参数估计(概率统计)
前言 参考: 浙大《概率论与数理统计》第5版 高教社《概率论与数理统计》第3版 点估计 设总体$X$的分布函数的形式已知,但它的一个或多个参数未知,借助于总体$X$的一个样本来估计总体未知参数的值
-封面.jpg)
7个月前
1
共 22 个标签
前言 参考: 浙大《概率论与数理统计》第5版 高教社《概率论与数理统计》第3版 点估计 设总体$X$的分布函数的形式已知,但它的一个或多个参数未知,借助于总体$X$的一个样本来估计总体未知参数的值
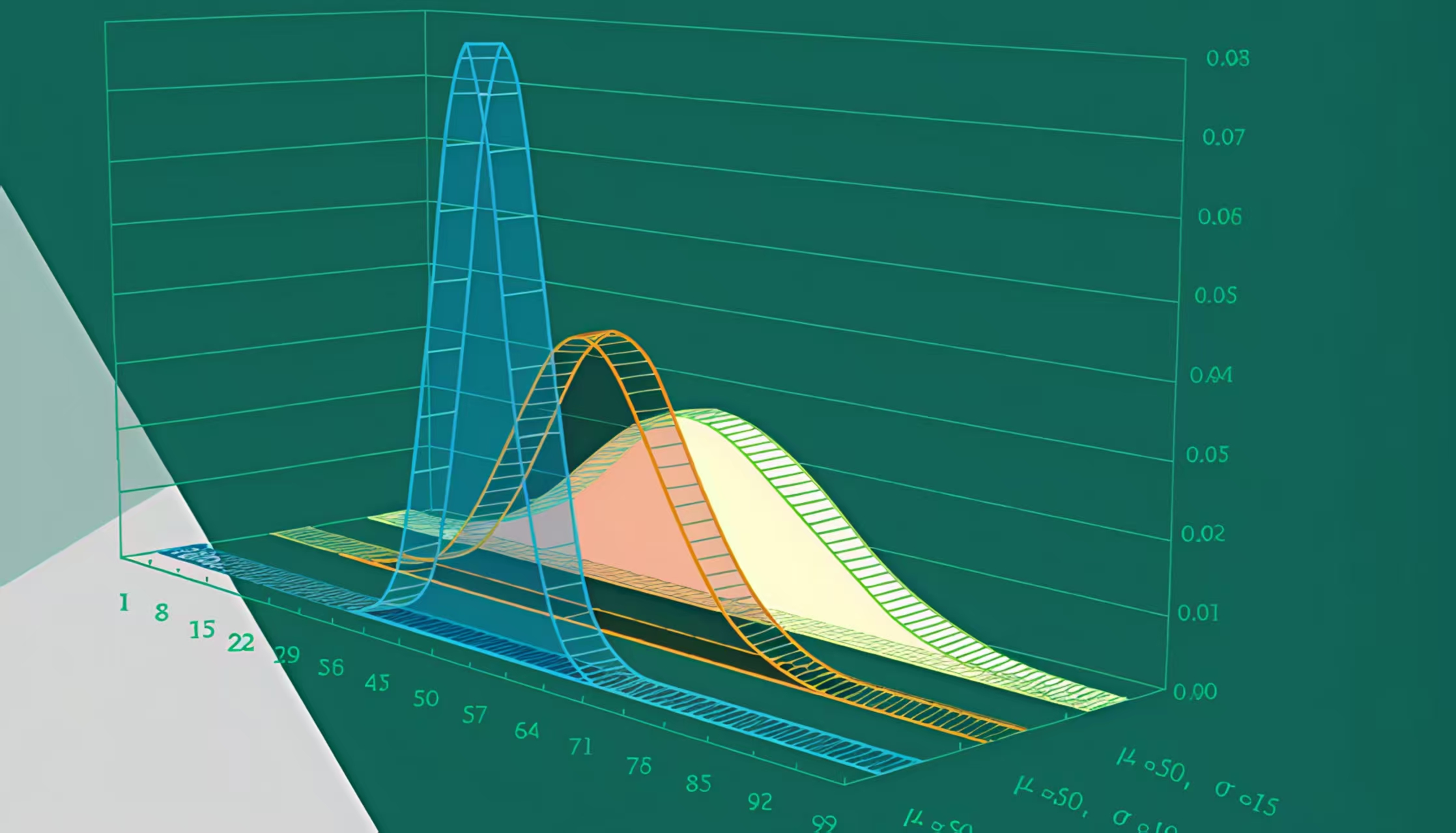
前言 所有$\alpha$分位数均为上分位数,在查表时请注意转换 另外,本文的假设检验主要介绍参数检验方法,非参数检验方法暂时不设计 检验总体均值(单/双独立样本均值检验) 单变量 置信区间 样本数量
前言 在EfficientNet的复现中我们已经提到了SE注意力机制,现在简要介绍18年的CBAM和21年的CA注意力机制 论文: (ECCV'18)CBAM: Convolutional Bloc

前言 在后ResNet时代,EfficientNet作为仅用ResNet 3%的参数就达到其90%性能的存在,值得我们的研究一番 目标:实现EfficientNet的完整架构,包括: Stem: 初

前言 这是笔者在结束科班课程后对此系列笔记的接续更新,此后该系列的笔记主要以论文解析为主,值得注意的是,在之前CNN领域有诸多创新,例如2012年的AlexNet,2014年的VGGNet,2015年
:Transformers Encoder-Decoder架构-封面.jpg)
引言 当神经网络模拟应用到机器学习时,往往会遇到下面两个问题 优化问题 全局最优解困难 训练效率通常比较低 梯度消失/爆炸问题 这导致神经网络的网络优化十分困难 泛化问题 模型复杂度高 拟合能力很强 容易产生过拟合问题 需要通过正则化方法提高泛化能力 网络优化 简介 网络优化指寻找一个神经网络模型来使得经验(或结构)风
:网络优化和正则化-封面.jpg)
(全连接)前馈神经网络 简介 前馈神经网络(Feedforward Neural Network, FNN)作为神经网络的一种,把每个神经元按接收信息的先后分为不同的组,每一组可以看作是一个神经层。每一层的神经元接收前一层神经元的输出,并输出到下一层神经元。整个网络中的信息是朝着一个方向传播的,它可以看作是一个函数,通
:全连接前馈神经网络-封面.jpg)
人工智能的发展过程 人工智能: 机器学习表示学习深度学习 机器学习 通过硬编码的知识体系面对的困难表明,AI系统需要具备自己获取知识的能力,即从原始数据中提取模式的能力,这种能力被称为机器学习。 机器学习算法的性能很大程度上依赖于给定数据的表示,在整个计算机科学乃至日常生活中,对表示的的依赖是一个普遍的现象,表示的选择
:深度学习-封面.jpg)
前言 参考: 《统计学习》—李航(蓝皮) PCA(主成分分析) 简介 主成分分析(Pricipal Component Analysis, PCA)是一种常用的无监督学习方法,这一方法利用正交变换
:PCA-封面.jpg)
前言 参考: 《统计学习》—李航(蓝皮) 无监督学习 无监督学习基本原理 无监督学习是从无标注的数据中学习数据的统计规律或者说内在结构的机器学习,主要包括: 1. 聚类 2. 降维 3. 概率估计 无监督学习可以用于数据分析或者监督学习的前处理 无监督学习使用无标注数据$U=\{x1,x2,\cdots,xN\}$学习
:无监督学习概论-封面.jpg)