
::: align-center
P(Y|X)=\frac{P(Y)P(X|Y)}{P(X)}=\frac{P(Y)P(X|Y)}{\sum_{Y}P(Y)P(X|Y)}
:::
朴素贝叶斯分类
分类时,对给定的输入\mathbf{x},通过学习到的模型计算后验概率分布P(Y=c_k|\mathbf{X=x}),将后验概率最大的类作为\mathbf{x}的类输出。
于是朴素贝叶斯分类器可表示为
::: align-center
y=f(\mathbf{x})=\arg\max_{c_k}P(Y=c_k|\mathbf{X=x})
:::
在使用贝叶斯公式计算P(Y=c_k|\mathbf{X=x})时,由于分母对于所有c_k均相同,故其并不影响求最大值,可去掉,又由“朴素”的概念,最终有
::: align-center
y=\arg\max_{c_k}P(Y=c_k)\prod_{j}P(X^{(j)}=x^{(j)}|Y=c_k)
:::
极大似然估计
简介
最大似然估计(Maximum Likelihood Estimation)是一种可以生成拟合数据的任何分布的参数的最可能估计的技术。它是一种解决建模和统计中常见问题的方法——将概率分布拟合到数据集,由高斯最先提出,费希尔逐步完善。
MLE之所以有效,是因为它将寻找数据分布的参数视为一个优化问题。通过最大化似然函数,找到了最可能的解。
似然函数是衡量样本成为观察到数据的概率。如果样本有n个独立同分布的(iid)随机变量,X_1至X_n,与观察到的数据x_1到x_n相关,我们就有似然函数的数学表达式:
::: align-center
lik(\theta)=P(X_1=x_1,\cdots,X_n=x_n)
:::
又由独立同分布的定义得
::: align-center
lik(\theta)=P(X_1=x_1)P(X_2=x_2)\cdots P(X_n=x_n)
:::
最后,如果数据来自的分布具有概率密度/质量函数p(X_i;\theta),那么似然函数表示为
::: align-center
f(x)=\prod_{i=1}^n p(X_i;\theta)
:::
之后通过极大化似然函数,我们可以得到参数\theta的估计,带入后得到的概率分布是“最有可能”使样本发生的分布,就比如“猎人打兔问题”——一枪命中,更可能是枪法准的猎人而非新手,这体现了极大似然估计在估计参数时采用的“最可能”的思想。
极大似然估计在朴素贝叶斯中的应用
在朴素贝叶斯中,学习意味着获得先验概率P(Y=c_k)和P(X^{(j)}=x^{(j)}|Y=c_k)
可使用极大似然估计来估计相应先验概率概率
::: align-center
P(Y=c_k)=\frac{\sum_{i=1}^N I(y_i=c_k)}{N}
:::
设第j个特征可能取值的集合为\{a_{j1},a_{j2},\cdots,a_{S_j}\},则
::: align-center
P(X^{(j)}=a_{jl}|Y=c_k)=\frac{\sum_{i=1}^N I(x^{(j)}=a_{jl},y_i=c_k)}{\sum_{i=1}^N I(y_i=c_k)}
:::
证明:
对于P(Y=c_k),写出它的似然函数为
::: align-center
L(\pi)=\prod_{i=1}^NP(Y=y_i)
:::
引入指示函数I(y_i=c_k)
::: align-center
L(\pi)=\prod_{i=1}^NP(Y=y_i)=\prod_{k=1}^K\pi_k^{\sum_{i=1}^N I(y_i=c_k)}
:::
其中\pi_k=P(Y=c_k),之后求解似然函数的极大化问题,为了计算方便使用对数似然函数
::: align-center
\begin{aligned}
&\max_{\pi}\ln L(\pi)=\max_{\pi}\sum_{k=1}^KN_k\ln\pi_k\\
&s.t.\space \sum_{k=1}^K \pi_k=1
\end{aligned}
:::
其中N_k=\sum_{i=1}^NI(y_i=c_k)
构造拉格朗日函数
::: align-center
\mathcal{L}(\pi,\lambda)=\sum_{k=1}^KN_k\ln\pi_k+\lambda(1-\sum_{k=1}^K\pi_k)
:::
对\pi_k,\lambda求偏导并令其等于零,得
::: align-center
\pi_k=\frac{N_k}{N}=\frac{I(y_i=c_k)}{N}
:::
类似地,对于P(X^{(j)}=x^{(j)}|Y=c_k),构造似然函数
::: align-center
L(\theta)=\prod_{i=1}^NP(X^{(j)}=x_i^{(j)}|Y=c_k)=\prod_{l=1}^{S_j}\theta_{jl}^{\sum_{i=1}^N I(x^{(j)}=a_{jl},y_i=c_k)}
:::
使用类似的方法可求得结果
平滑处理
但极大似然估计可能会出现等于零的情况,此时需要引入平滑处理
::: align-center
P_\lambda(Y=c_k)=\frac{\sum_{i=1}^N I(y_i=c_k)+\lambda}{N+k\lambda}
:::
及
::: align-center
P(X^{(j)}=a_{jl}|Y=c_k)=\frac{\sum_{i=1}^N I(x^{(j)}=a_{jl},y_i=c_k)+\lambda}{\sum_{i=1}^N I(y_i=c_k)+S_j\lambda}
:::
其中\lambda=0时称为极大似然估计,\lambda=1时称为拉普拉斯平滑
简单练习
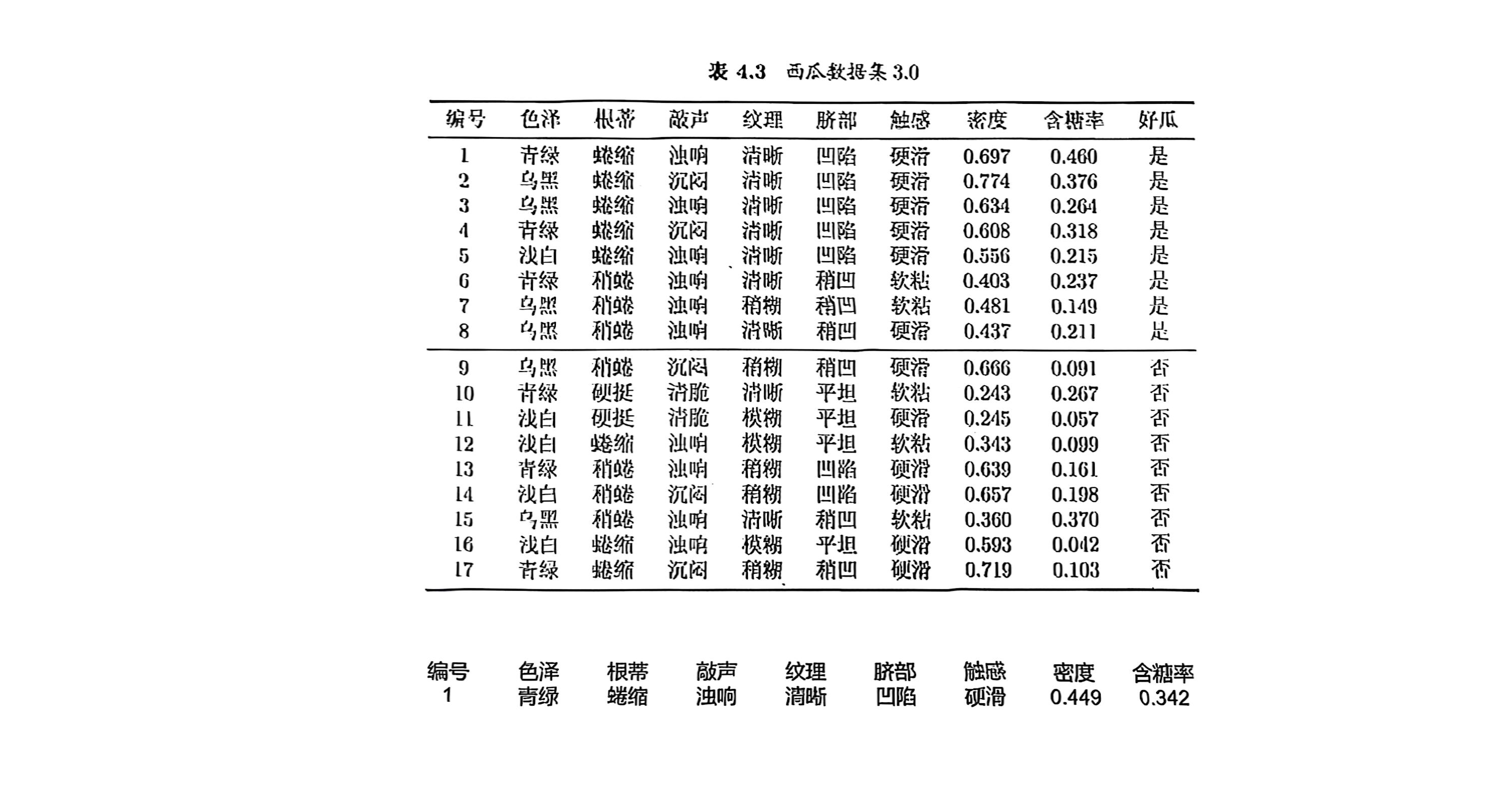
使用朴素贝叶斯预测最下方数据代表的是好瓜还是坏瓜
解:
首选需要离散化密度和含糖率,这里我们使用等宽分箱(根据数值范围均匀划分区间),此外还有等频分箱(使每个区间包含近似相同数量的样本)等其他方法,将密度和含糖率划分为低、中、高三个指标
-
密度 D
- 最小:0.243 最大: 0.774
- 区间宽度:\frac{0.774-0.243}{3}=0.177
- 边界
- 低:D_1 [0.243, 0.42)
- 中:D_2 [0.42, 0.597)
- 高:D_3 [0.597, 0.774]
-
含糖率 E
- 最小:0.091 最大:0.460
- 区间宽度:\frac{0.460-0.091}{3}=0.123
- 边界
- 低:E_1 [0.091, 0.214)
- 中:E_2 [0.214, 0.337)
- 高:E_3 [0.337, 0.460]
另设出以下随机变量:
色泽:C( C_1:青绿 C_2:乌黑 C_3:浅白)
根蒂:R(R_1:蜷缩 R_2:稍蜷 R_3:硬挺)
敲声:S(S_1:浊响 S_2:沉闷 S_3:清脆)
纹理:T(T_1:清晰 T_2:稍糊 T_3:模糊)
脐部:U(U_1:凹陷 U_2:稍凹 U_3:平坦)
触感:I(I_1:硬滑 I_2:软粘)
分类标签为:Y(Y_1:好瓜=是 Y_2:坏瓜=否)
按照给出的预测样本,它属于C_1,R_1,S_1,T_1,U_1,I_1,D_2,E_3
按照朴素贝叶斯分类,我们需要计算来自样本集的先验概率P(X|Y),P(Y)
对于好瓜来说:
P(Y_1)=\frac{8}{17}, P(C_1|Y_1)=\frac{3}{8},P(R_1|Y_1)=\frac{5}{8},P(S_1|Y_1)=\frac{3}{4},P(T_1|Y_1)=\frac{3}{4},P(U_1|Y_1)=\frac{5}{8},P(I_1|Y_1)=\frac{3}{4},P(D_2|Y_1)=\frac{3}{8},P(E_3|Y_1)=\frac{1}{4}
对于坏瓜来说:
P(Y_2)=\frac{9}{17}, P(C_1|Y_2)=\frac{1}{3},P(R_1|Y_1)=\frac{1}{3},P(S_1|Y_1)=\frac{4}{9},P(T_1|Y_1)=\frac{2}{9},P(U_1|Y_2)=\frac{2}{9},P(I_1|Y_1)=\frac{2}{3},P(D_2|Y_1)=\frac{1}{9},P(E_3|Y_1)=\frac{1}{9}
计算后验概率(分子部分)
对于好瓜:\frac{8}{17}\times\frac{3}{8}\times\frac{5}{8}\times\frac{3}{4}\times\frac{3}{4}\times\frac{5}{8}\times\frac{3}{4}\times\frac{3}{8}\times\frac{1}{4}\approx 0.0027
对于坏瓜:\frac{9}{17}\times\frac{1}{3}\times\frac{1}{3}\times\frac{4}{9}\times\frac{2}{9}\times\frac{2}{9}\times\frac{2}{3}\times\frac{1}{9}\times\frac{1}{9}\approx 1.06\times10^{-5}
故此瓜应是好瓜
全部评论 (0)
暂无评论,快来抢沙发吧~